Generative AI has entered the video age.
Original source: Heart of the Machine
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
When it comes to video generation, many people probably think of Gen-2 and Pika Labs first. But just now, Meta announced that they have surpassed both of them in terms of video generation and are more flexible in editing.

 This “trumpet, dancing rabbit” is the latest demo released by Meta. As you can see, Meta’s technology supports both flexible image editing (e.g., turning a “rabbit” into a “trumpet bunny” and then a “rainbow-colored trumpet bunny”) and generating high-resolution video from text and images (e.g., having a “trumpet bunny” dance happily).
This “trumpet, dancing rabbit” is the latest demo released by Meta. As you can see, Meta’s technology supports both flexible image editing (e.g., turning a “rabbit” into a “trumpet bunny” and then a “rainbow-colored trumpet bunny”) and generating high-resolution video from text and images (e.g., having a “trumpet bunny” dance happily).
Actually, there are two things involved.
Flexible image editing is done by a model called “Emu Edit”. It supports free editing of images with text, including local and global editing, removing and adding backgrounds, color and geometry conversions, detection and segmentation, and more. In addition, it follows instructions precisely, ensuring that the pixels in the input image that are not related to the instructions remain intact.
 Dress the ostrich in a skirt
Dress the ostrich in a skirt
The high-resolution video is generated by a model called “Emu Video”. Emu Video is a diffusion-based model of Wensheng video that is capable of generating 512x512 4-second high-resolution video based on text (longer videos are also discussed in the paper). A rigorous human evaluation showed that Emu Video scored higher in both the quality of the generation and the fidelity of the text compared to Runway’s Gen-2 and Pika Labs’ generation performance. Here’s how it will look:

 In its official blog, Meta envisioned the future of both technologies, including allowing social media users to generate their own GIFs, memes, and edit photos and images as they wish. Regarding this, Meta also mentioned this when it released the Emu model at the previous Meta Connect conference (see: “Meta’s version of ChatGPT is here: Llama 2 blessing, access to Bing search, Xiaozha live demo”).
In its official blog, Meta envisioned the future of both technologies, including allowing social media users to generate their own GIFs, memes, and edit photos and images as they wish. Regarding this, Meta also mentioned this when it released the Emu model at the previous Meta Connect conference (see: “Meta’s version of ChatGPT is here: Llama 2 blessing, access to Bing search, Xiaozha live demo”).
 Next, we will introduce each of these two new models.
Next, we will introduce each of these two new models.
EmuVideo
The large Wensheng graph model is trained on web-scale image-text pairs to produce high-quality, diverse images. While these models can be further adapted to text-to-video (T2V) generation through the use of video-text pairs, video generation still lags behind image generation in terms of quality and variety. Compared to image generation, video generation is more challenging because it requires modeling a higher dimension of spatiotemporal output space, which can still be based on text prompts. In addition, video-text datasets are typically an order of magnitude smaller than image-text datasets.
The prevailing mode of video generation is to use a diffusion model to generate all video frames at once. In stark contrast, in NLP, long sequence generation is formulated as an autoregressive problem: predicting the next word on the condition of a previously predicted word. As a result, the conditioning signal of the subsequent prediction will gradually become stronger. The researchers hypothesize that enhanced conditioning is also important for high-quality video generation, which is itself a time series. However, autoregressive decoding with diffusion models is challenging, as generating a single-frame image with the help of such models requires multiple iterations in itself.
As a result, Meta’s researchers proposed EMU VIDEO, which augments diffusion-based text-to-video generation with an explicit intermediate image generation step.
 Address:
Address:
Project Address:
Specifically, they decomposed the Wensheng video problem into two sub-problems: (1) generating an image based on the input text prompt, and (2) generating a video based on the reinforcement conditions of the image and text. Intuitively, giving the model a starting image and text makes video generation easier, as the model only needs to predict how the image will evolve in the future.
 *Meta’s researchers split the Wensheng video into two steps: first generate image I conditional on text p, and then use stronger conditions – the resulting image and text – to generate video v. To constrain Model F with an image, they temporarily zeroed in on the image and connected it to a binary mask that indicates which frames were zeroed, as well as a noisy input. *
*Meta’s researchers split the Wensheng video into two steps: first generate image I conditional on text p, and then use stronger conditions – the resulting image and text – to generate video v. To constrain Model F with an image, they temporarily zeroed in on the image and connected it to a binary mask that indicates which frames were zeroed, as well as a noisy input. *
Since the video-text dataset is much smaller than the image-text dataset, the researchers also initialized their text-to-video model with a weight-frozen pretrained text-image (T2I) model. They identified key design decisions—changing diffuse noise scheduling and multi-stage training—to directly produce 512px high-resolution video.
Unlike the method of generating a video directly from text, their decomposition method explicitly generates an image when inferring, which allows them to easily preserve the visual diversity, style, and quality of the Wensheng diagram model (as shown in Figure 1). THIS ALLOWS EMU VIDEO TO OUTPERFORM DIRECT T2V METHODS EVEN WITH THE SAME TRAINING DATA, AMOUNT OF COMPUTATION, AND TRAINABLE PARAMETERS.

 This study shows that the quality of Wensheng video generation can be greatly improved through a multi-stage training method. This method supports direct generation of high-resolution video at 512px without the need for some of the deep cascade models used in the previous method.
This study shows that the quality of Wensheng video generation can be greatly improved through a multi-stage training method. This method supports direct generation of high-resolution video at 512px without the need for some of the deep cascade models used in the previous method.

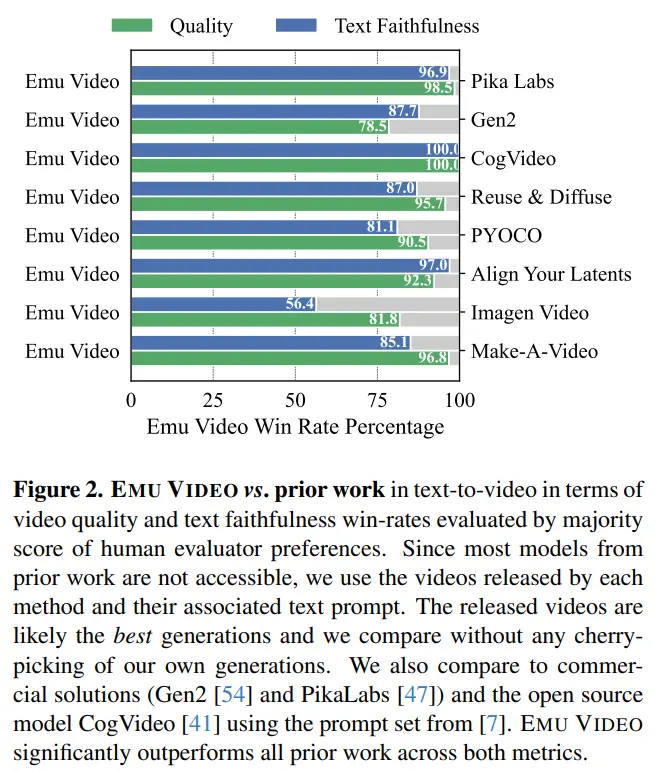
 The researchers devised a robust human assessment protocol, JUICE, in which evaluators were asked to prove that their choice was correct when making a choice between pairs. As shown in Figure 2, EMU VIDEO’s average win rates of 91.8% and 86.6% in terms of quality and text fidelity are far ahead of all upfront work including commercial solutions such as Pika, Gen-2, and others. IN ADDITION TO T2V, EMU VIDEO CAN ALSO BE USED FOR IMAGE-TO-VIDEO GENERATION, WHERE THE MODEL GENERATES VIDEO BASED ON USER-PROVIDED IMAGES AND TEXT PROMPTS. In this case, EMU VIDEO’s generation results are 96% better than VideoComposer.
The researchers devised a robust human assessment protocol, JUICE, in which evaluators were asked to prove that their choice was correct when making a choice between pairs. As shown in Figure 2, EMU VIDEO’s average win rates of 91.8% and 86.6% in terms of quality and text fidelity are far ahead of all upfront work including commercial solutions such as Pika, Gen-2, and others. IN ADDITION TO T2V, EMU VIDEO CAN ALSO BE USED FOR IMAGE-TO-VIDEO GENERATION, WHERE THE MODEL GENERATES VIDEO BASED ON USER-PROVIDED IMAGES AND TEXT PROMPTS. In this case, EMU VIDEO’s generation results are 96% better than VideoComposer.
 As you can see from the demo shown, EMU VIDEO can already support 4-second video generation. In the paper, they also explore ways to increase the length of the video. With a small architectural modification, the authors say they can constrain the model on a T-frame and extend the video. SO, THEY TRAINED A VARIANT OF EMU VIDEO TO GENERATE THE NEXT 16 FRAMES ON THE CONDITION OF “PAST” 16 FRAMES. When expanding the video, they use a different future text prompt than the original video, as shown in Figure 7. They found that the extended video follows both the original video and future text prompts.
As you can see from the demo shown, EMU VIDEO can already support 4-second video generation. In the paper, they also explore ways to increase the length of the video. With a small architectural modification, the authors say they can constrain the model on a T-frame and extend the video. SO, THEY TRAINED A VARIANT OF EMU VIDEO TO GENERATE THE NEXT 16 FRAMES ON THE CONDITION OF “PAST” 16 FRAMES. When expanding the video, they use a different future text prompt than the original video, as shown in Figure 7. They found that the extended video follows both the original video and future text prompts.
 Emu Edit: Precise Image Editing
Emu Edit: Precise Image Editing
Millions of people use image editing every day. However, popular image editing tools either require considerable expertise and are time-consuming to use, or are very limited and offer only a set of predefined editing operations, such as specific filters. At this stage, instruction-based image editing attempts to get users to use natural language instructions to work around these limitations. For example, a user can provide an image to a model and instruct it to “dress an emu in a firefighter costume” (see Figure 1).
 However, while instruction-based image editing models like InstructPix2Pix can be used to handle a variety of given instructions, they are often difficult to interpret and execute instructions accurately. In addition, these models have limited generalization capabilities and are often unable to perform tasks that are slightly different from those they were trained on (see Figure 3), such as having a baby rabbit blow a rainbow-colored trumpet, and other models either dyeing the rabbit rainbow-colored or directly generating a rainbow-colored trumpet.
However, while instruction-based image editing models like InstructPix2Pix can be used to handle a variety of given instructions, they are often difficult to interpret and execute instructions accurately. In addition, these models have limited generalization capabilities and are often unable to perform tasks that are slightly different from those they were trained on (see Figure 3), such as having a baby rabbit blow a rainbow-colored trumpet, and other models either dyeing the rabbit rainbow-colored or directly generating a rainbow-colored trumpet.
 To address these issues, Meta introduced Emu Edit, the first image editing model trained on a wide and diverse range of tasks, which can perform free-form edits based on commands, including local and global editing, removing and adding backgrounds, color changes and geometric transformations, and detecting and segmenting.
To address these issues, Meta introduced Emu Edit, the first image editing model trained on a wide and diverse range of tasks, which can perform free-form edits based on commands, including local and global editing, removing and adding backgrounds, color changes and geometric transformations, and detecting and segmenting.
 Address:
Address:
Project Address:
Unlike many of today’s generative AI models, Emu Edit can follow instructions precisely, ensuring that the unrelated pixels in the input image remain intact. For example, if the user gives the command “remove the puppy on the grass”, the picture after removing the object is barely noticeable.
 Removing the text in the bottom left corner of the image and changing the background of the image will also be handled by Emu Edit:
Removing the text in the bottom left corner of the image and changing the background of the image will also be handled by Emu Edit:
 To train this model, Meta developed a dataset of 10 million synthetic samples, each containing an input image, a description of the task to be performed, and a target output image. As a result, Emu Edit shows unprecedented editing results in terms of command fidelity and image quality.
To train this model, Meta developed a dataset of 10 million synthetic samples, each containing an input image, a description of the task to be performed, and a target output image. As a result, Emu Edit shows unprecedented editing results in terms of command fidelity and image quality.
At the methodology level, Meta-trained models can perform sixteen different image editing tasks, covering region-based editing, free-form editing, and computer vision tasks, all of which are formulated as generative tasks, and Meta has also developed a unique data management pipeline for each task. Meta has found that as the number of training tasks increases, so does the performance of Emu Edit.
Second, in order to effectively handle a wide variety of tasks, Meta introduced the concept of learned task embedding, which is used to guide the generation process in the right direction of the build task. Specifically, for each task, this paper learns a unique task embedding vector and integrates it into the model through cross-attention interaction and adds it to the time-step embedding. The results show that learning task embedding significantly enhances the model’s ability to accurately reason from free-form instructions and perform correct edits.
In April this year, Meta launched the “Split Everything” AI model, and the effect was so amazing that many people began to wonder if the CV field still exists. In just a few months, Meta has launched Emu Video and Emu Edit in the field of images and videos, and we can only say that the field of generative AI is really too volatile.
