**Text: **Ling Zijun, Wan Chen, Li Shiyun, Li Yuan, Wei Shijie
Editor: Wei Shijie
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
Looking back at history is always full of drama.
In May 2021, at the Google I/O conference, a demo in which the chat robot LaMDA played the role of “Pluto” talking to humans was demonstrated, which immediately won applause from the scene. At this time, it has been six years since Google set the goal of “AI First”, and it is nearly 18 months before the release of OpenAI’s ChatGPT that shocked the world.
At this time, Google is still a pioneer in the field of AI. But two key engineers behind the project, De Freitas and Shazeer, were frustrated.
They wanted to be able to showcase the case for LaMDA’s entry into Google Assistant,** but the chatbot project has been scrutinized several times over the years and has been blocked from a wider release for a variety of reasons. **
In the previous year, OpenAI had announced GPT3 with 175 billion parameters and opened API testing. However, due to various risks of “technical political correctness”, Google has been reluctant to release the products of the dialogue model to the public.
As a result, De Freitas and Shazeer were interested in leaving. Although CEO Pichai personally persuaded them to stay, they eventually left Google at the end of 2021 and founded Character AI, one of the current unicorns in the field of AI large models.
In this way, Google missed the first-mover advantage of leading the change.
Later stories became more widely circulated. At the end of 2022, ChatGPT was born, which not only made OpenAI famous, but also made its investor Microsoft kill the Quartet. With the blessing of GPT-4, Microsoft launched the search product New Bing, aiming at Google. Not only Google, but the entire Silicon Valley and the world were also shocked.
In the blink of an eye, 8 months have passed. On the other side of the ocean, the surprise brought by OpenAI has passed. The Silicon Valley giants have passed the panic period and have found their place in the new battle situation. Fan scene.
In the past half a year of rapid changes in technology and business, the industry’s cognition and consensus on large models have also been continuously updated. After communicating with nearly a hundred entrepreneurs, investors, and practitioners in Silicon Valley and China, Geek Park concluded that the large model The 5 status quo of entrepreneurship, trying to present a “big model business world view” that has yet to be verified. **
Google’s missed opportunities and OpenAI’s stunning debut actually remind us that the world is lagging behind, taking the lead, and alternating from time to time. **The current technological and business evolution is far from the end, and the real change has not even officially begun. One just has to remember that innovation can happen anytime, anywhere.
Note: The full text has a total of 14573 words, and it is expected to take about 30 minutes to read. It is recommended to pay attention, bookmark and watch.
Schrödinger’s OpenAI: Everyone’s Hero, and Everyone’s Enemy
When the Chinese entrepreneurial circle still regards OpenAI as the new god of Silicon Valley, Silicon Valley has quietly begun to disenchant OpenAI.
Although OpenAI has achieved technological breakthroughs and is still a place where AI talents are flocking to—many companies claim to attack talents from OpenAI—the fact is that to this day, OpenAI’s top technical talents are still “net inflow”. Its belief in AGI and its vision-driven technological breakthroughs over the past eight years have made the company a hero to many.
**But heroes have to live too. **The next step in technological breakthroughs is to create value to create business cycles. Silicon Valley’s controversy lies in whether OpenAI can really continue to lead? **
Many Silicon Valley entrepreneurs, practitioners, and investors expressed negative judgments to Geek Park. What people question is that, as far as the current situation is concerned, there are hidden concerns in the business model presented by OpenAI **-in the non-consensus stage of “former ChatGPT”, OpenAI can still win resources with the belief of a few people, and now AGI has become a consensus, and there are many competitors. If you want to maintain the lead, the challenges and difficulties will rise sharply.
If the business profit model is divided into toB and toC, the former OpenAI does not have the toB gene, and the current competitor——In terms of enterprise services, Microsoft, the capital of OpenAI, is the king in this field, Microsoft’s enterprise chat application market share exceeds 65%, and its Teams has gradually eroded the market of the star company Slack in recent years. In the field of toB, Microsoft, which has been established for 48 years and has spanned several technology cycles, undoubtedly has a deeper accumulation than the start-up company OpenAI.
But if you want to do toB business, OpenAI ** also faces the question of centralization risk. **Currently, OpenAI’s open API model for enterprises has attracted a number of customers to use it—especially small and medium-sized developers, who are unable to train a large model independently, and accessing the GPT series of APIs has become an excellent choice. Jasper.AI, which has just become a unicorn, is one of the best examples. Through access to GPT3, Jsaper.AI was valued at 1.5 billion US dollars only 18 months after its establishment.
“But everyone is not optimistic about Jasper.AI because of this.” An investor in a mainstream Silicon Valley fund told Geek Park. Private data is the most important asset of an enterprise. At present, connecting private data to a centralized large model first faces compliance and security issues—even though Sam Altman promised in May that OpenAI will not take advantage of customers using APIs. Data for training—but that neither reassures the business nor earns its trust.
** “Some corporate customers in the United States are generally worried about using ** OpenAI **.” The investor told us that in the eyes of enterprises, OpenAI is closest to AWS in the cloud era, but everyone will not use it AWS logic faces it. “Customers are generally reluctant to hand over data and key competitiveness to OpenAI, and feel that there will be risks.” **Even if the GPT series can help vertical fields to train large models with centralized capabilities, it is dangerous for customers to build competitiveness based on this-this will be a “star-attracting method”: if your own data And experience can eventually be used by others, which will lower the barriers to competition for industry leaders.
**And do toC? **
It seems that OpenAI ** has a user advantage on the C side. **Since the release of its super product ChatGPT, its monthly activity has climbed to 1.5 billion, compared to Instagram’s monthly activity of only 2 billion. **However, a huge monthly activity may not necessarily bring a data flywheel effect to OpenAI - “(By) users continue to ask questions to do (big model) training, the data is of little value.” **An entrepreneur pointed out .
It is worth noting that since June, the monthly activity of ChatGPT has declined for the first time. Speculations on this include:
- Because the freshness of technology has declined - in fact, the growth rate of ChatGPT’s visits has been declining, and the month-on-month ratio in May was only 2.8%;
- Student holidays lead to a decrease in student usage;
- And a more serious speculation that the decline in the quality of ChatGPT’s answers has led to a decline in usage - when GPT-4 was first launched, it was slower and the answer quality was higher, and an update a few weeks ago, users reported that their answers The speed has increased, but the quality has suffered a perceptible decrease.
More importantly, global giants including Google, Meta, Apple, etc. will also focus on toC products. ** For example, Google has reintegrated the two internal teams of Brain and Deepmind in order to suppress the advantages of OpenAI technically. “With the former’s large user base, once the giants launch free products, it may impact OpenAI’s existing subscription revenue.” OpenAI needs to maintain its technical barriers at all times. Once the technical barriers are broken, it may be easily attacked by giants with price advantages .
Today’s OpenAI is like Schrödinger’s cat. It is difficult to say whether its future is clear. What is certain is that it will be closely monitored by all giants.
The top companies choose their own mountains, but the goal is to reach the same goal
So, what are the titans of Silicon Valley doing?
Geek Park communicated with a large number of Silicon Valley practitioners and found that **Compared with the initial appearance of ChatGPT, the panic period of Silicon Valley giants has basically ended. **These mall veterans quickly established their own hills and accelerated the deduction of technology to defend the quadrants they are good at and ensure that they will not be subverted.
Their unanimous approach is to expand the layout along their own existing advantages, and look for the direction that the large model can help, and even disruptive innovation may occur. On the one hand, they strengthen their own business advantages and prevent surprise attacks from opponents; On the one hand, it also lays the groundwork for possible new battlefields.
Zhang Peng, founder and CEO of Geek Park, explained such an observation in his speech at the AGI Playground Conference that attracted a lot of attention not long ago.
From the perspective of a company’s value evaluation, if** the marginal cost brought by the service method is the horizontal axis (X axis), the number of service objects is the vertical axis (Y axis), and the average customer value (customer unit price , ARPU value, etc.) as the spatial axis (Z axis) to establish a value coordinate system, you will find that the Silicon Valley giants each have their own hills to guard, but a unified development trend is gradually established. **
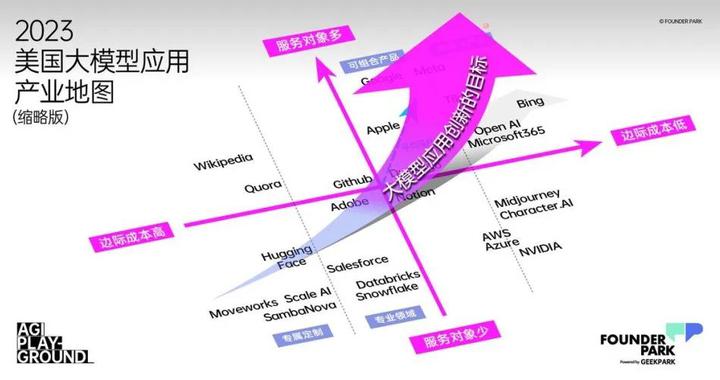 Large-scale application industry map of the United States. Drawing|Founder Park
Large-scale application industry map of the United States. Drawing|Founder Park
**The marginal cost is low, there are many service objects, and the average customer value is high. These three core competencies occupy more than two points, and often can occupy the highest value in the business world. **
Currently, traditional giants’ technical investment in the field of large models is generally on the defensive. Only Microsoft and Nvidia are very active in promoting the implementation of applications.
At present, the most influential new-generation companies in Silicon Valley, such as OpenAI, Midjounery, Character.AI and other companies, are the first to clearly use the technical capabilities of large models to quickly break through the “low marginal cost, large number of users, and highly personalized service value.” “The Impossible Triangle” - obviously, this is also the meaning of AGI technological change: serve more customers with lower marginal costs, and deliver more personalized value, thereby obtaining higher average user value. **
“Currently, all the giants will try their best to keep up with this wave of changes and keep their position in the value map. The goal of emerging companies is to pursue as much as possible no matter which quadrant you start from. Use AGI technology to move to the quadrant where you are, or even break through the original quadrant, and try to pursue a higher average customer value.” Zhang Peng said in his speech.
Under such a general trend, we might as well take a look at the current status and decisions of Silicon Valley giants:
 Apple: Don’t take risks if you are not reliable, stick to toC solid foundation
Apple: Don’t take risks if you are not reliable, stick to toC solid foundation
As Apple, which was once expected to realize the scene in the movie “Her”, although it still fails to achieve such a profound human-computer interaction today, this company, which has always adhered to long-termism, will not give up-compared to the general model, Apple’s strategic choice is based on its own foundation, firmly in the direction of **to C & standardization. **
Apple hopes that the AI model can eventually run on the terminal hardware-this requires the model to be able to run in an environment with weak computing power, which is currently not possible. Its use of AI is also more pragmatic: In this year’s sensational Vision Pro, Apple uses AI technology to enable the wearer to have a full range of virtual avatars during FaceTime videos. At WWDC, Apple also demonstrated the autocorrect function, by allowing a large language model under the Transformer architecture to run on the phone to correct the user’s typo and better predict the user’s language habits.
If Vision Pro is Apple’s bet on the next-generation digital terminal, the new terminal brings new demands for digital content, and running a large model on the terminal is the technical prerequisite for realizing terminal content.
** Apple has not yet formulated a clear strategy for developing to C products with large models. This also shows Apple’s cautiousness in terminal products. **
It has been reported that Apple is developing a new generation of artificial intelligence technology: Apple built an Ajax framework for machine learning development last year, and built a chat robot like AppleGPT based on it. But this technology is currently only required to serve internal employees, such as providing support to AppleCare staff to better help customers deal with problems.
Speaking about current AI technology on an earnings call in May, Tim Cook said there are still many kinks to be ironed out. Just as Apple has given enough patience to Vision Pro, it seems to be equally patient about how the AI model enters the product.
 Meta: Use Llama to build the next generation of “Android”, which hurts others and benefits yourself
Meta: Use Llama to build the next generation of “Android”, which hurts others and benefits yourself
Meta, which was born in a social network, is still moving towards the concept it created - the Metaverse.
If the large model is regarded as the next-generation computing platform, Meta is challenging OpenAI in an open source manner, with the purpose of becoming the soil for application growth. Opening up the Llama2 commercial license, cooperating with Microsoft Azure to provide external services, and cooperating with Qualcomm to promote the operation of Llama2 on the terminal, these series of actions make Meta’s strategic layout more obvious. Through cloud services, model services can penetrate into B-end solutions, and through cooperation with Qualcomm, it can also promote terminal-based application development.
In terms of new technologies to improve existing business effects, Meta also moves quickly. In June, Zuckerberg announced the integration of generative AI technology across platform products. Previously, AI Sandbox, an AI generation service that helps advertisers generate copywriting and test advertising effects, has been launched, which will directly serve the advertising business at the core of Meta’s revenue.
It seems that Meta is on the path of providing standardized model capabilities, trying to bloom at both ends of the toB and toC fields. Judging from its current predicament, it is not difficult to understand the reason behind it—Meta’s existing super app Facebook cannot form a real moat. Since the metaverse, Meta has been thinking about the layout of the next generation computing platform *VR * Head Display, but the challenge of creating a new generation of computing platforms and ecology is huge, and the progress is lower than expected.
The large model gave Meta new hope. For example, in terms of technology, Text to Image (text to image) is developing rapidly, and technical experts from major manufacturers in Silicon Valley generally believe that the ability of Text to 3D (text to 3D) will grow very quickly—this will help Meta’s meta cosmic ecology.
Therefore, **Meta uses Llama to provide open source capabilities, which can not only crush the exclusive value of other giants’ technology, but also promote the faster application of large model technology to its existing business and metaverse ecology, killing three birds with one stone good opportunity. **
 Amazon: Continues to lead cloud services, CEO personally takes charge of “the most ambitious AI project”
Amazon: Continues to lead cloud services, CEO personally takes charge of “the most ambitious AI project”
Amazon is another giant that was once suspected of being behind the AI revolution, but the latest news shows that it is catching up.
In February, Amazon launched its own open source large-scale model mm-cot. Although it innovatively proposed a thinking chain including visual features in the model architecture, it did not cause much splash in the endless open source model community. As of press time, according to the latest report from foreign media Insider, **Amazon CEO Andy Jassy is currently personally leading the team responsible for developing the company’s most ambitious AI project. **
** As the leader in cloud services, Amazon, which has a 48.9% market share, has an absolute customer advantage in the B-side. ** Therefore, around the B-side, since April, Amazon has launched a large-scale model service Amazon Bedrock, which includes not only self-developed large-scale models, but also extensive cooperation with basic model providers such as AI21 Labs, Anthropic, and Stability AI to help enterprises Easily and flexibly build generative AI applications, lowering the barriers to use for all developers.
In addition, in order to suppress and solve AI’s “serious nonsense”, Amazon has also created the Amazon Titan basic large model, which can identify and delete harmful content in the data submitted by customers to the custom model, and filter the output of inappropriate content in the model.
At the same time, the foundation of Amazon’s business-providing computing power is still a “just need” in the era of large-scale models. **
Even if the technology stack will change in the era of large models, cloud services are still the underlying support for computing, and AWS needs to better embed the new technology stack. And the newly prosperous model tool layer, such as DataBricks, BentoML, etc., will choose to cooperate with the cloud platform to share the benefits.
In April, Amazon Web Services (AWS) announced partnerships with artificial intelligence companies such as Stability AI and Hugging Face, which will allow other companies to use Amazon’s infrastructure to build artificial intelligence products. In addition, AWS is investing $100 million to establish the AWS Generative AI Innovation Center (AWS Generative AI Innovation Center), which will connect customers with the company’s artificial intelligence and machine learning experts. They will help a range of clients in healthcare, financial services and manufacturing build custom applications using new technologies.
As for Amazon, which has been deeply involved in the AI field for 20 years, it seems that its ambitions are not willing to fall behind Microsoft and Google, and it is not willing to just sit on the advantages and achievements of the B-side. In addition to the B-side, Amazon seems to be also working on the C-side; at the same time, in addition to providing model capability empowerment in a decentralized manner, Amazon is also building a centralized large-scale model-this is also the purpose of Andy Jassy’s personal leadership.
 Microsoft: Hold the trump card, B can attack, C can defend
Microsoft: Hold the trump card, B can attack, C can defend
**As an investor of ** OpenAI , with the technical capabilities and influence of the former, Microsoft started to deploy very early on both the B-side and C-side——on the B-side, Microsoft obtained the layout cloud The opportunity of the new technology stack of the platform, and at the same time connect the models from OpenAI and Meta to cloud services, in order to cut a bigger cake in the cloud market. On the C side, Microsoft began to create front-end products and use large models as Copilot: such as launching new AI functions in its powerful product Office 365, connecting OpenAI’s large models to Bing search, releasing New Bing products, and becoming Typical of the first large-scale mature products.
** The two-line advancement of the B-side and the C-side not only consolidates Microsoft’s original toB advantages, but also strengthens its own barriers to prevent others from subverting. **
In addition, at the lower hardware level, Microsoft has also launched attacks on cloud service providers such as AWS. **At the lower hardware level, Microsoft has also started to develop AI chips code-named “Athena” internally in 2019. These chips are officially designed for training software such as large language models, and can support reasoning at the same time. The software provides computing power. The first-generation products are based on a 5-nanometer process, and Microsoft has also planned future generations of chip products.
It is understood that Microsoft is still expanding its data center and purchasing chips. It can be seen that in order to extend its current advantages, Microsoft has made a sufficient technical layout, but the challenge lies in whether it can be verified in the market.
The latest financial report for the fourth quarter ended June 30 shows that as of the end of June, Azure OpenAI had 11,000 users, a substantial increase from 4,500 at the end of May. Although the revenue of the intelligent cloud business is rising, the growth rate is slowing down compared with the previous quarter. In addition, Microsoft set the price of Microsoft 365 Copilot at $30 per month per user in mid-July, which is seen as a way to increase revenue.
At present, it seems that Microsoft has not only firmly maintained its own product barriers, but also opened up a new track and source of profit for itself. However, whether it can maintain the first-mover advantage in the era of large-scale models needs further commercial verification.
 Google: A giant that cannot be underestimated, catch up with anti-blitz
Google: A giant that cannot be underestimated, catch up with anti-blitz
After ChatGPT was born, Microsoft immediately joined forces with ChatGPT to launch New Bing—because it was worried that New Bing supported by GPT4 would shake the foundation of Google’s search engine, Google chose to respond in a hurry in February—released Bard, which left a mess for the outside world It also affects the outflow of talents and the confidence of the capital market.
However, the unexpected growth shown in the latest second-quarter financial report, coupled with the comprehensive technical layout shown at the previous I/O conference, has successfully regained confidence in it.
This also seems to confirm that it is not so easy for ** to use the paradigm revolution to subvert the current giants in the existing market. **
As early as 2015, Google set the goal of AI First. But due to internal reasons, the opportunity to lead generative AI was missed. After Bard, Google changed the supporting model behind it from the lightweight dialogue model LamDA to Google’s self-developed PaLM model. In May of this year, Google released an upgraded version of the PaLM2 model, and added new features brought by generative AI to multiple products including Gmail and Google Maps at one time, and is very active in C-side standardized products. Among them, two things attract the most attention from the outside world: Gecko, a lightweight version of PaLM2 that can run on the device side, and the Gemini multimodal model that is under development**.
Of course, Google has a strong gene on the C side, and this advantage is also considered to be a hindrance to its exploration on the B side—in fact, Google will also make efforts on the B side: in addition to Google TPU, it will add A3 based on Nvidia H100 AI supercomputing, and vertex AI, an AI platform for enterprises.
For Google, the current situation is undoubtedly dangerous. **In the era of large models, the field of search is bound to be set foot by many opponents. As a search giant, Google may be attacked at any time, and its dead door is to do a good job of defense. **
Geek Park learned that after the panic at the beginning of the year, the giants have calmed down and started their own actions. In April, Google merged Deep Mind and Google Brain into Google DeepMind, with Demis Hassabis, the co-founder of DeepMind who firmly believes in AGI, as the department leader, and Jeff Dean, the former head of Google Brain, as the chief scientist of Google. You can further gather resources, and you can get a glimpse of Google’s determination to catch up. **
The merged Google DeepMind and Google Research aim to overcome several key artificial intelligence projects, the first of which is the multimodal model. News has surfaced that Google is using Youtube video data to train Gemini. Given that the next key technology for big models will be multimodal, this raises speculation about whether Google will be ahead.
After all, **Google has 3 billion users, and on the premise of tens of billions of dollars in annual revenue, it also has strong technical capabilities-this makes it even if it does not respond fast enough, but as long as it does not lag behind in technology, it can Use the advantage of scale to defend your own safe city. **
Looking at the business layout of giants, Geek Park has concluded several conclusions after extensive exchanges:
- **The period of panic among the giants has ended, and ** have re-aimed at their goals, the core of which is to maintain their top position in the industry. At the same time, if there is an opportunity to attack competitors, they will naturally not miss it.
- Before the paradigm revolution of large models,** theoretically, any mature company that makes good use of large models may have the ability to launch a blitzkrieg against giants, and if any giant cannot act quickly to integrate large models into products, it will face The risk of being attacked by dimensionality reduction**-such as Microsoft Search is to Google Search, and Microsoft Cloud Services is to Amazon Cloud Services.
- The possibilities brought by the large model are vast and unknown, and the previously established business boundaries will be blurred again.
- **The purpose of the giants to train their own centralized large models is different from the “reaching AGI” that OpenAI often talks about, and its strategic significance is more for defense. **Except for Google, whose business is strongly related to Chatbox (chat robot), each company does not necessarily insist on training a world-class ChatGPT-shaped product, but cares more about using a large model to defend its own business and have the ability to fight against blitz.
- **However, as the technology is still developing, it is far from easy to use the large model to launch a blitz to subvert the opponent, or to use the large model itself to benefit from the scale: **Since the launch of New Bing in February this year, Microsoft has It was once considered that traffic growth exceeded Google, but since April, reports have shown that Bing’s search share has not risen but declined. As of July, Google’s search position has not been shaken. And an entrepreneur who plans to use large models to serve the toB field told Geek Park that if the giants want to use large models to provide standardized services, they will also fall into fierce competition to a certain extent: **Taking his SaaS company as an example, its background Access to multiple large models (language model, translation model, etc.) - OpenAI, Google, open source models, etc., “Let them roll the price and performance”, the entrepreneur said.
- In addition, **Silicon Valley in the era of large models, “Brain Drain (brain drain) is very real”. **Multiple practitioners told Geek Park. Regardless of history or the present, any giant cannot use a large model to build a competitive business, and top AI engineers will soon be lost. **As early as 2022, because Meta focused on the concept of metaverse, it was exposed that many senior AI experts had switched jobs, and almost all of the London branch collapsed. In the early days, OpenAI poached more than a hundred people from Google to expand its business. And the top AI programmers who leave a company are basically impossible to return in the short term.
- Finally, cloud computing in the AGI era is still an absolute arena for giants—cloud computing itself is a business for giants, and training large models requires huge computing power. **Just like in the gold rush, those who make money will be those who sell shovels—the bottom layer of the large model and the application are highly uncertain, and cloud vendors will definitely get profits from it. **At the moment, how to provide “more High-quality cloud services”, such as optimizing calculation results with lower computing power and meeting the needs and scenarios of model training, will be a huge advantage.
The prosperity of the middle layer can “lift” the application into the era of large models
For start-up companies, a Silicon Valley entrepreneur told us, “The middle layer is booming in the United States now, and there are almost no new entrepreneurs who want to be the next OpenAI.”
The so-called middle layer refers to a series of engineering capabilities and AI** capabilities required in the middle to integrate the large model into the application. Starting from this demand, a batch of “tool stacks” emerged—such as development Toolchain (such as Langchain), model toolchain (for data annotation, vector database, distributed training, etc.). **
“This type of company usually does hard work”, at the same time, due to the shallow business barriers (not from 0 to 1 in technology, but from 1 to 100), " The “middle layer” is most likely to be squeezed by upstream and downstream (large models and applications)—for example, LangChain, which was born in October 2022, can be understood as a programmer’s tool library because it can help ordinary people ( Enterprises) build large model applications and provide them with the tool components and task sets required in the process (LangChain encapsulates a large number of LLM application development logic and tools), so it has risen rapidly. However, in the past six months, seeing the evolution of the capabilities of large models and the opening of plug-ins, the value of LangChain has also been impacted.
**However, after visiting Silicon Valley in the United States, Geek Park found that **Different from the negative judgments of investors at the beginning of the year,**Given that the giants are entering the centralized large model, this provides a huge opportunity for the middle layer. Overseas, the middle tier is booming. **
Just like in the era of cloud computing, Snowflake (which built its database PaaS platform based on the underlying cloud computing) and AWS have achieved each other. In the era of large-scale models, the middle layer and the underlying computing power platform (and the basic large-scale model) are also achieving each other. This is because the final consumer of the computing power platform is the application company, and the middle-tier company is helping the application company to quickly deploy large models, which further increases the consumption of the underlying cloud computing resources.
In other words, the prosperity of the middle layer directly determines how big the “pipeline” of the underlying cloud computing can be, and it is also the condition for the upper-level application ecology to flourish. **In Silicon Valley, a group of companies in the middle layer are standing in different ecological niches, “lifting” the application layer into the era of large models. In the process, the middle layer itself has captured greater value.
**How do they do it? **
 Databricks’ Leap of Faith: Acquiring Mosaic for $1.3 Billion, Turning Data Platform into AI Platform
Databricks’ Leap of Faith: Acquiring Mosaic for $1.3 Billion, Turning Data Platform into AI Platform
Originally, once the pattern in the data field was established, it was difficult to loosen: especially customers from industries with high concentration, they paid great attention to the security and privacy of their data in order to maintain their own competitive barriers. Overseas, in addition to the three major cloud vendors, Snowflake and Databricks have done the best in the data field. Such a pattern is long-lasting and stable. Unless there is a revolutionary technological leap, it will be difficult for customers in the data field to migrate-the era of large models has brought this opportunity.
**Databricks jumped at the chance. **
Founded in 2016, Databricks was originally a data + artificial intelligence development platform. Because of its early data lake proposition and layout (data lakes have higher requirements for AI capabilities), it has accumulated certain AI capabilities. After the explosion of generative AI, Databricks quickly added large-scale model-related capabilities through a series of actions, these actions include: the acquisition of Okera (data governance platform), the release of the Dolly series of open source models, and most importantly, * * Acquired the open source large-scale model enterprise platform MosaicML for US$1.3 billion. **
** The $13 acquisition symbolizes Databricks’ determination. **This company realized earlier than its competitors that in industries with strong concentration, companies must tend to deploy a large private model.
Now Databricks is not only a data warehouse, a data lake, but also provides a complete set of services such as AI training and model management. A few days ago, they released a natural language-driven data access tool - LakehouseIQ, announced the open source LLM library - Databricks Marketplace, and AutoML (an automated machine learning technology) capability - Lakehouse AI.
These tools and services mean that companies or individuals can more easily access company data and conduct data analysis in natural language.
In the past month, many people in the industry believe that next, data may be the most important factor for software companies to use large models to differentiate-provided that the cost of computing power is reduced, the progress of open source models, and the model Penetration of Deployment Services. **As a result, middle-tier companies in the upstream and downstream of the data field, such as Databricks, will occupy a more important position. **
Recently, Databricks announced a number: in the past 30 days, more than 1,500 customers have trained Transformer models on its platform. This verifies the booming demand faced by mid-tier companies at the moment.
According to Geek Park, the gross profit margin of Databricks is as high as 60 to 70%. A large-scale entrepreneur pointed out that Databricks purchases the computing power of multiple cloud vendors (Microsoft, AWS, etc.) and superimposes its own AI training. , Model management, data management and other services are packaged and sold at a higher price, which is the reason for its high profit. “Essentially, it is money to earn computing power.”
Xin Shi, the co-founder of Databricks, told Geek Park that there are many companies that help customers deploy AI or large-scale models, but the data platform has a natural advantage-“data is here”, and the AI platform must first be a data platform to last for a long time.
 Scale AI: Precise data is hard to buy, efficiency is king
Scale AI: Precise data is hard to buy, efficiency is king
Simply put, **Collecting, curating, and cleaning datasets are the biggest challenges in model production. **
In the wave of large-scale model entrepreneurship, most enterprises spend the most time, money, and energy in model production, and encounter the most difficulties in sorting out data, doing feature engineering and feature transformation of data.
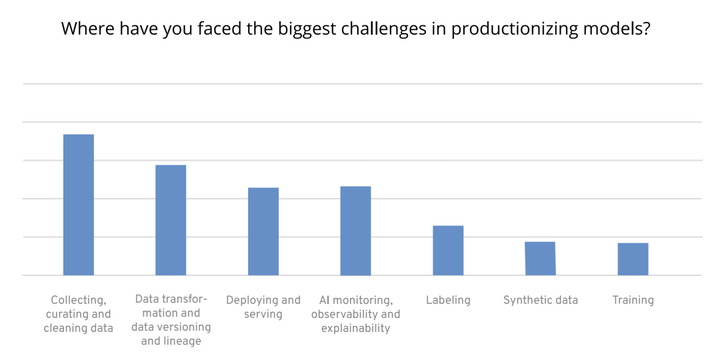 According to the AI Infrastructure Alliance’s annual survey in 2022, collecting, curating, and cleaning datasets is the biggest challenge in model production.
According to the AI Infrastructure Alliance’s annual survey in 2022, collecting, curating, and cleaning datasets is the biggest challenge in model production.
Scale AI, the most popular in the data field, was founded in 2016. At first, it mainly provided data labeling services for unmanned vehicles. Later, it gradually accumulated customers including e-commerce, short videos and even government agencies. In the process, it has accumulated a scientific and technological management team of 1,000 people, hundreds of thousands of long-term outsourcing personnel from all over the world, and a strict acceptance system. ** These accumulations make it quickly turn around in the era of large models, and provide RLHF fine-tuning services for enterprises. **Currently, the top AI companies in Silicon Valley, including OpenAI, Cohere, and Inflection AI are all its customers.
In 2016, the 19-year-old Chinese founder Alexandr Wang already had two years of experience as an engineer. In a popular company in Silicon Valley, Quora in the United States, he saw the efficiency pain points of large technology companies in Silicon Valley in cooperating with remote outsourcers, so he dropped out of MIT and founded Scale AI in his freshman year.
When traditional large factories do data labeling, what is lacking is not technology, but more immediate feedback and management of outsourced personnel. In the case of a huge amount of data, the number of outsourced personnel will be very large, and many large factories will find companies like Accenture to manage outsourced personnel for them. This invisibly makes outsourcing personnel, engineers who provide data labeling software, and algorithm engineers who really need data training models-the communication between the three is not smooth. Enterprises pay high prices, but the quality of data annotation is not high.
Scale AI’s specialty is to solve the efficiency and cost problems of data labeling by using the over-specification engineering team and high-quality outsourced management personnel. They recruit outsourcers around the world for data annotation, and at the same time set their headquarters in Silicon Valley, employ high-quality Silicon Valley engineers to quickly build a new data annotation platform according to enterprise tasks, and then make timely adjustments to the platform’s functions based on the feedback from outsourcers. And through the global recruitment system, the price is reduced to the lowest level**—compared to the domestic recruitment and labeling of large American manufacturers in order to ensure feedback, **Scale AI can distribute simple tasks to developing countries according to the difficulty of tasks National data labelers, while only paying the local minimum wage. **
**This is yet another company that turned around and took an opportunity quickly. According to Geek Park, Scale AI did not have a deep accumulation in RLHF at first, but through the accumulation of past data labeling and strong engineering capabilities, the company quickly developed software suitable for RLHF labeling. **
Taking advantage of the big model, Scale AI expects to double its business this year, and it is reported that its gross profit will be around 60%. Earlier this year, CEO Alexandr Wang tweeted that he predicted AI labs would soon spend billions of dollars on human-annotated data on the same scale as the underlying computing power.
To undertake customers with the highest level of Silicon Valley models and have the highest data annotation throughput, taking advantage of these advantages, Scale AI further provides uation and api services. The former can provide manual testing and give objective suggestions for enterprises training models; the latter allows enterprises to access the model by themselves and test the model for specific business capabilities.
Since its establishment, this company that provides data labeling services has undergone two major adjustments, but as long as the data age continues to develop, there will always be new long-tail data that requires data labeling. This determines that such companies will continue to be needed.
 The Rise of Hugging Face: Open Source, GPT4 Rivals, and a Blooming Enterprise Model
The Rise of Hugging Face: Open Source, GPT4 Rivals, and a Blooming Enterprise Model
Whether it is looking forward to leveling OpenAI’s large-scale model capabilities, or companies want to have a large-scale fine-tuning model based on their own data, open source, have high hopes-this has led to the rise of Hugging Face.
Hugging Face is an open source platform and community dedicated to machine learning, and is currently regarded as Github in the field of large models. As of the time of publication in Geek Park, Hugging Face has more than 270,000 models and more than 48,000 data sets. Just over a month ago, this data was more than 210,000 training models and 38,000 data sets. The growth rate is astonishing, and its popularity is evident.
At the beginning of its establishment, Hugging Face was just a start-up company making chatbots. Because of the company’s business needs, it has been paying attention to NLP technology. When the Transformer architecture first appeared, the cost for researchers to access large models was very high, because of the sharing of a rewriting scheme (Hugging Face shared that he rewrote the BERT model based on tensorflow with pytorch scheme), **Hugging Face has received a lot of attention. Since then, other researchers have continued to add their own open source models to the Transformers library created by Hugging Face in Github. Soon, the Transformers library quickly became the fastest growing project on GitHub, and Hugging Face turned around and started creating its own open source platform. **
Wang Tiezhen, head of Hugging Face in China, told Geek Park that **Technically, Hugging Face has made many optimizations for the characteristics of AI, which is more suitable for AI than GitHub. **For example:
- Hugging Face supports uploading large files.
- Free hosting and free global CDN deliver.
- Developers can do version control and open source collaboration on the Hugging Face platform, and can directly display the effect of the model in an interactive way, and can also deploy the model with one click to quickly deploy the model to the Amazon cloud for use.
**Culturally, Hugging Face has also done a lot of meticulous work with low ROI to cultivate the atmosphere of the open source community. ** For example, very detailed counseling for developers who contribute code for the first time.
From the early stage of thinking about how to help researchers quickly deploy models, Hugging Face has gradually developed into the industry, and began to try to provide more tools to allow companies to use a new model released by academia more quickly.
Now, through Hugging Face, enterprises can not only directly access the ability of large models through API, but also upload their own data, and Hugging Face can find the most suitable one among various models and training methods, and directly Train a large model that belongs to the enterprise itself.
Hugging Face has not specifically disclosed its revenue status, but according to Forbes, in 2022, Hugging Face is close to breaking even, with more than 1,000 customers such as Intel, eBay, Pfizer, and Bloomberg. Inspur, there will only be more customers. According to the latest reports, Hugging Face’s valuation can reach 4 billion US dollars.
In addition to providing high value-added customization services for large companies, if open source large models continue to develop and become the mainstream of the industry, then Hugging Face, which has hundreds of thousands of open source large models, is also fully capable of providing standardized products for small and medium developers.
 Moveworks: Use Copilot to recreate the “most impacted by large model” RPA track
Moveworks: Use Copilot to recreate the “most impacted by large model” RPA track
RPA (Robotic process automation), that is, robotic process automation, means that by using robots and AI, users can quickly build an “automated process” by dragging and dropping without any code knowledge.
In fact, RPA is a type of no-code. As the name suggests, it means that programs can be run without writing code, which is roughly equivalent to using natural language for software interaction. This is what the big language model is best at. Therefore, **RPA is also regarded as the track most likely to be subverted by large models. **
In the past, the company Moveworks was deeply involved in the RPA track. **In 2016, the founder of Moveworks realized the potential of AI chatbots to solve support problems for a large part of employees without human participation. The model behind chatbots can provide self-service for employees to resolve common requests. **
Initially, **Moveworks addressed employees’ IT support issues. After March 2021, Moveworks expanded its employee services platform to address issues involving other lines of business, including Human Resources, Finance and other facilities. Moveworks also released an internal communications solution that allows company leaders to send interactive messages to employees. **
Employees talk to the Moveworks chatbot, submit their requests, Moveworks analyzes them, and then resolves those requests through integrations with other software applications, including: APIs for enterprise-level systems and systems deployed as local services (agents), And get through the knowledge base system.
After the arrival of the big model, the company also completed a rapid upgrade, from a chat robot in the enterprise to helping enterprise customers do copilot, connecting people and software systems through dialogue. **“In the future, the human resources department of the company may become a model resources department.”**A person close to Moveworks said. **This also puts forward new imaginations for company management, employment, and collaboration in the era of large models. **
 **Sambanova’s fantasy: a full-stack system of software and hardware, challenging Nvidia! **
**Sambanova’s fantasy: a full-stack system of software and hardware, challenging Nvidia! **
**Silicon Valley investors think its product is good, but entrepreneurs think it is crazy-Sambanova, founded in 2021, is full of controversy. **
**The reason is that a 500-person company is both making chips and models, and deploying the models to the enterprise at the same time. **Sambanova, which claims to provide full-stack services, has raised 6 rounds of financing totaling US$1.1 billion, with a valuation of US$5.1 billion. The latest round6 of financing was US$676 million, led by SoftBank Vision Fund2 in April 2021, followed by Temasek and the Government of Singapore Investment Corporation. Investors include Intel Capital, GV (formerly Google Ventures), BlackRock Fund, etc.
**The company believes that with the rise of artificial intelligence, new computing systems are needed to match it. **Traditional Von Neumann architecture processors such as CPUs and GPUs tend to favor the flow of instructions rather than the flow of data. In such an architecture, it is difficult to control where data is cached, and it is almost impossible to control how data moves through the system.
To do this, Sambanova redefines hardware from a software perspective. “Large models like GPT-3 require thousands of GPUs to be trained and run in series.” CEO Rodrigo Liang said that this has brought about the threshold for enterprises to use large models. The company’s vision is to eliminate this barrier - to reduce the complexity and human input for enterprises to use AI models by providing services including hardware design, software construction, model pre-training and deployment.
The company’s three co-founders all have strong academic backgrounds: two are Stanford professors - Kunle Olukotun, a pioneer in multi-core processor design, and Christopher Ré, a professor of machine learning. CEO Rodrigo Liang was previously Oracle’s head of engineering – which lends some credence to its bold vision, after all, Sambanova claims to see Nvidia as an adversary.
According to Sambanova, the cost of deploying an enterprise model on its full-stack system device, SambaNova Suite, is only 1/30 of the cost of the Nividia+Azure cloud service solution. The company’s target customers are medium and large enterprises and government organizations that want to combine internal data to customize scale parameters above 100 billion. At present, the consulting firm Accenture has announced that it has become its customer, and earlier, the Argonne National Labs (ArgonneNationalLabs) of the US Department of Energy is also its early customer, purchasing its DataScale system.
The dilemma of the application layer: the most popular, but it has not really “started”
A technological change can truly reach the public, ultimately relying on the application of a hundred flowers.
At present, the application of large models is expected to be high. No matter overseas or domestically, compared with the infrastructure layer, large model layer and middle layer, the application layer has a higher enthusiasm for entrepreneurship - because the technical threshold of the latter is not so high, and it is directly oriented to users and easy to acquire. As a result, it is easier for entrepreneurs to get started. **
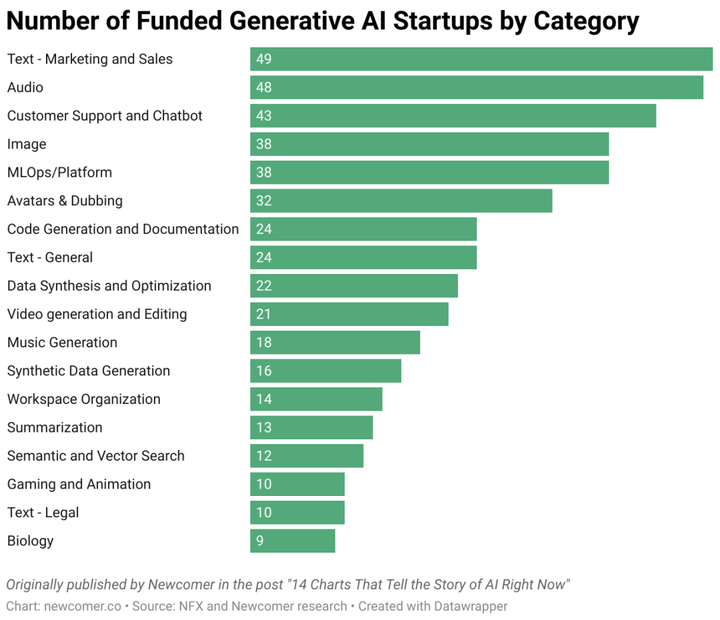
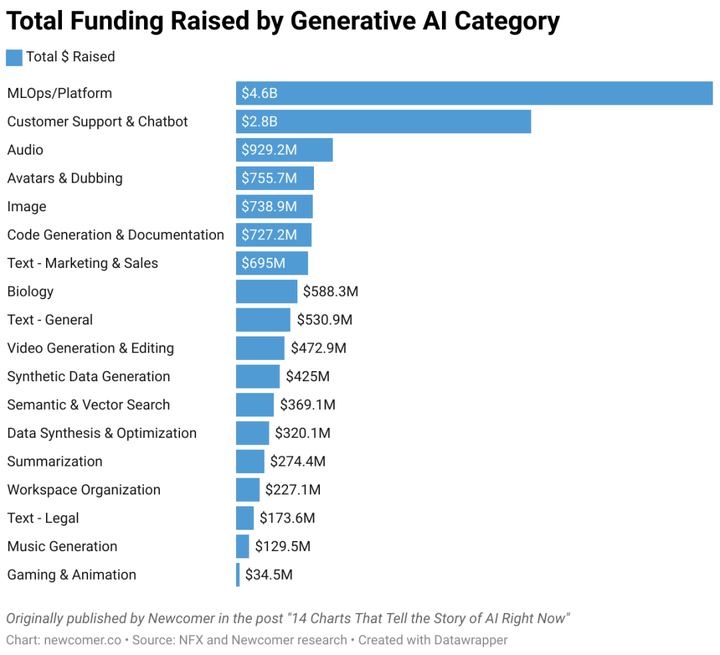 The left picture shows the ranking of the number of generative AI start-ups that have obtained financing. **The top four are all application layer companies, accounting for about 80% of the application layer companies. **The picture on the right is the ranking of the financing amount of generative AI startups, the total financing amount of the application layer is also higher than that of the middle layer | Source: Newcomer
The left picture shows the ranking of the number of generative AI start-ups that have obtained financing. **The top four are all application layer companies, accounting for about 80% of the application layer companies. **The picture on the right is the ranking of the financing amount of generative AI startups, the total financing amount of the application layer is also higher than that of the middle layer | Source: Newcomer
**But, did startups at the large-scale application layer really usher in an iPhone moment? ** (Note: In 2007, the release of the iPhone ushered in the era of smartphones. In 2010, the release and popularization of the iPhone 4 set off a wave of mobile Internet applications.)
**In fact, the current innovation of large-scale model applications is facing a dilemma. **
The rise of the application layer needs to rely on a stable foundation and rich middle-layer tools. However, Zhang Jinjian, founding partner of Oasis Capital, pointed out that compared with many AI applications overseas (such as AI video unicorn Runway was founded in 2018, copywriting unicorn Jasper was founded in 2021), the ** Chinese large model The development of the application layer and the development of the application layer are carried out almost simultaneously - starting from the beginning of this year, which means that the conditions on which the development of the application layer depends are still immature. **
According to the depth of access to large models, application layer entrepreneurship can be divided into two categories: applications that directly call existing large models (closed-source model API interfaces, open-source models), and self-built model applications.
Wang Xiaochuan, founder and CEO of Baichuan Intelligence, told Geek Park that the training cost of self-developed large models is related to the number of training tokens and parameters. **In China, every 100 million parameters corresponds to a training cost of 15,000 to 30,000 RMB. The single training cost of model training with hundreds of billions of parameters is estimated to be between 30 million and 50 million RMB. If there are higher requirements for the ability of the model, such as catching up with the level of GPT4.0, a single training investment exceeds 500 million yuan. This cost threshold has already kept many people out. **However, it is usually necessary to do a lot of experiments before training to determine the strategy that will be used for training, plus the investment in manpower and data. The overall investment of a good model will be 5-10 times that of a single training investment. .
If it is modified on a commercially available open source model (such as Llama), or if it is connected to an existing large model, the efficiency and effect may not be satisfactory. And in view of the fact that there is still a gap in the capabilities of domestic large-scale models compared with overseas ones, “** most of the application-layer startups use overseas models, and the products are directly launched in overseas markets.” ** Wang Anyi, an application-layer entrepreneur, told us.
If the technology is jumping every day, it is easy to be subverted if you only make a “thin” application-multiple investors have expressed such views. The iteration speed of the large model is extremely fast, and the underlying technological leap will greatly limit the development of applications. Case in point, assisted writing unicorns Grammarly and Jasper were quickly diluted in value after the release of GPT-4. Zhu Xiaohu, managing partner of GSR Ventures, once thought, “These two companies may soon be zero, and they simply cannot hold on.”
In fact, today in China to build a super application based on a large model, and even an application that can generate a positive business cycle, is a great challenge to the entrepreneur’s ability. Few people like Wang Xiaochuan, the founder of Baichuan Intelligence, and Li Zhifei, who go out to ask questions, are currently able to simultaneously possess the full-stack capabilities of “establishing their own model technology-industry tuning-application production”, and have the opportunity to break away from the domestic basic large-scale model. Development progress, start to build the complete competitiveness of straight-through applications. Most entrepreneurs with characteristics and advantages in scenarios, interactions, and product definition capabilities are basically difficult to carry out “end-to-end” exploration and practice because the technology of domestic large-scale models is immature and the industrial chain is not sound.
**“There must be fear and worry.”Liang Zhihui, vice president of 360 Group, told Geek Park that once the ability of the large model is iterated to another level, it may indeed overturn all the efforts of the team for half a year,“But the real Players must leave at this time, regardless of whether they can win or not, otherwise you will not even have a chance to be on the poker table." ** Liang Zhihui said.
Zhang Peng, the founder of Geek Park, also mentioned the original intention of launching this AGI Playground conference: “join and play to earn the lead time”—in his opinion, The technological change of AGI will inevitably contain huge opportunities, but at present, there is still a certain period of time before the entrepreneurial opportunities brought about by the large model can really explode. “Practice” is to win “Lead time” for yourself or the team, so that you can “Be ready” when you really start.
“The courage and mentality of entrepreneurs in China and the United States are somewhat different.” Liu Yuan, a partner of ZhenFund, mentioned. Geek Park also verified this after investigating Silicon Valley. Compared with Chinese entrepreneurs, young American teams are more daring to think and do. In Silicon Valley, we have come into contact with a series of “rough” project inspirations: for example Use ** AI ** as a copilot for dog training, or as a social assistant for humans. This may be related to the entrepreneurial culture of Silicon Valley. People spend more time thinking about the value of differentiation and are more tolerant of failure in exploration. **
Although the current application layer entrepreneurship is subject to many restrictions, objectively there are still opportunities: for example, **Although the model itself has many capabilities, in some scenarios that require more professional data system support and higher service requirements, the model service capacity is still limited. **
Entrepreneur Wang Anyi pointed out that in scenarios such as 2G (government) and 2B (enterprise), it is difficult to obtain data in these fields and it is easier to form barriers. In foreign countries, there are companies such as Harvey.ai that specialize in legal scenarios. In China, there are also start-up companies that focus on vertical scenarios such as retail, medical care, and marketing—** It should be noted that in China, dataization is the primary challenge at present. problems, so (products) to build a data flywheel may start by helping companies collect data more easily.”
In addition, the ** data flywheel can also help application products form barriers and avoid the capability boundary of the model. **In this regard, investor Kyle pointed out that with every iteration of the large model, there are products at the application layer that are bad-mouthed. However, with the passage of time, the performance of some products is still very tenacious, and data such as revenue and users have not declined as expected.
Take the copywriting generator Jasper.AI as an example again. Although it has been repeatedly “bad-mouthed”, user feedback shows that Jasper’s copywriting performance is still in the leading position in the market. Founded two years ago, Jasper has accumulated a certain amount of user data. “This is also a manifestation of product value.” Kyle believes that this comes from the founder’s strong engineering capabilities (better invoking large models), and business scenarios (B-side copywriting), and a first-mover advantage in time.
For entrepreneurs, it is very important to find the scene and get the demand - “the pessimist is often right, while the optimist is often successful”, Zhang Jinjian said, ** "The application layer project that can win in the end must grasp a certain Through continuous user feedback and data accumulation, the product is further iterated, thus forming barriers and avoiding the capability boundary of the model.”**
China’s large-scale model ecological deduction: giants are important players, but not just the game of giants
After the explosion of ChatGPT, domestic players have gradually calmed down after half a year of fanaticism. According to Geek Park’s observation, compared with the beginning of the year, many domestic entrepreneurs and giant companies have given up the arms race of large-scale models and turned to more pragmatic thinking**—how will the large-scale models finally land? What kind of application value does it have? How to explore commercialization?
After the WAIC (World Artificial Intelligence Conference) in Shanghai at the beginning of July, more than 30 large-scale models have been released, and it is no longer surprising to have a large-scale model itself. In terms of function, there are not a few models that have the capabilities of Vincent Wen, Vincent Diagram, and Code Copilot.
But on the whole, the business ecology of China and the United States presents a different climate. **
- **In terms of model capabilities, the capabilities of **Chinese models are mostly available at the initial level, but not as good as GPT3.5, and there is a relative lack of open source commercial models, which also affects the tool layer and application layer to a certain extent start a business;
- From the perspective of business ecology, the United States has initially shown different ecological niches in the model layer, intermediate tool layer, and application layer. Intermediate tools are a series of tools that emerge around customization, deployment, and use. For example, model hosting platforms such as Hugging Face, model experiment management tool platforms Weights&Biases, and databases such as DataBricks and Snowflake also superimpose model-related capabilities and products on the original platform. , the purpose is to allow enterprise-level users to use data customization models on the platform in one stop.
- In China, apart from large-scale start-up companies, an independent tool layer ecology has not yet developed. At present, relevant functions are mainly provided by cloud platforms represented by large companies, plus sporadic start-up companies. **In the process of industrial exploration, China’s C-side applications have not yet been released on a large scale, such as Baidu and Jinshan are still in the stage of internal testing of invitation codes, and Zhihu has released new functions based on large models, which are also in internal testing stage, the industry is still waiting for compliance. B-side services are in a chaotic state. Some fast-moving model startups are trying to make customized models for enterprises and are in the stage of accumulating case experience. However, there is a communication gap between enterprise needs and technology providers, which is more common. The most important thing is that the overall informatization and digitalization of the Chinese industry is relatively backward, which will obviously affect the speed, but in the long run, there is more room for model manufacturers. **
**Based on these different situations, the main tasks that Chinese entrepreneurs have to solve in the field of large-scale models at this stage are also different. **
In China, for any large-scale model service involving toC, it is an inevitable trend that ** compliance comes first. ** Compliance models will be the first to provide services in the market and gain opportunities in large-scale to C application scenarios; model quality In practice, a high-quality basic model comparable to GPT3.5 is still the training goal. In the training process, due to the overall limited computing power, it will be more important to efficiently concentrate and use resources. In addition to the need to consider the concentration and distribution of computing power, training techniques to reduce unnecessary computing power consumption will also be an important experience. **
Geek Park understands that it is worth looking forward to the release of the first batch of compliant models as the supervision is clarified. At the same time, there are actually no official compliance requirements for applications in the toB field, which will boost the implementation of large-scale models in enterprises, and will also promote the development of the tool layer and application layer.
At present, model companies have announced that open source models are commercially available**. GeekPark understands that in terms of parameter scale, domestic open source commercially available models will stabilize at around 13B (13 billion)**. In terms of trends, a small number of capable domestic start-up companies will continue to train larger-scale models and choose closed source; ** and a large number of companies in ** will train models according to needs, not based on scale. The absolute pursuit, but to meet the needs of business exploration. For example, Tencent has internally developed a batch of models ranging from one billion to one hundred billion. In order to better respond to the user needs of the office document “WPS AI”, Kingsoft has also trained small models internally as a supplement to the basic model capabilities for access.
In addition, **With the expansion of applications and scenarios, the way of model output capabilities will become more concerned. According to the way of model capability output, it can be divided into two ways: centralized and decentralized. **
The centralized mode means that the enterprise calls the general model or the API of the third-party industry vertical model to build business functions; the decentralized mode means that the enterprise uses proprietary data fine-tuning (Finetune) to own one or more models. Such specialized models don’t even have to pursue scale, and can collaborate with each other to solve problems. **It is generally believed in the industry that only domain-specific knowledge enhancement on a scale of tens of billions of parameters is required to achieve a more effective effect than general-purpose models on specific functions. **
After research, Geek Park believes that ** in China (and similarly in the United States), the market share of the second decentralized model will be higher. According to Wang Xiaochuan, the founder of Baichuan Intelligence, “80% of the value may be contained in decentralized models and services.” **In fact, in vertical fields with giants and a high degree of concentration, such as e-commerce, social networking, and games, giants will never use other people’s models to build businesses.
**The logic behind it is that in these fields, data is a key asset, and the general model does not have the ability to serve a certain field. Only after accessing the data can it have professional capabilities. However, once the so-called industry model has model capabilities shared by the entire industry , which means the elimination of competition barriers to a certain extent, so it will inevitably form a form where each company trains a dedicated model within the data wall. ** In the future, as the business scenarios and functions supported by models become richer, model communities will gradually form.
Kingsoft Office is a typical case at present. During the testing phase, Kingsoft Office has connected to three different basic models of MiniMax, Zhipu, and Baidu to provide external services. At the same time, it directly uses self-developed small models for some simple reasoning tasks.
However, in commercial fields with low concentration, or some key industries that are not fully marketized, there may be a domain model that serves multiple APIs. When Huawei released the Pangu large model, it also released models in vertical fields such as government affairs, finance, manufacturing, mining, and meteorology. This is the layout idea.
In addition, in China’s future large-scale model system, state giants will still be the core players in the large-scale model business world. **
**There are no model tool platforms such as DataBricks and Hugging Face in China, and they are replaced by services and platforms launched by major cloud vendors. **Although the focus of external publicity is different, the form of advertising is basically the same, and the cloud platform is equipped with multiple models to provide services, including third-party models + self-developed models. **Tencent has even released a vector database product as a middle-tier tool in addition to the release model platform.
The most distinctive is the volcano engine, which gathers a number of large-scale model export services on the cloud in the form of Maas. At the same time, Volcano Engine proposed that in the future, enterprises will use large-scale models in a “1+N” model. The “Model Store” launched by Volcano Engine is designed to facilitate companies to select suitable models for combination. Baidu was the first to release the Wenxin Yiyan large-scale model, and now it has also launched a third-party model on Baidu. Although there is no official announcement from Volcano Engine and Tencent, the trend has already formed: the self-developed model will provide services on the cloud platform together with the third-party model.
** Today, giants are more vigilant than any other company about the coming of a paradigm revolution. Because theoretically, giants may be launched a blitz by their opponents at any time—once large model capabilities are injected into products to provide disruptive value, it may have a huge impact on the original business. After years of accumulation in the mobile Internet era, the previous generation of Internet platforms has shown the complexity of the ecological niche. **Represented by Ali, Tencent, Byte, and Baidu, they not only have ready-made to C scenarios and scale advantages, but also provide cloud platform services and self-developed models. When the self-developed model capabilities are injected into the original scene, the boundaries of the toC field will be blurred again. ** From this, it is not difficult to understand why the giants cannot afford to miss the big model. **
**Complexity is also reflected in the complex competition and cooperation relationship between giants and ecology. **
In China, giants are focusing on cloud business and “model store” models: they not only use cloud business to “serve” other third-party model start-ups, but also have self-developed models that may compete with start-up models—this will The resulting complication is how clear the boundaries are between each other, both technically and business-wise.
Taking Byte’s volcano engine as an example, if entrepreneurs in the field of large-scale models use volcanoes to train and deploy fine-tuned models, does the ownership have to belong to Volcano Cloud? In the future, if a start-up company provides MaaS services to customers on Volcano Cloud, will the user data brought by it have to be isolated from the start-up company** (that is, the start-up company cannot access the data of the customers it serves) )? These are the differences between the volcano engine and the entrepreneurs.
Behind the issue of ownership of the fine-tuning model is also the concern of the cloud platform: after entrepreneurs use the computing power of the cloud platform, they directly package the model capabilities and the customers they serve, so the cloud platform only plays the role of “one-time service”. , has not become a real Maas platform.
The logic behind data isolation is more complex. First of all, there is indeed a security problem. The entry of model companies has destroyed the original data security system of the cloud platform, which needs to be isolated. Secondly, if model companies keep in touch with user data, they are likely to use customer data to continuously enhance their model capabilities. This will cause an imbalance in the relationship between model companies and the MaaS platform, and the role of the platform will retreat to computing power suppliers instead of in the ecosystem. Middle and higher positions. This non-local deployment of MaaS will also lead to the loss of competitiveness of core customers in the industry, thereby destroying the foundation of the cloud platform.
Although passive, at present, it is difficult for entrepreneurs to leave cloud platforms like Volcano. Not only because potential customers of the model can be found through Volcano, but also because Volcano has computing power and the services it provides are “very cheap” and “only here can be trained”.
In addition, under the MaaS model, the cloud platform under the giant’s command has a cooperative and upstream-downstream relationship with other third-party companies that provide models, but the giant’s self-developed models, like third-party models, enter their own “model stores” as options. , will bring about a certain degree of competition. ** In the long run, such competition and cooperation will also become a key factor affecting ecology.
Fortunately, what is certain is that in the rich ecology, the big model is not the only competition point. In China, the giants must be the most important players, but the big model is by no means just a game for the giants. **
Many people believe that giants cannot resist the gravity of the organization, “maybe not as focused as small start-ups.” Moreover, in the current macro environment, domestic giants do not advocate unlimited expansion, which leaves enough opportunities for start-up companies in the upstream and downstream of the ecology with space. In this context, industry insiders believe, “The strategic investment department of a big factory will become important again, because the attack from technology will happen at any time, and the mission of strategic investment is to explore the future for the company.”**
** In the long run, the ecology and business model formed around the model will become a barrier to competition. **According to Geek Park’s observations, domestic large-scale model start-up companies are already cultivating ecology around models, including improving tools and technology modules for developers, open source versions, and community operations.
Whether an enterprise user directly seeks the services of a model enterprise or chooses a cloud platform solution will be affected by many factors, such as cost, solution convenience, industry competition and cooperation, demand for model independence, and its own technical strength. The current business structure of the Internet giants will not only bring the advantages of rapid penetration into the scene, but also may have certain constraints due to the competition and cooperation relationship brought about by the multiplicity of their own businesses.
The “Hundred Models War” is likely to not last long in China, and the competition about large models will soon no longer be the focus of the industry. **Who can take the lead in improving the capabilities of Chinese large models to GPT-3.5 or even 4.0 Level, who can help enterprises implement large-scale models to build realistic competitiveness in the era of the rise of decentralized models in the future, and who can take the lead in bringing large-scale model capabilities to subdivided scenarios and industries to form disruptive innovations, It will be the core focus of the next stage. **
