链研社
用戶暫無簡介
链研社
港股打新命中率感人,最近打了 10 次沒中一次😅
查看原文- 打賞
- 按讚
- 回覆
- 轉發
- 分享
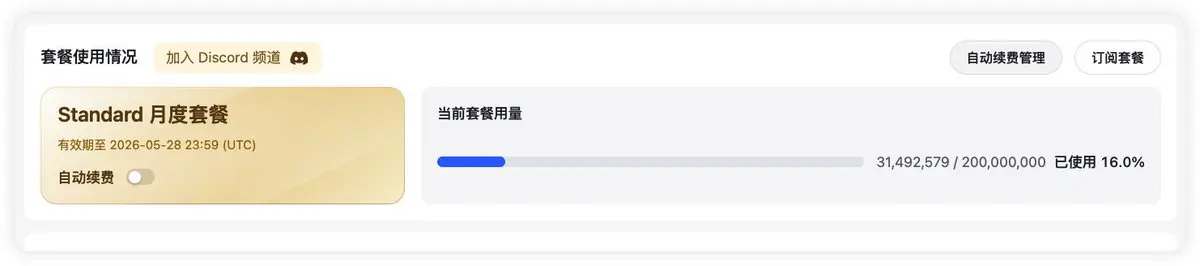
不行了,小米這送的 Token 也太不經用了,寫的質量還不咋地。2億的積分真要用一天多就用完了,這還是一個月 100 的套餐。。。
干不了幾個項目,也用不了幾天😅,到底是哪里出錯了
查看原文干不了幾個項目,也用不了幾天😅,到底是哪里出錯了
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
推薦一個這幾天用來覺得不錯,覺得替換掉notion 和 Obsidian 非常輕量級的筆記工具Tolaria
開源倉庫:refactoringhq/tolaria
Tolaria:有 Notion 的基本功能又有Obsidian 的掌控權和 AI Agent 的原生友好縫在一起的本地知識庫
如果你是重度 AI 工具用戶 + Markdown 党 + 有點極客潔癖那很適合。
開源 + 本地優先 + AI 原生的桌面知識管理工具。技術棧 Rust + Tauri,目前主打 macOS。
把 Notion、Obsidian、Claude code 這三類工具的特點集中更適合文字工作者
➤ 我為什麼換成這個寫作工具
2026 年這個節點,三個趨勢已經擺在台面上:
1、AI Agent 全面入侵本地工作流 — Claude Code、Codex CLI、Cursor 這些都在直接讀寫本地文件,雲端筆記反而變成了協作障礙
2、本地優先(Local-first)從極客口號變成主流訴求 — Notion 出過事故、Evernote 死過一輪用戶被教育了一圈,對「資料托管在別人伺服器」越來越警惕,一定要把資料掌握在自己手上
3、Obsidian 的插件生態太重不夠輕量級,notion 時間用就了也卡頓,占用內存巨大
Tolaria 卡的就是這三個趨勢的交叉
查看原文開源倉庫:refactoringhq/tolaria
Tolaria:有 Notion 的基本功能又有Obsidian 的掌控權和 AI Agent 的原生友好縫在一起的本地知識庫
如果你是重度 AI 工具用戶 + Markdown 党 + 有點極客潔癖那很適合。
開源 + 本地優先 + AI 原生的桌面知識管理工具。技術棧 Rust + Tauri,目前主打 macOS。
把 Notion、Obsidian、Claude code 這三類工具的特點集中更適合文字工作者
➤ 我為什麼換成這個寫作工具
2026 年這個節點,三個趨勢已經擺在台面上:
1、AI Agent 全面入侵本地工作流 — Claude Code、Codex CLI、Cursor 這些都在直接讀寫本地文件,雲端筆記反而變成了協作障礙
2、本地優先(Local-first)從極客口號變成主流訴求 — Notion 出過事故、Evernote 死過一輪用戶被教育了一圈,對「資料托管在別人伺服器」越來越警惕,一定要把資料掌握在自己手上
3、Obsidian 的插件生態太重不夠輕量級,notion 時間用就了也卡頓,占用內存巨大
Tolaria 卡的就是這三個趨勢的交叉
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
美光好猛直接新高了,感謝特朗普給的上車機會
查看原文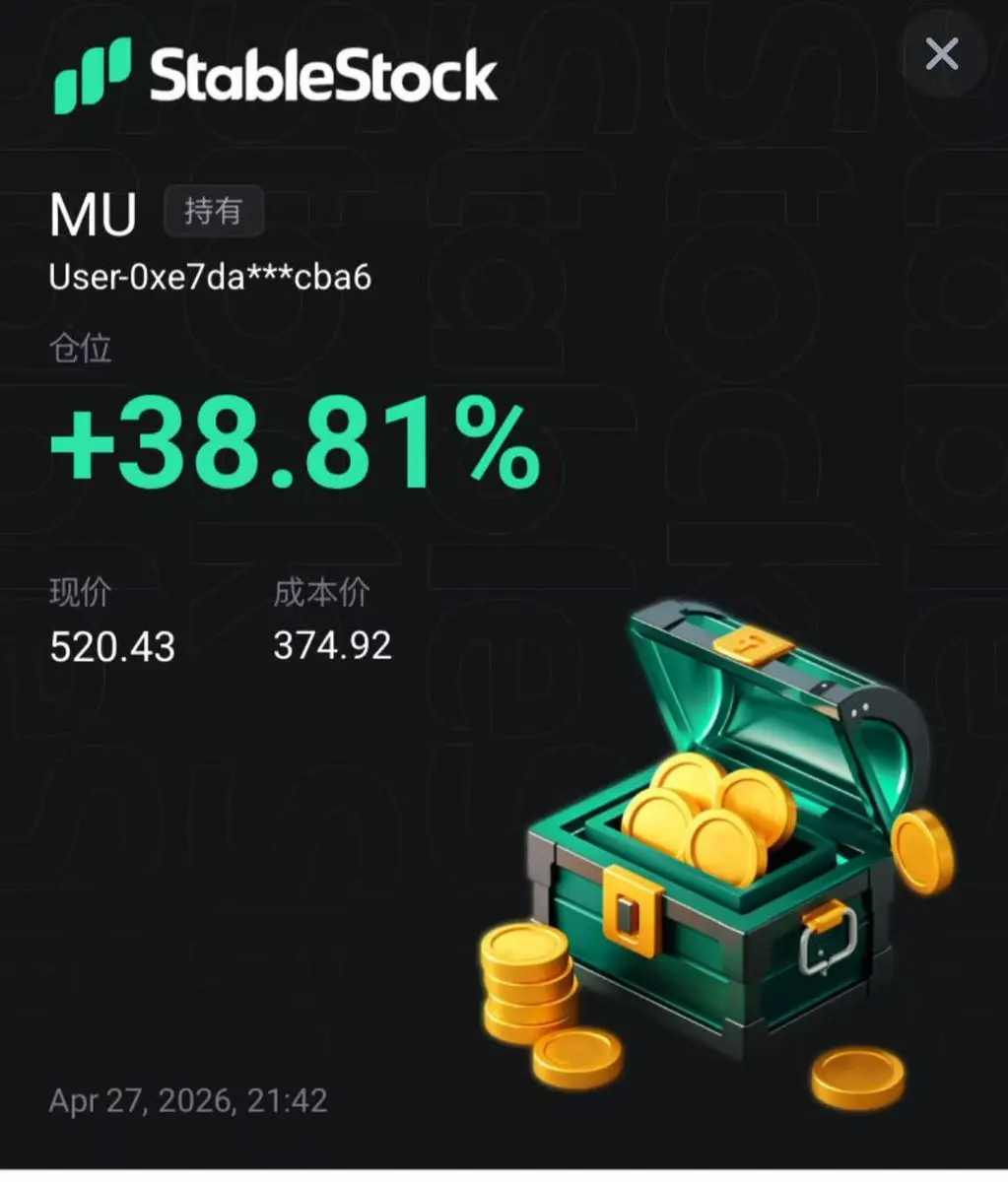
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
DeepSeek 連續兩天降價,按照他們原來的算力規模肯定是沒辦法支撐這麼大用戶數量的,所以大概率是已經融資並且拿到了算力支持,之前傳出是拿了阿里和騰訊的錢,估值 200 億美元。
DeepSeek 走到這步,不融資換算力支持的話可能就真的要掉隊了,人也要走了。沒算力訓練不出頂級模型,有頂級模型了,沒卡也做不了推理,有估值員工手裡的期權才有價值,羅福莉從 DeepSeek 走了以後去小米也能把模型干到前列超過字節和騰訊的模型,實力恐怖如斯。
阿里手上有芯片(平頭哥)、雲基礎設施(阿里雲)。國內芯片出貨量第二(市場佔有率 16%),第一是華為(市場佔有率 20%),在能接入國產芯片做推理,平頭哥可以保障DeepSeek未來的算力安全。
騰訊的 AI 產品開始就是靠全面接入DeepSeek才勉強有立足之地,也給 DeepSeek 做了開源貢獻。騰訊自己的 AI 產品都不大給力,算力估計都沒跑滿呢。
字節不對外投資任何 AI 模型團隊他們都自己做,華為雖然 AI 芯片走在前面但是投資概率不大,可能性最大的還是 DeepSeek 同時拿了騰訊和阿里的投資,一個保障現在,一個保障未來,本來國產大模型 kimi、minimax、智譜騰訊阿里都投了個遍再來個 DeepSeek 全家桶齊全了
查看原文DeepSeek 走到這步,不融資換算力支持的話可能就真的要掉隊了,人也要走了。沒算力訓練不出頂級模型,有頂級模型了,沒卡也做不了推理,有估值員工手裡的期權才有價值,羅福莉從 DeepSeek 走了以後去小米也能把模型干到前列超過字節和騰訊的模型,實力恐怖如斯。
阿里手上有芯片(平頭哥)、雲基礎設施(阿里雲)。國內芯片出貨量第二(市場佔有率 16%),第一是華為(市場佔有率 20%),在能接入國產芯片做推理,平頭哥可以保障DeepSeek未來的算力安全。
騰訊的 AI 產品開始就是靠全面接入DeepSeek才勉強有立足之地,也給 DeepSeek 做了開源貢獻。騰訊自己的 AI 產品都不大給力,算力估計都沒跑滿呢。
字節不對外投資任何 AI 模型團隊他們都自己做,華為雖然 AI 芯片走在前面但是投資概率不大,可能性最大的還是 DeepSeek 同時拿了騰訊和阿里的投資,一個保障現在,一個保障未來,本來國產大模型 kimi、minimax、智譜騰訊阿里都投了個遍再來個 DeepSeek 全家桶齊全了
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
下半年國產模型開始適配大量出貨的國產芯片,英偉達危?
查看原文- 打賞
- 按讚
- 回覆
- 轉發
- 分享
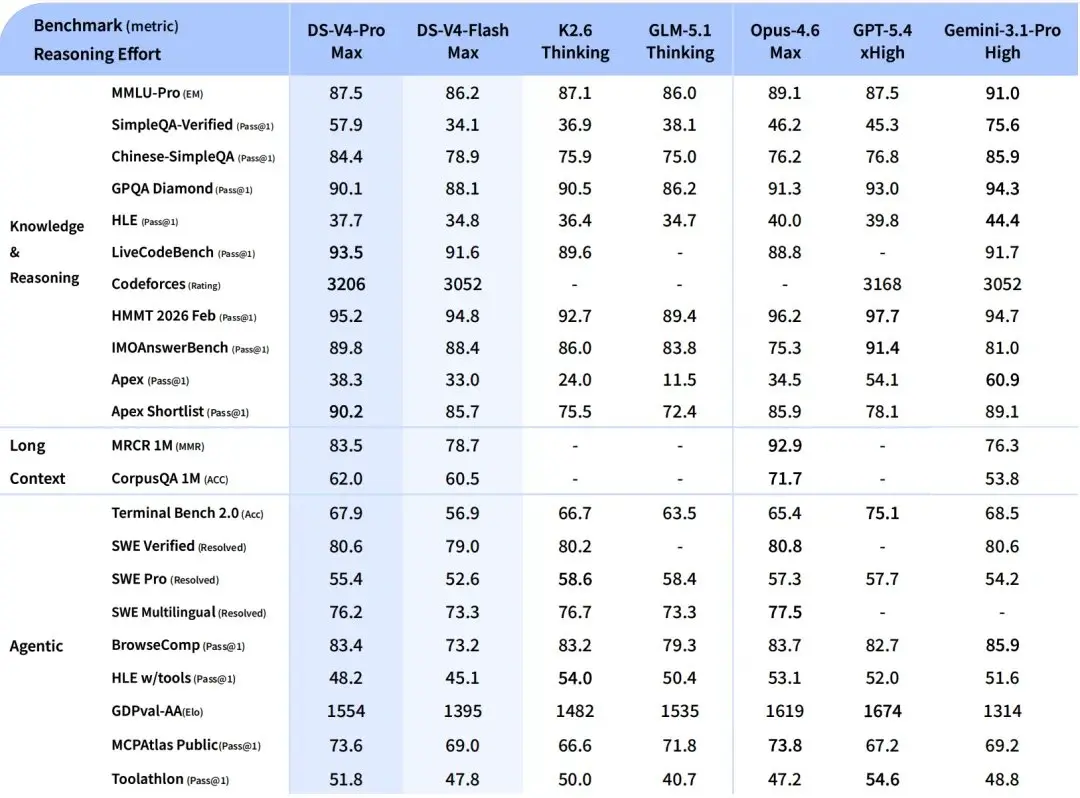
DeepSeek V4 這次真的來了,登頂國內模型,力壓 GPT-5.4。
DeepSeek V4-Pro 定價,快取命中輸入 1 元、未命中 12 元、輸出 24 元/百萬 token,和 GLM5.1 模型定價相當,但能力強於 GLM 5.1。
國內模型集中發布 GLM5.1、k2.6、qwen3.6max。屁股都沒坐穩兩週就被 DeepSeek 屠榜了
查看原文DeepSeek V4-Pro 定價,快取命中輸入 1 元、未命中 12 元、輸出 24 元/百萬 token,和 GLM5.1 模型定價相當,但能力強於 GLM 5.1。
國內模型集中發布 GLM5.1、k2.6、qwen3.6max。屁股都沒坐穩兩週就被 DeepSeek 屠榜了
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
真相了😂
如果你把白酒,醫藥,美妝等等這些傳統消費品,定義為"碳基生命"消費;把半導體,PCB,光模組這些定義為"矽基生命"的消費品,你會有一種感覺,人類已經失去了對股市,對互聯網甚至是對未來的掌控,在這背後,實際的操控者已經變成我們創造出來的人工智慧,引導資金向著它需要投入的地方去,而我們只不過是面上的"傀儡".這會不會就是真相
查看原文如果你把白酒,醫藥,美妝等等這些傳統消費品,定義為"碳基生命"消費;把半導體,PCB,光模組這些定義為"矽基生命"的消費品,你會有一種感覺,人類已經失去了對股市,對互聯網甚至是對未來的掌控,在這背後,實際的操控者已經變成我們創造出來的人工智慧,引導資金向著它需要投入的地方去,而我們只不過是面上的"傀儡".這會不會就是真相
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
DeepSeek 估值 100 億美元以上,融資 3 億美元。未上市公司裡與之對比的月之暗面 kimi 最近一輪融資 10 億美元,估值 180 億美元。
還有兩個已經上市的智譜和 minimax
1. 智譜 AI
上市融資額: 募資淨額約 41.7 億港元,折合約 5.3 億美元
上市市值: IPO 發行價為 116.2 港元,發行時的整體估值約 518 億港元。
現在市值: 891 港幣,總市值維持在 4000 億港元左右。
2. MiniMax
上市融資額: IPO 募資額約 48.2 億港元,折合約 6.16 億美元
上市市值: IPO 發行價定於上限 165 港元,發行估值超 460 億港元。
現在市值: 859 港幣,目前總市值 2700 億港元左右。
查看原文還有兩個已經上市的智譜和 minimax
1. 智譜 AI
上市融資額: 募資淨額約 41.7 億港元,折合約 5.3 億美元
上市市值: IPO 發行價為 116.2 港元,發行時的整體估值約 518 億港元。
現在市值: 891 港幣,總市值維持在 4000 億港元左右。
2. MiniMax
上市融資額: IPO 募資額約 48.2 億港元,折合約 6.16 億美元
上市市值: IPO 發行價定於上限 165 港元,發行估值超 460 億港元。
現在市值: 859 港幣,目前總市值 2700 億港元左右。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
DeepSeek 即將發布新模型,還在與華為進行深度的底層算力適配所以耽誤了不少進度,據說推理和訓練將全部跑在華為芯片上。
如果這件事落地,黃仁勳最擔心的那個劇本就成真了。
他前幾天在 Dwarkesh Patel 的採訪裡提到:「如果未來某天 DeepSeek 級別的模型率先在華為芯片上發布,那對我們的國家將是一個可怕的結果。」
現在這個「某天」可能就快到了。
黃仁勳反對芯片出口管制的邏輯很簡單(當然我覺得他還是想賺中國的錢,這是除美國外最大的市場)
1、中國算力早就夠用了。 AI 訓練是並行計算問題,一顆 H100 幹的活,一堆 7nm 芯片堆起來也能幹。中國有大量 7nm 產能和廉價能源,Anthropic 的 Mythos 是在「相當普通的算力規模」上訓練出來的,這種算力在中國已經大量存在,說明訓練出最頂端的模型,中國的算力已經足夠了,華為 2025 年營收 8809 億元,出貨了數以百萬計的芯片。
2、算法比算力更決定上限。 中國擁有全球50%以上的 AI 研究者,去看看全球最頂尖的AI實驗室就知道了,裡面華裔的人數佔了多數。DeepSeek 不是靠堆卡堆出來的,是算法層面的突破。算力是下限,算法才是上限。
中國模型的訓練成本只有美國的十分之一不到,中國的算力中心電費只有美國的一半,所以現在的中國模型API定價並不是虧本在賣,利潤率跟美國相比可能並沒我們想象的那麼大。那如
查看原文如果這件事落地,黃仁勳最擔心的那個劇本就成真了。
他前幾天在 Dwarkesh Patel 的採訪裡提到:「如果未來某天 DeepSeek 級別的模型率先在華為芯片上發布,那對我們的國家將是一個可怕的結果。」
現在這個「某天」可能就快到了。
黃仁勳反對芯片出口管制的邏輯很簡單(當然我覺得他還是想賺中國的錢,這是除美國外最大的市場)
1、中國算力早就夠用了。 AI 訓練是並行計算問題,一顆 H100 幹的活,一堆 7nm 芯片堆起來也能幹。中國有大量 7nm 產能和廉價能源,Anthropic 的 Mythos 是在「相當普通的算力規模」上訓練出來的,這種算力在中國已經大量存在,說明訓練出最頂端的模型,中國的算力已經足夠了,華為 2025 年營收 8809 億元,出貨了數以百萬計的芯片。
2、算法比算力更決定上限。 中國擁有全球50%以上的 AI 研究者,去看看全球最頂尖的AI實驗室就知道了,裡面華裔的人數佔了多數。DeepSeek 不是靠堆卡堆出來的,是算法層面的突破。算力是下限,算法才是上限。
中國模型的訓練成本只有美國的十分之一不到,中國的算力中心電費只有美國的一半,所以現在的中國模型API定價並不是虧本在賣,利潤率跟美國相比可能並沒我們想象的那麼大。那如
- 打賞
- 1
- 回覆
- 轉發
- 分享
SEC 废除「日内交易」门槛,美股散户迎来 25 年来最大规则变化
4 月 14 日,SEC 正式批准 FINRA 提案,废了已经实施25 年的 Pattern Day Trading(PDT)规则。
核心变化三条
1、取消 $25,000 最低账户门槛
2、取消「日内交易者」身份标签
3、用实时风险保证金体系替代原有的交易次数限制
先说旧规则有多离谱
PDT 规则诞生于 2001 年,互联网泡沫破裂 后 SEC 为了保护散户加的限制:5 个交易日内超过 4 次日内交易,账户直接被标记为 PDT,交易权限锁死。
解锁条件?账户里至少放 $25,000
翻译成大白话:没钱就别玩日内交易。这条规则存在了 25 年。25 年里,市场结构、交易技术、参与者构成全变了,规则一个字没动
新规改了什么?
最核心变化不是取消门槛,而是底层 逻辑从「限制行为」变成了「控制风险」
旧逻辑:你做了几次 交易?超过 4 次?锁账户
新逻辑:你当前的风险敞口 是多少?保证金够不够覆盖?不够就不让你开新仓。
具体执行上,FINRA 给券商两条路:
- 实时监控:系统在交易发生前就判断保证金是否充足,不够直接拦截
- 交易日结束计算:每天收盘后算一次日内风险暴露
如果账户返复在 5 个交易日内出现保证金缺口且不补足,会被冻结 90 天的做空和加杠杆权限。小额缺口(低于账户净值 5% 或 $1,000)豁免。
另
4 月 14 日,SEC 正式批准 FINRA 提案,废了已经实施25 年的 Pattern Day Trading(PDT)规则。
核心变化三条
1、取消 $25,000 最低账户门槛
2、取消「日内交易者」身份标签
3、用实时风险保证金体系替代原有的交易次数限制
先说旧规则有多离谱
PDT 规则诞生于 2001 年,互联网泡沫破裂 后 SEC 为了保护散户加的限制:5 个交易日内超过 4 次日内交易,账户直接被标记为 PDT,交易权限锁死。
解锁条件?账户里至少放 $25,000
翻译成大白话:没钱就别玩日内交易。这条规则存在了 25 年。25 年里,市场结构、交易技术、参与者构成全变了,规则一个字没动
新规改了什么?
最核心变化不是取消门槛,而是底层 逻辑从「限制行为」变成了「控制风险」
旧逻辑:你做了几次 交易?超过 4 次?锁账户
新逻辑:你当前的风险敞口 是多少?保证金够不够覆盖?不够就不让你开新仓。
具体执行上,FINRA 给券商两条路:
- 实时监控:系统在交易发生前就判断保证金是否充足,不够直接拦截
- 交易日结束计算:每天收盘后算一次日内风险暴露
如果账户返复在 5 个交易日内出现保证金缺口且不补足,会被冻结 90 天的做空和加杠杆权限。小额缺口(低于账户净值 5% 或 $1,000)豁免。
另
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
納斯達克指數完成了驚人的日線十連漲,美股每次下跌都是機會,只需要幹就完了。
之前說在 4 月 15 號之前把美股的倉位建完,一年一度的好時機,和去年的關稅戰是一模一樣
查看原文之前說在 4 月 15 號之前把美股的倉位建完,一年一度的好時機,和去年的關稅戰是一模一樣
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
Claude 開始反蒸餾和封號的究極手段了,KYC...
中國人天塌了
查看原文中國人天塌了

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
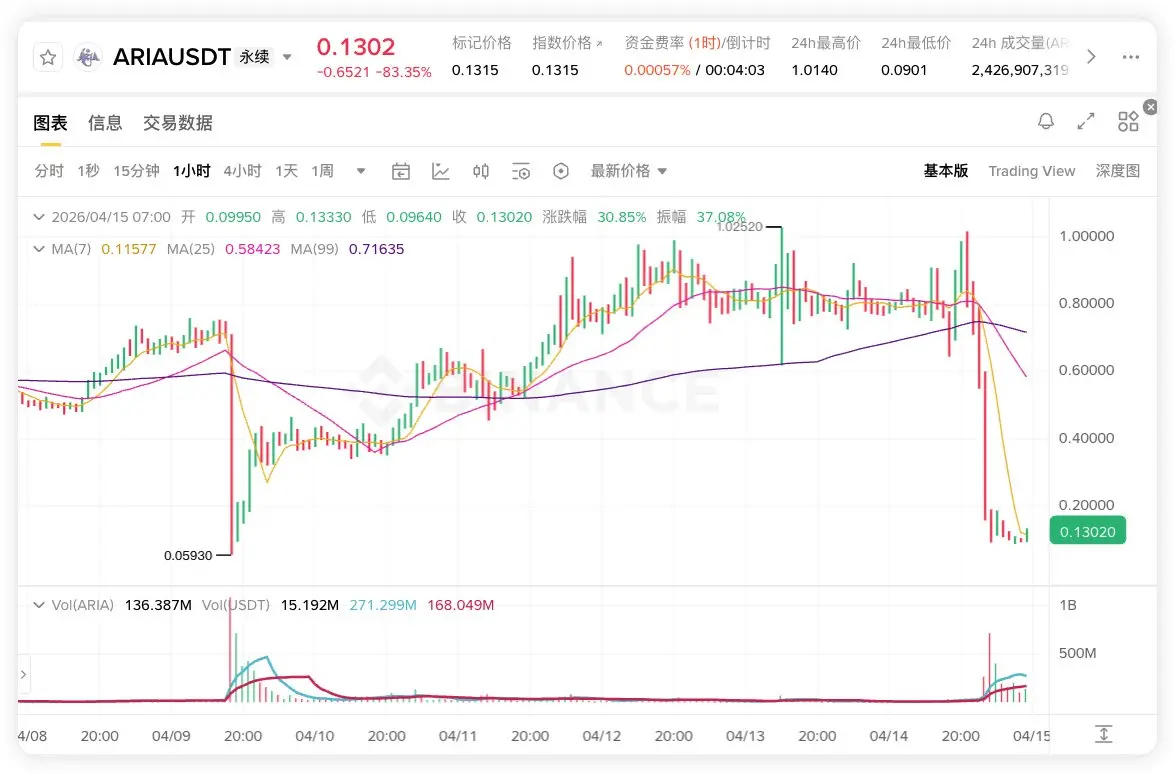
試用了一下Qwen Code 還挺好用的,每天有 1000 次額度,每分鐘最多 60 次,沒有 Token 上限,基本是夠用了,命令行的功能都有中文註釋。
Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
查看原文Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
試用了一下Qwen Code 還挺好用的,每天有 2000 次額度,每分鐘最多 60 次,沒有 Token 上限,基本是夠用了,命令行的功能都有中文註釋。
Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
查看原文Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
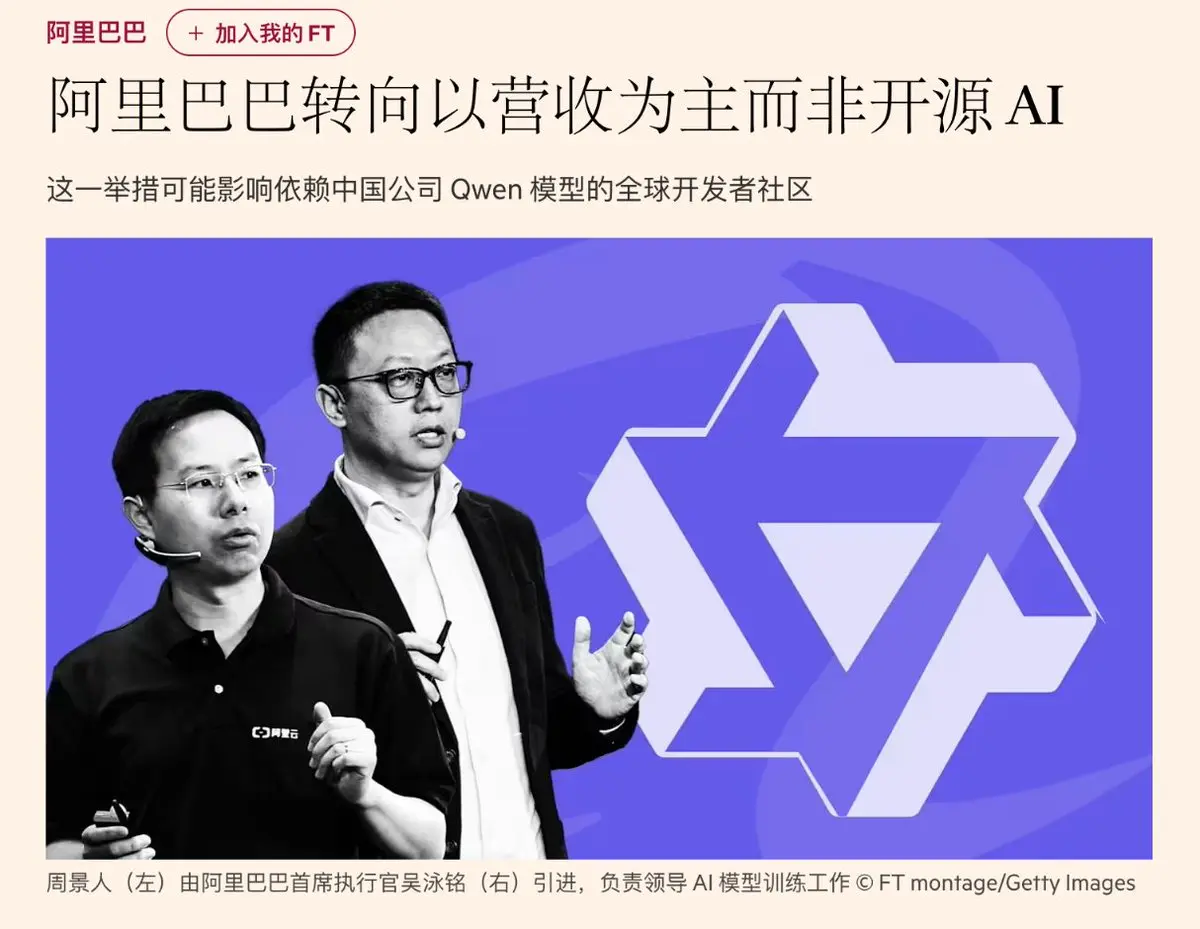
阿里巴巴对 AI 发展进行战略转向,从追求开源生态转向商业变现,Qwen 团队核心人物林俊阳、胡斌元等因战略分歧离职,阿里云前 CTO 周靖人接手,CEO 吴泳铭成立"Alibaba Token Hub"并组建 AI 策略委员会,明确将模型开发与云业务营收目标对齐,公司明确转向,MaaS 和商业化优先。
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
比Seedance2.0牛逼的HappyHorse 竟然還開源?
HappyHorse 背後的人是淘天集團的張迪,之前是快手Kling一號位,再之前是阿里媽媽大數據與機器學習工程架構負責人,在阿里待了 10 年,去年被老東家重新請回去。
不過阿里的公關宣傳你懂的,實際用起來可能還要打個折扣,對標Seedance2.0,打平Kling還是可能的,關鍵是開源啊,那還要啥自行車
查看原文HappyHorse 背後的人是淘天集團的張迪,之前是快手Kling一號位,再之前是阿里媽媽大數據與機器學習工程架構負責人,在阿里待了 10 年,去年被老東家重新請回去。
不過阿里的公關宣傳你懂的,實際用起來可能還要打個折扣,對標Seedance2.0,打平Kling還是可能的,關鍵是開源啊,那還要啥自行車
- 打賞
- 2
- 回覆
- 轉發
- 分享
中國大模型的作弊蒸餾之路要被海外御三家聯手封殺了,國內大模型的好日子到頭了,看看誰會先原形畢露😂
kimi、minimax、DeepSeek 都是上了蒸餾黑名單的,GLM 和 Qwen 倒是沒被點名
查看原文kimi、minimax、DeepSeek 都是上了蒸餾黑名單的,GLM 和 Qwen 倒是沒被點名
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
熱門話題
查看更多45.13萬 熱度
5869.89萬 熱度
98.71萬 熱度
3.08萬 熱度
1017.54萬 熱度
置頂
🔥 WCTC S8 全球交易賽正式開賽!
8,000,000 USDT 超級獎池解鎖開啟
🏆 團隊賽:上半場正式開啟,預報名階段 5,500+ 戰隊現已集結
交易量收益額雙重比拼,解鎖上半場 1,800,000 USDT 獎池
🏆 個人賽:現貨、合約、TradFi、ETF、閃兌、跟單齊上陣
全場交易量比拼,瓜分 2,000,000 USDT 獎池
🏆 王者 PK 賽:零門檻參與,實時匹配享受戰鬥快感
收益率即時 PK,瓜分 1,600,000 USDT 獎池
活動時間:2026 年 4 月 23 日 16:00:00 - 2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即參與:https://www.gate.com/competition/wctc-s8
#WCTCS810,000 USDT 悬賞,尋找跟單金牌星探!🕵️
挖掘頂級帶單員,贏取高額跟單體驗金!
立即參與:https://www.gate.com/campaigns/4624
🎁 三大活動,獎金疊滿:
1️⃣ 慧眼識英:發帖推薦帶單員,分享跟單體驗,抽 100 位送 30 USDT!
2️⃣ 強力應援:曬出你的跟單截圖,為大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交達人:同步至 X/Twitter,憑流量贏取 100 USDT!
📍 標籤: #跟单金牌星探 #GateCopyTrading
⏰ 限時: 4/22 16:00 - 5/10 16:00 (UTC+8)
詳情:https://www.gate.com/announcements/article/50848