Генеративный ИИ вступил в эпоху видео.
Первоисточник: Heart of the Machine
 Источник изображения: Generated by Unbounded AI
Источник изображения: Generated by Unbounded AI
Когда дело доходит до генерации видео, многие, вероятно, в первую очередь думают о Gen-2 и Pika Labs. Но только что Meta объявила, что превзошла их обоих по генерации видео и стала более гибкой в редактировании.

 Эта «труба, танцующий кролик» — последнее демо, выпущенное Meta. Как видите, технология Meta поддерживает как гибкое редактирование изображений (например, превращение «кролика» в «кролика-трубача», а затем в «кролика-трубача радужного цвета»), так и создание видео высокого разрешения из текста и изображений (например, счастливый танец «зайчика-трубы»).
Эта «труба, танцующий кролик» — последнее демо, выпущенное Meta. Как видите, технология Meta поддерживает как гибкое редактирование изображений (например, превращение «кролика» в «кролика-трубача», а затем в «кролика-трубача радужного цвета»), так и создание видео высокого разрешения из текста и изображений (например, счастливый танец «зайчика-трубы»).
На самом деле, здесь есть две вещи.
Гибкое редактирование изображений осуществляется с помощью модели под названием «Emu Edit». Он поддерживает бесплатное редактирование изображений с текстом, включая локальное и глобальное редактирование, удаление и добавление фона, преобразование цвета и геометрии, обнаружение и сегментацию и многое другое. Кроме того, он точно следует инструкциям, гарантируя, что пиксели во входном изображении, не связанные с инструкциями, останутся нетронутыми.
 Одеть страуса в юбку
Одеть страуса в юбку
Видео высокого разрешения генерируется моделью под названием «Emu Video». Emu Video — это модель видео Wensheng, основанная на диффузии, которая способна генерировать 4-секундное видео высокого разрешения 512x512 на основе текста (более длинные видео также обсуждаются в статье). Тщательная оценка на людях показала, что Emu Video получил более высокие баллы как по качеству генерации, так и по точности текста по сравнению с Runway Gen-2 и Pika Labs. Вот как это будет выглядеть:

 В своем официальном блоге Meta предвидела будущее обеих технологий, в том числе позволяя пользователям социальных сетей создавать свои собственные GIF-файлы, мемы и редактировать фотографии и изображения по своему усмотрению. В связи с этим Meta также упомянула об этом, когда выпустила модель Emu на предыдущей конференции Meta Connect (см.: «Версия ChatGPT от Meta здесь: благословение Llama 2, доступ к поиску Bing, живая демонстрация Xiaozha»).
В своем официальном блоге Meta предвидела будущее обеих технологий, в том числе позволяя пользователям социальных сетей создавать свои собственные GIF-файлы, мемы и редактировать фотографии и изображения по своему усмотрению. В связи с этим Meta также упомянула об этом, когда выпустила модель Emu на предыдущей конференции Meta Connect (см.: «Версия ChatGPT от Meta здесь: благословение Llama 2, доступ к поиску Bing, живая демонстрация Xiaozha»).
 Далее мы познакомим вас с каждой из этих двух новых моделей.
Далее мы познакомим вас с каждой из этих двух новых моделей.
ЭмуВидео
Большая графовая модель Вэньшэна обучается на парах изображение-текст веб-масштаба для получения высококачественных и разнообразных изображений. Несмотря на то, что эти модели могут быть дополнительно адаптированы к генерации текста в видео (T2V) за счет использования пар видео-текст, генерация видео все еще отстает от генерации изображений с точки зрения качества и разнообразия. По сравнению с генерацией изображений, генерация видео является более сложной задачей, поскольку требует моделирования более высокого измерения пространственно-временного выходного пространства, которое по-прежнему может быть основано на текстовых подсказках. Кроме того, наборы данных видео-текста, как правило, на порядок меньше, чем наборы данных изображений-текста.
Преобладающим способом генерации видео является использование диффузионной модели для одновременной генерации всех видеокадров. В отличие от этого, в НЛП генерация длинных последовательностей формулируется как авторегрессионная задача: предсказание следующего слова при условии ранее предсказанного слова. В результате условный сигнал последующего предсказания будет постепенно усиливаться. Исследователи предполагают, что усиленное кондиционирование также важно для генерации высококачественного видео, которое само по себе является временным рядом. Однако авторегрессионное декодирование с помощью диффузионных моделей является сложной задачей, так как генерация однокадрового изображения с помощью таких моделей сама по себе требует нескольких итераций.
В результате исследователи Meta предложили EMU VIDEO, который дополняет генерацию текста в видео на основе диффузии явным промежуточным этапом генерации изображения.
 Адрес:
Адрес:
Адрес проекта:
В частности, они разложили видеозадачу Вэньшэна на две подзадачи: (1) создание изображения на основе вводимой текстовой подсказки и (2) создание видео на основе условий подкрепления изображения и текста. Интуитивно понятно, что предоставление модели начального изображения и текста упрощает создание видео, так как модели нужно только предсказать, как изображение будет развиваться в будущем.
 * Исследователи Meta разделили видео Wensheng на два этапа: сначала сгенерировать изображение I с условием текста p, а затем использовать более строгие условия — результирующее изображение и текст — для создания видео v. Чтобы ограничить Model F изображением, они временно сфокусировались на изображении и соединили его с двоичной маской, которая показывает, какие кадры были обнулены, а также с зашумленным входом. *
* Исследователи Meta разделили видео Wensheng на два этапа: сначала сгенерировать изображение I с условием текста p, а затем использовать более строгие условия — результирующее изображение и текст — для создания видео v. Чтобы ограничить Model F изображением, они временно сфокусировались на изображении и соединили его с двоичной маской, которая показывает, какие кадры были обнулены, а также с зашумленным входом. *
Поскольку набор данных «видео-текст» намного меньше, чем набор данных «изображение-текст», исследователи также инициализировали свою модель преобразования текста в видео с помощью предварительно обученной модели текст-изображение (T2I) с замороженным весом. Они определили ключевые проектные решения — изменение графика диффузного шума и многоступенчатое обучение — для непосредственного производства видео с высоким разрешением 512 пикселей.
В отличие от метода генерации видео непосредственно из текста, их метод декомпозиции явно генерирует изображение при выводе, что позволяет легко сохранить визуальное разнообразие, стиль и качество модели диаграммы Вэньшэна (как показано на рисунке 1). ЭТО ПОЗВОЛЯЕТ EMU VIDEO ПРЕВОСХОДИТЬ ПРЯМЫЕ МЕТОДЫ T2V ДАЖЕ ПРИ ТЕХ ЖЕ ОБУЧАЮЩИХ ДАННЫХ, ОБЪЕМЕ ВЫЧИСЛЕНИЙ И ОБУЧАЕМЫХ ПАРАМЕТРАХ.

 Это исследование показывает, что качество генерации видео Wensheng может быть значительно улучшено с помощью многоступенчатого метода обучения. Этот метод поддерживает прямую генерацию видео высокого разрешения с разрешением 512 пикселей без необходимости использования некоторых моделей глубокого каскада, используемых в предыдущем методе.
Это исследование показывает, что качество генерации видео Wensheng может быть значительно улучшено с помощью многоступенчатого метода обучения. Этот метод поддерживает прямую генерацию видео высокого разрешения с разрешением 512 пикселей без необходимости использования некоторых моделей глубокого каскада, используемых в предыдущем методе.

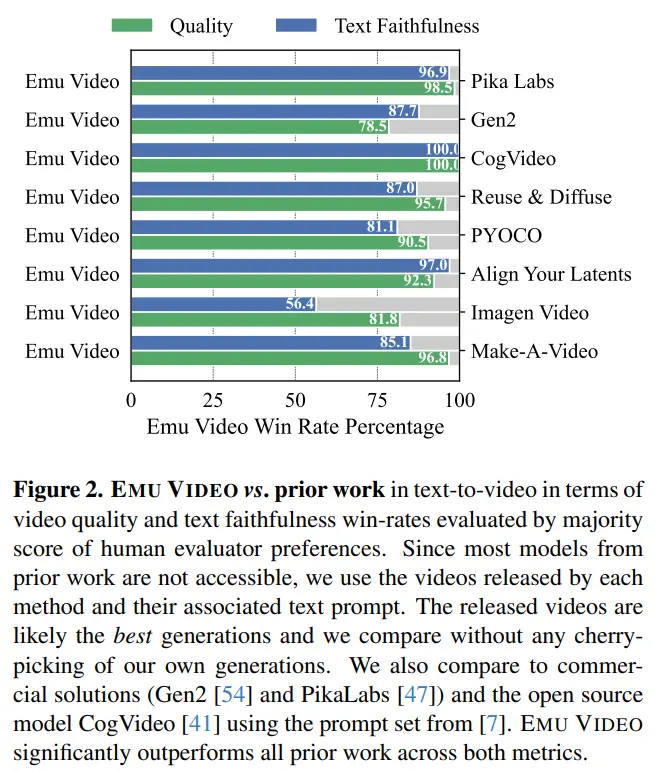
 Исследователи разработали надежный протокол оценки человека, JUICE, в котором оценщиков попросили доказать, что их выбор был правильным при выборе между парами. Как показано на рисунке 2, средний процент побед EMU VIDEO составляет 91,8% и 86,6% с точки зрения качества и точности текста, что намного опережает все предварительные разработки, включая коммерческие решения, такие как Pika, Gen-2 и другие. В ДОПОЛНЕНИЕ К T2V, ВИДЕО EMU ТАКЖЕ МОЖЕТ ИСПОЛЬЗОВАТЬСЯ ДЛЯ ГЕНЕРАЦИИ ИЗОБРАЖЕНИЯ В ВИДЕО, ГДЕ МОДЕЛЬ ГЕНЕРИРУЕТ ВИДЕО НА ОСНОВЕ ПРЕДОСТАВЛЕННЫХ ПОЛЬЗОВАТЕЛЕМ ИЗОБРАЖЕНИЙ И ТЕКСТОВЫХ ПОДСКАЗОК. В этом случае результаты генерации EMU VIDEO на 96% лучше, чем у VideoComposer.
Исследователи разработали надежный протокол оценки человека, JUICE, в котором оценщиков попросили доказать, что их выбор был правильным при выборе между парами. Как показано на рисунке 2, средний процент побед EMU VIDEO составляет 91,8% и 86,6% с точки зрения качества и точности текста, что намного опережает все предварительные разработки, включая коммерческие решения, такие как Pika, Gen-2 и другие. В ДОПОЛНЕНИЕ К T2V, ВИДЕО EMU ТАКЖЕ МОЖЕТ ИСПОЛЬЗОВАТЬСЯ ДЛЯ ГЕНЕРАЦИИ ИЗОБРАЖЕНИЯ В ВИДЕО, ГДЕ МОДЕЛЬ ГЕНЕРИРУЕТ ВИДЕО НА ОСНОВЕ ПРЕДОСТАВЛЕННЫХ ПОЛЬЗОВАТЕЛЕМ ИЗОБРАЖЕНИЙ И ТЕКСТОВЫХ ПОДСКАЗОК. В этом случае результаты генерации EMU VIDEO на 96% лучше, чем у VideoComposer.
 Как видно из показанной демонстрации, EMU VIDEO уже может поддерживать 4-секундную генерацию видео. В статье они также исследуют способы увеличения длины видео. Авторы говорят, что с помощью небольшой архитектурной модификации они могут ограничить модель на Т-образном кадре и расширить видео. ТАКИМ ОБРАЗОМ, ОНИ ОБУЧИЛИ ВАРИАНТ ВИДЕО EMU ГЕНЕРИРОВАТЬ СЛЕДУЮЩИЕ 16 КАДРОВ ПРИ УСЛОВИИ «ПРОШЛЫХ» 16 КАДРОВ. При развертывании видео они используют текстовую подсказку, отличную от исходной видео, как показано на рисунке 7. Они обнаружили, что расширенное видео следует как за исходным видео, так и за будущими текстовыми подсказками.
Как видно из показанной демонстрации, EMU VIDEO уже может поддерживать 4-секундную генерацию видео. В статье они также исследуют способы увеличения длины видео. Авторы говорят, что с помощью небольшой архитектурной модификации они могут ограничить модель на Т-образном кадре и расширить видео. ТАКИМ ОБРАЗОМ, ОНИ ОБУЧИЛИ ВАРИАНТ ВИДЕО EMU ГЕНЕРИРОВАТЬ СЛЕДУЮЩИЕ 16 КАДРОВ ПРИ УСЛОВИИ «ПРОШЛЫХ» 16 КАДРОВ. При развертывании видео они используют текстовую подсказку, отличную от исходной видео, как показано на рисунке 7. Они обнаружили, что расширенное видео следует как за исходным видео, так и за будущими текстовыми подсказками.
 Emu Edit: Точное редактирование изображений
Emu Edit: Точное редактирование изображений
Миллионы людей используют редактирование изображений каждый день. Однако популярные инструменты редактирования изображений либо требуют значительного опыта и трудоемкого использования, либо очень ограничены и предлагают только набор предопределенных операций редактирования, таких как определенные фильтры. На этом этапе редактирование изображений на основе инструкций пытается заставить пользователей использовать инструкции на естественном языке, чтобы обойти эти ограничения. Например, пользователь может предоставить изображение модели и дать ей указание «одеть эму в костюм пожарного» (см. рисунок 1).
 Однако, несмотря на то, что модели редактирования изображений на основе инструкций, такие как InstructPix2Pix, могут использоваться для обработки различных заданных инструкций, их часто трудно интерпретировать и точно выполнять инструкции. Кроме того, эти модели имеют ограниченные возможности обобщения и часто не могут выполнять задачи, которые немного отличаются от тех, на которых они обучались (см. рис. 3), например, когда крольчиха трубят в радужную трубу, а другие модели либо окрашивают кролика в радужный цвет, либо непосредственно генерируют радужную трубу.
Однако, несмотря на то, что модели редактирования изображений на основе инструкций, такие как InstructPix2Pix, могут использоваться для обработки различных заданных инструкций, их часто трудно интерпретировать и точно выполнять инструкции. Кроме того, эти модели имеют ограниченные возможности обобщения и часто не могут выполнять задачи, которые немного отличаются от тех, на которых они обучались (см. рис. 3), например, когда крольчиха трубят в радужную трубу, а другие модели либо окрашивают кролика в радужный цвет, либо непосредственно генерируют радужную трубу.
 Чтобы решить эти проблемы, Meta представила Emu Edit, первую модель редактирования изображений, обученную на широком и разнообразном спектре задач, которая может выполнять редактирование в свободной форме на основе команд, включая локальное и глобальное редактирование, удаление и добавление фона, изменение цвета и геометрические преобразования, а также обнаружение и сегментирование.
Чтобы решить эти проблемы, Meta представила Emu Edit, первую модель редактирования изображений, обученную на широком и разнообразном спектре задач, которая может выполнять редактирование в свободной форме на основе команд, включая локальное и глобальное редактирование, удаление и добавление фона, изменение цвета и геометрические преобразования, а также обнаружение и сегментирование.
 Адрес:
Адрес:
Адрес проекта:
В отличие от многих современных моделей генеративного ИИ, Emu Edit может точно следовать инструкциям, гарантируя, что несвязанные пиксели во входном изображении останутся нетронутыми. Например, если пользователь дает команду «убрать щенка на траву», то картинка после удаления объекта будет едва заметна.
 Удаление текста в левом нижнем углу изображения и изменение фона изображения также будет обработано Emu Edit:
Удаление текста в левом нижнем углу изображения и изменение фона изображения также будет обработано Emu Edit:
 Для обучения этой модели Meta разработала набор данных из 10 миллионов синтетических образцов, каждый из которых содержал входное изображение, описание задачи, которую необходимо выполнить, и целевое выходное изображение. В результате Emu Edit демонстрирует беспрецедентные результаты редактирования с точки зрения точности команд и качества изображения.
Для обучения этой модели Meta разработала набор данных из 10 миллионов синтетических образцов, каждый из которых содержал входное изображение, описание задачи, которую необходимо выполнить, и целевое выходное изображение. В результате Emu Edit демонстрирует беспрецедентные результаты редактирования с точки зрения точности команд и качества изображения.
На методологическом уровне модели, обученные в Meta, могут выполнять шестнадцать различных задач редактирования изображений, включая редактирование на основе регионов, редактирование в свободной форме и задачи компьютерного зрения, все из которых сформулированы как генеративные задачи, и Meta также разработала уникальный конвейер управления данными для каждой задачи. Компания Meta обнаружила, что по мере увеличения количества обучающих заданий растет и производительность Emu Edit.
Во-вторых, для того, чтобы эффективно справляться с широким спектром задач, Meta ввела концепцию встраивания обученных задач, которая используется для направления процесса генерации в правильном направлении задачи сборки. В частности, для каждой задачи в данной работе изучается уникальный вектор вложения задачи, интегрируется он в модель с помощью перекрестного взаимодействия и добавляется к вложению временного шага. Результаты показывают, что встраивание обучающих задач значительно повышает способность модели точно рассуждать на основе инструкций в свободной форме и выполнять правильные правки.
В апреле этого года Meta запустила модель искусственного интеллекта «Split Everything», и эффект был настолько потрясающим, что многие люди начали задаваться вопросом, существует ли до сих пор поле CV. Всего за несколько месяцев Meta запустила Emu Video и Emu Edit в области изображений и видео, и мы можем только сказать, что сфера генеративного ИИ действительно слишком волатильна.
