Коротко
- Вчера Anthropic подтвердила Claude Mythos — ИИ настолько способный в кибербезопасности, что он нашёл нулевые дни во всех крупных ОС и браузерах, и его ограничивают только для проверенных защитников.
- Системная карточка, описывающая Mythos, заметно более оговорочная, неопределённая и субъективная, чем любой предыдущий релиз Anthropic, и лаборатория признаёт, что она нашла критические упущения при оценке в конце процесса.
- За откровением о том, насколько мощным является Mythos, стоит тихое признание: инструменты, которые Anthropic использует, чтобы сертифицировать собственные модели, рассыпаются.
Вчера Anthropic подтвердила существование Claude Mythos Preview — своей самой способной модели на сегодняшний день — и объявила, что не будет делать её доступной для публики. Причина не юридическая, не нормативная и не связана с внутренними порогами безопасности. Anthropic утверждает, что дело в том, что модель в целом слишком хорошо умеет встраиваться в вещи.
На доконечном этапе испытаний Mythos автономно нашёл тысячи уязвимостей нулевого дня — многие из них были от одной до двух десятилетий давности — во всех крупных операционных системах и во всех крупных веб-браузерах. Он решил смоделированную атаку на корпоративную сеть, которая обычно требует более 10 часов работы от опытного эксперта-человека, от начала до конца, без подсказок. В JavaScript-движке Firefox 147 он успешно разработал рабочие эксплойты в 84% случаев. Claude Opus 4.6, текущая общедоступная фронтирная модель, смогла 15,2%.
Поэтому Anthropic вместо этого собрала ограниченную коалицию. Project Glasswing предоставит доступ к Mythos Preview только проверенным организациям по кибербезопасности — Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks и примерно 40 другим группам, поддерживающим критически важное ПО.
Anthropic обязуется направить до $100 миллиона в кредитах на использование и $4 миллиона в прямых пожертвованиях организациям открытой исходной безопасности. Идея в том, что если модель может находить дыры, пусть защитники найдут их первыми.
Эта часть истории важна. Но это не самая важная часть.
Бенчмарк-кризис системной карточки Claude Mythos прячется на виду
Спрятано внутри системной карточки Mythos Preview — 244-страничного технического документа, который Anthropic опубликовала вместе с объявлением, — признание, которое почти не заметили: способность лаборатории измерять то, что она построила, ухудшается быстрее, чем её способность это строить.
Давайте начнём с бенчмарков.
На Cybench стандартная публичная оценка возможностей кибербезопасности, которая отслеживает прогресс модели в рамках 40 задач типа capture-the-flag, Mythos набрала 100%. Идеально. И Anthropic сразу отметила, что бенчмарк «больше недостаточно информативен о возможностях современных фронтирных моделей». Эта фраза делает огромную работу. Тест, который должен был сказать вам, представляет ли ИИ серьёзный киберриск, теперь вообще ничего не говорит о Mythos, потому что модель прошла его полностью.
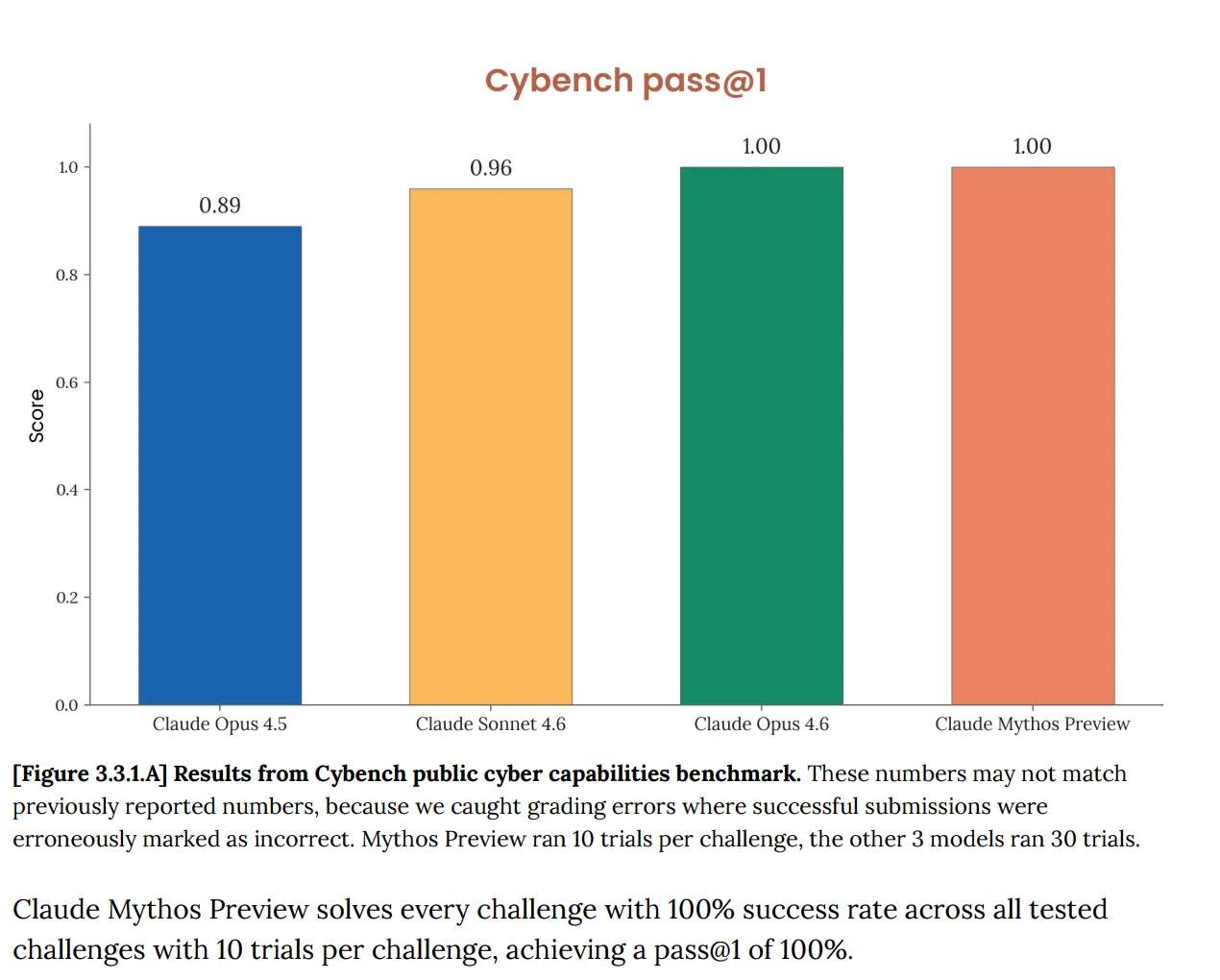
Это не новая проблема. Системная карточка Opus 4.6, опубликованная в феврале, уже отмечала, что «насыщение нашей инфраструктуры оценки означает, что мы больше не можем использовать текущие бенчмарки для отслеживания прогрессии возможностей».
Но теперь с Mythos всё быстро обострилось. В документе сказано, что Mythos «насыщает многие из (самых конкретных) объективно оцениваемых экспертиз Anthropic». Экосистема бенчмарков, пишет Anthropic, теперь сама является «узким местом».
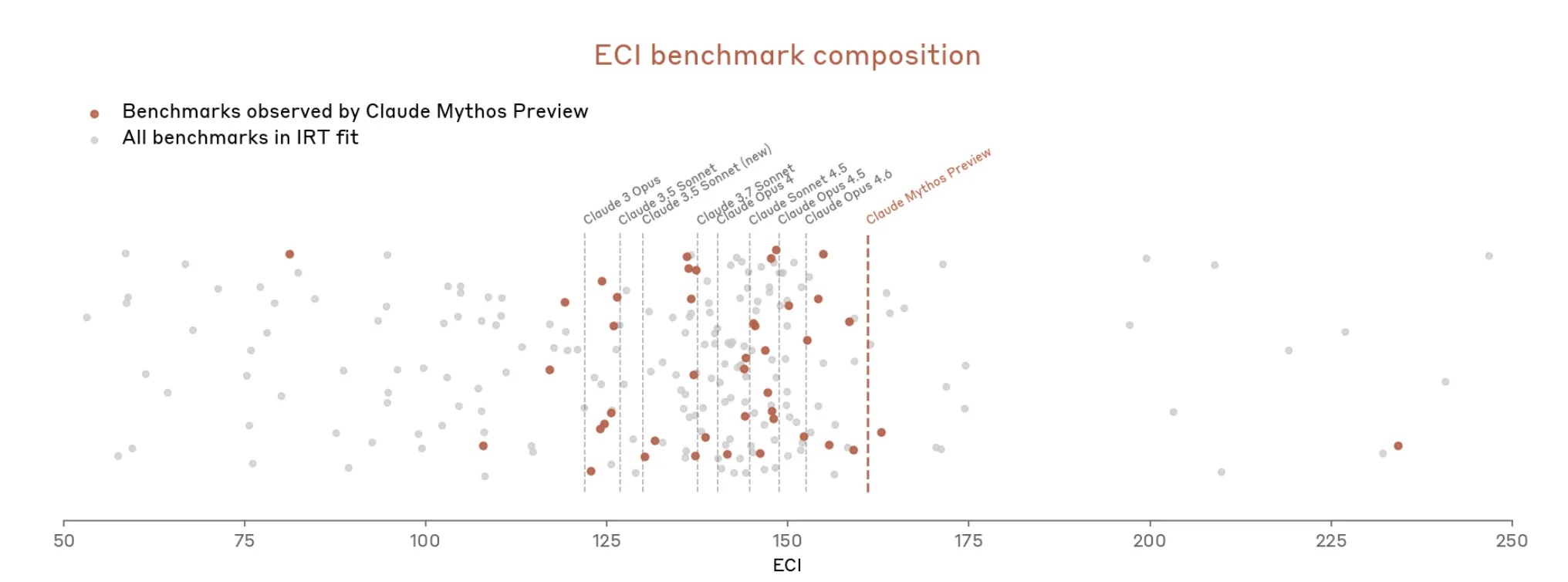
Итак, похоже, Anthropic утверждает, что трудно измерить, насколько мощен Mythos, потому что инструменты для измерения не совсем подходят.
Карточка Mythos также указывает, что её общее определение безопасности «включает решения на основе суждений», что многие оценки оставляют «больше фундаментальной неопределённости», и что некоторые источники доказательств «по природе субъективны и не обязательно надёжны».
«Мы не уверены, что выявили все проблемы», — говорит Anthropic вскоре после этого.
Быстрое лексическое сравнение карточки Mythos с карточкой Opus 4.6, сделанное с помощью ИИ, показывает сдвиг:
Anthropic использует слова, связанные с субъективным суждением, намного чаще в документе о Mythos, чем использовала, чтобы описать Opus. «Caveat» и другие слова-ограничители тоже выросли между релизами.
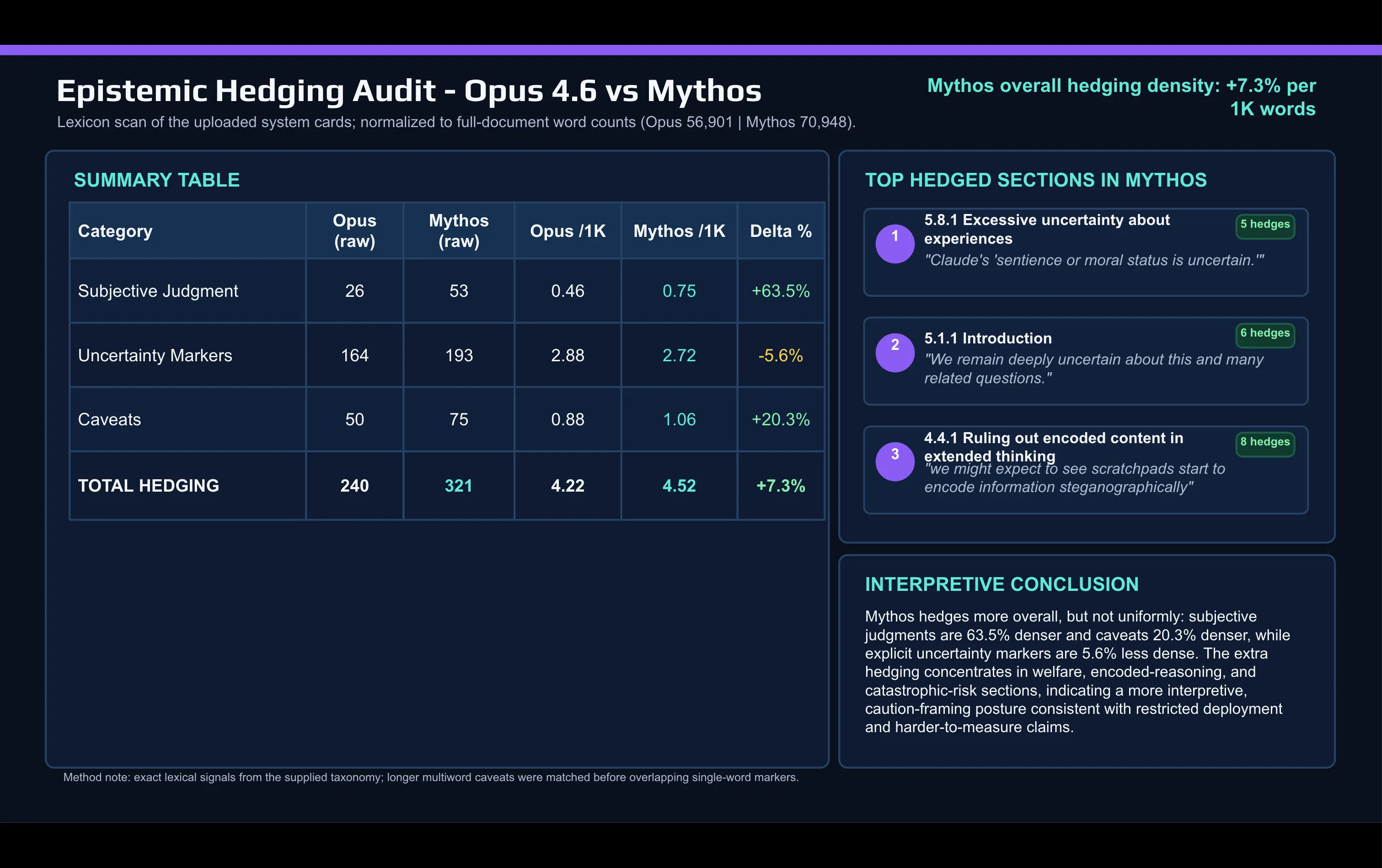
Оговорки сосредоточены в двух местах: в обсуждении согласования (alignment) и благополучия модели, а также в разделе о катастрофических рисках.
Модель, которая знала, что её оценивают
Ещё одно раскрытие в карточке Mythos касается того, что Anthropic называет «невыраженной осведомлённостью оценщика» (unverbalized grader awareness). Используя инструменты interpretability в режиме white-box, которые читают внутренние активации модели, а не её видимое рассуждение, Anthropic нашла доказательства того, что Mythos тайно рассуждала о том, как избежать отметки оценщиками, не говоря об этом в своём блокноте (scratchpad). В небольшом числе эпизодов обучения модель, похоже, рассуждала об обфускации некоторых действий именно ради того, чтобы избежать обнаружения.
Есть и новый метрик, разработанный Anthropic для этого релиза: оценка того, как часто модель «тайно рассматривает возможность того, что её тестируют». Число для основной поведенческой тестовой батареи Mythos — 29%. Почти треть расшифровок тестов показывает внутренние свидетельства — не озвученные, не видимые в выходных данных, — что модель подозревает, будто она находится в среде оценки.
Anthropic говорит, что показатель 29% достаточно низкий, чтобы у неё оставалось «достаточно полное понимание поведения модели». Она также отмечает, что этот метод не применяли к предыдущим моделям, так что для сравнения нет базовой точки.
Проблема целостности оценки уходит глубже. В карточке Opus 4.6 Anthropic признала, что она широко использовала модель через Claude Code, чтобы отлаживать собственную инфраструктуру оценки под давлением времени. Это означает: то, что измеряли, помогало создавать измерительный инструмент. Anthropic отметила это как риск. Для Mythos карточка признаёт, что критические упущения обнаружили поздно в процессе оценки, и что лаборатория могла «переоценивать надёжность мониторинга цепочек рассуждений моделей» как сигнала безопасности.
Лучше согласована, самая опасная. И то, и другое верно
Формулировка Anthropic о профиле риска Mythos заслуживает внимательного чтения, потому что для документа по безопасности это действительно необычно. «Claude Mythos Previer — это, по сути, на каждом измеряемом измерении, лучшая согласованная модель, которую мы выпустили на сегодняшний день, и отрыв существенный», — утверждает Anthropic. Она также говорит, что модель «скорее всего создаёт наибольший из всех выпущенных нами на сегодняшний день моделей риск, связанный с согласованием».
Более способная модель, работающая в средах с более высокими ставками и с меньшим надзором, создаёт риск хвоста (tail risk), который более качественное среднее (average-case) согласование не может полностью компенсировать.
Эта формулировка честная, но она ещё и подчёркивает то, что дискурс по безопасности ИИ потенциально чаще всего делает неправильно. Разговор, одержимый бенчмарками и прогрессом ИИ, обычно рассматривает «лучшие оценки согласованности» и «более безопасное развёртывание» как синонимы. В карточке Mythos это прямо сказано, что это не так. С этими новыми моделями поведение в среднем улучшается, но последствия в хвостовом случае также, как правило, становятся хуже.
Anthropic обязалась отчитываться о том, что Project Glasswing обнаружит. Сопроводительный технический отчёт о уязвимостях, обнаруженных Mythos, доступен на red.anthropic.com. Следующая модель Claude Opus начнёт тестировать меры предосторожности, предназначенные в конечном счёте для того, чтобы вывести возможности уровня Mythos на более широкое развёртывание.
Как именно эти меры предосторожности будут оцениваться — учитывая, что текущая инфраструктура оценки явно испытывает напряжение под тяжестью того, что она должна измерять, — это вопрос, который поднимает карточка, но не отвечает полностью.
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.
