CoinWorldKing
現在、コンテンツはありません
CoinWorldKing
DeFi で最恐ろしいのは爆発的な損失ではなく、担保リスクだ!
それはいつもあなたが最も安心しているときに突然顔を出してあなたの顔を殴る!😂他の人はまだ混沌とした市場の中で私のポジションが何に裏付けられているのか推測しているのか?
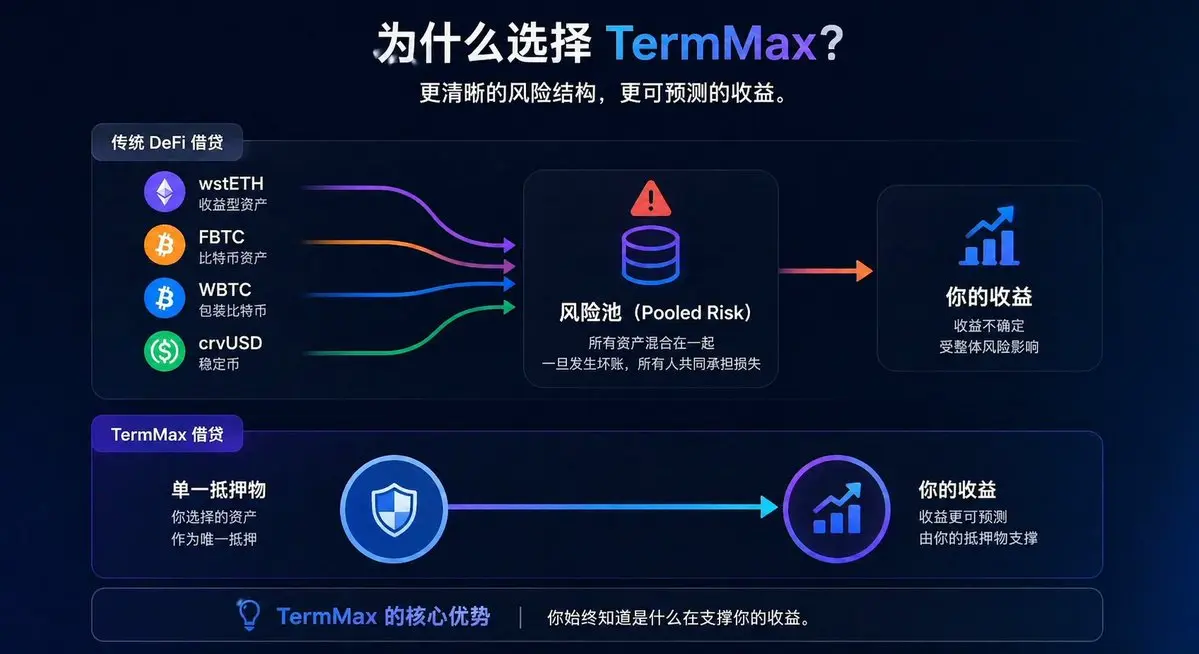
TermMax は各市場を徹底的に隔離し、エントリー前にあなたは裏側にどの資産があなたの背後にあるのか明確に知ることができる!
露出度を事前に知ることができるのは、事後の後知恵で「早く知っていればよかった」と叫ぶのではない。貸付も専門的に行うべきで、まずは手札をはっきり見せてから優雅に乗車して眠る 🐬
固定金利 + 透明なリスク管理、これが @TermMaxFi が皆が安心して眠れる本当の理由だ。
今すぐあなたのポジションがどれだけ安定しているか見てみたくないですか?
原文表示それはいつもあなたが最も安心しているときに突然顔を出してあなたの顔を殴る!😂他の人はまだ混沌とした市場の中で私のポジションが何に裏付けられているのか推測しているのか?
TermMax は各市場を徹底的に隔離し、エントリー前にあなたは裏側にどの資産があなたの背後にあるのか明確に知ることができる!
露出度を事前に知ることができるのは、事後の後知恵で「早く知っていればよかった」と叫ぶのではない。貸付も専門的に行うべきで、まずは手札をはっきり見せてから優雅に乗車して眠る 🐬
固定金利 + 透明なリスク管理、これが @TermMaxFi が皆が安心して眠れる本当の理由だ。
今すぐあなたのポジションがどれだけ安定しているか見てみたくないですか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
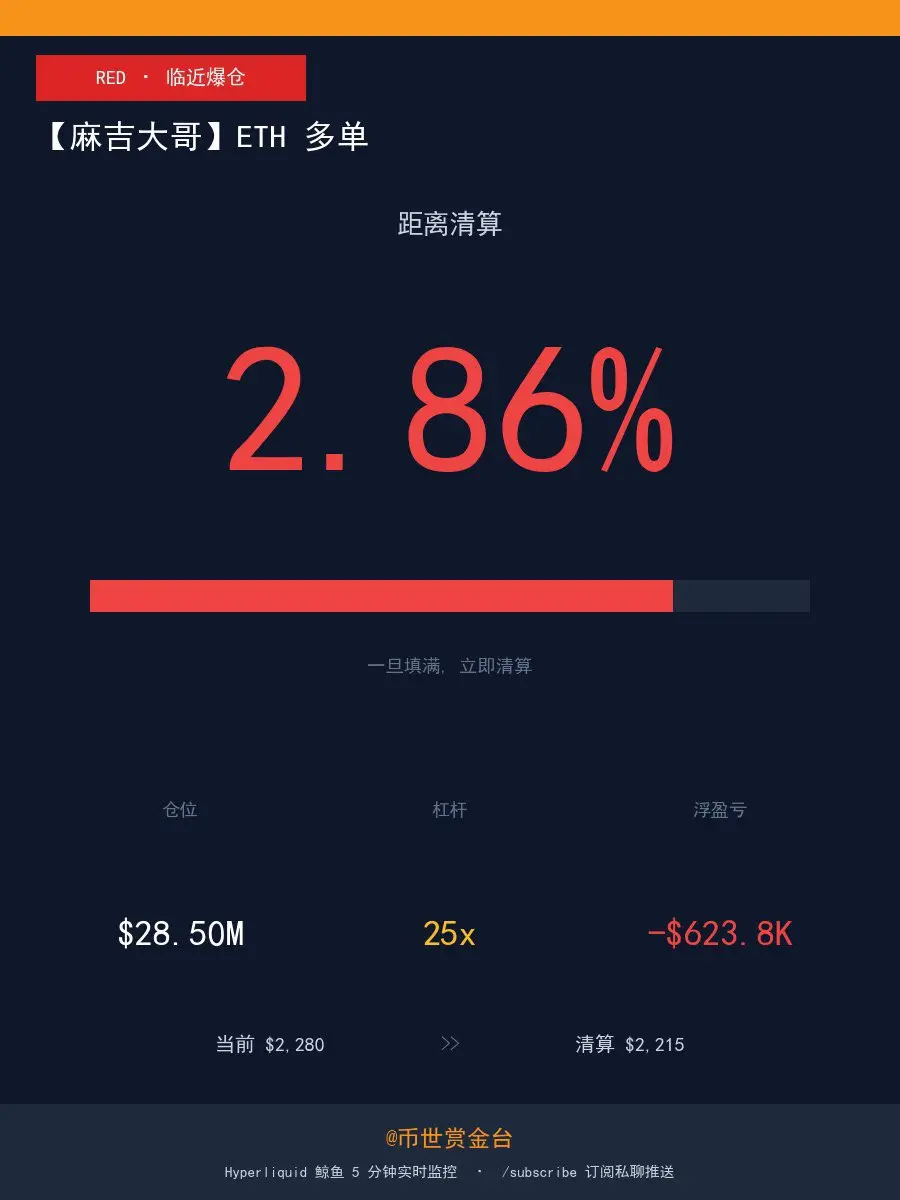
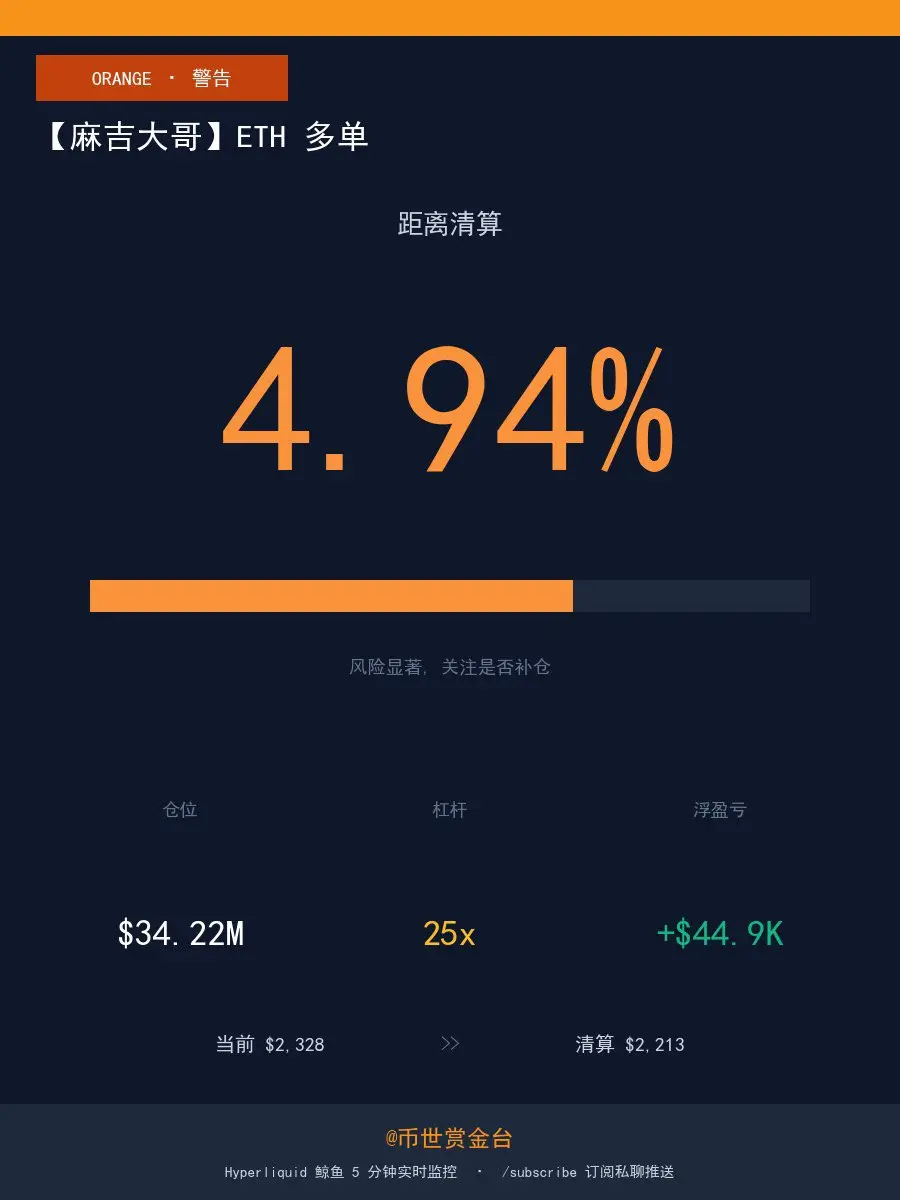
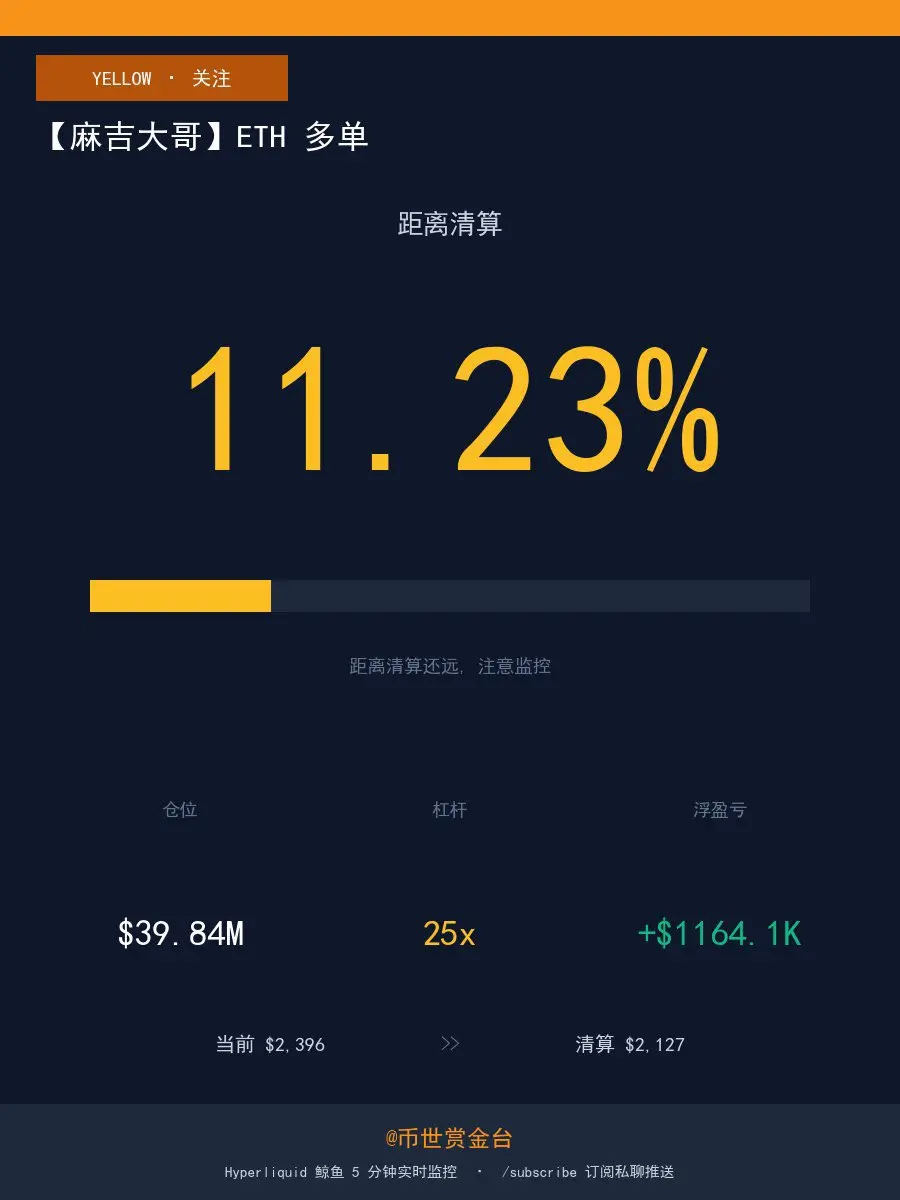
麻吉大哥のポジションを見ると、彼のことを心配せずにはいられない、心臓が強くなければ 😅
数時間前はほぼ強制清算寸前だったが、今は逆転した!
リアルタイムポジション:
原文表示数時間前はほぼ強制清算寸前だったが、今は逆転した!
リアルタイムポジション:
- 報酬
- いいね
- コメント
- リポスト
- 共有
WLFI 继续増やすアプリケーションシナリオ!
業界内では最近、WLFIのFUDがかなりあります。誰かが「詐欺だ」と叫び、誰かが「80%解放」と叫び、価格も一緒に自由落下しています。結果はどうでしょう?
チームは慌てず騒がず、引き続きUSD1の実用例を示しています。チームの感情知能と専門性は依然として高く、この操作はまるで元彼女があなたをクズ男と罵るのを黙ってブラックリストに入れ、その後ジムで腹筋を鍛え、新しいレストランを開くようなものです。あなたがどんなに批判しようと、まずは製品を作り上げて見せます。
Call Your Shotの登場は、USD1を見下すすべての人に対して大きな平手打ちを叩きつけたことに等しいです:ステーブルコインの究極の行き先はロックアップではなく、実際の消費、実際のエンターテインメント、実際の流動性です。
さらに素晴らしいのは、この一連の統合が完全にSolana上で行われていることです。Ethereumの高額な手数料を避け、普通の個人投資家も気軽に参加できるようになっています。以前は市場予測はクジラの遊び場でしたが、今や全員参加の「シュートパーティー」に変わっています。あなたは挑戦しますか?
未来は明るいですが、遊びだけに夢中にならないでください!
//
リスクはありますか?
「流動性は十分か?規制は突然変わるのか?AIデータは正確か?」
これらは時間をかけ
原文表示業界内では最近、WLFIのFUDがかなりあります。誰かが「詐欺だ」と叫び、誰かが「80%解放」と叫び、価格も一緒に自由落下しています。結果はどうでしょう?
チームは慌てず騒がず、引き続きUSD1の実用例を示しています。チームの感情知能と専門性は依然として高く、この操作はまるで元彼女があなたをクズ男と罵るのを黙ってブラックリストに入れ、その後ジムで腹筋を鍛え、新しいレストランを開くようなものです。あなたがどんなに批判しようと、まずは製品を作り上げて見せます。
Call Your Shotの登場は、USD1を見下すすべての人に対して大きな平手打ちを叩きつけたことに等しいです:ステーブルコインの究極の行き先はロックアップではなく、実際の消費、実際のエンターテインメント、実際の流動性です。
さらに素晴らしいのは、この一連の統合が完全にSolana上で行われていることです。Ethereumの高額な手数料を避け、普通の個人投資家も気軽に参加できるようになっています。以前は市場予測はクジラの遊び場でしたが、今や全員参加の「シュートパーティー」に変わっています。あなたは挑戦しますか?
未来は明るいですが、遊びだけに夢中にならないでください!
//
リスクはありますか?
「流動性は十分か?規制は突然変わるのか?AIデータは正確か?」
これらは時間をかけ

- 報酬
- 1
- コメント
- リポスト
- 共有
天亡巨星 @monad アカウントはどうしたの?
原文表示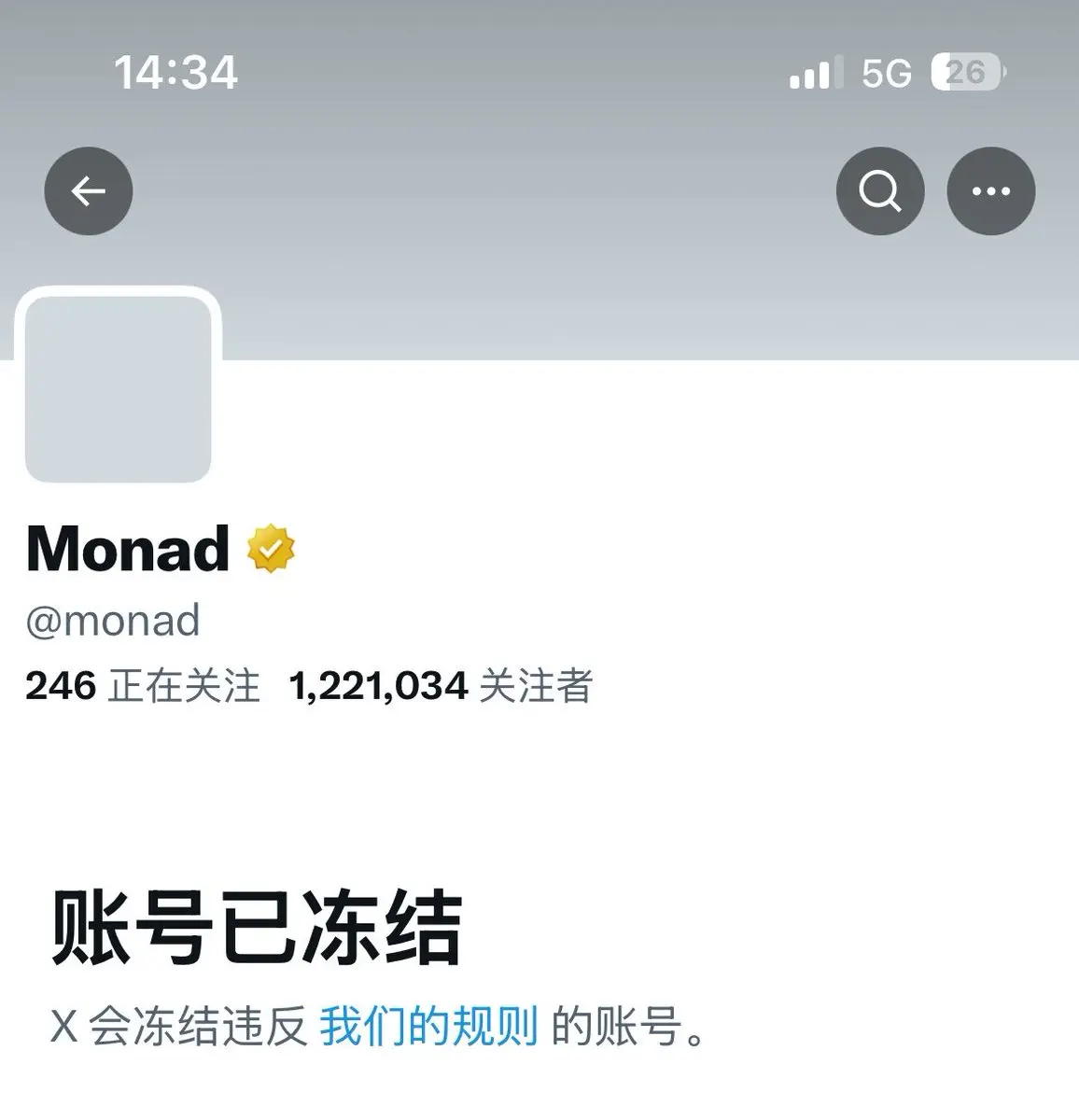
- 報酬
- いいね
- コメント
- リポスト
- 共有
寝ている間もお金を印刷できる?
10のGitHub神レベルリポジトリ、AIが24/7であなたのために働く!💰
自動化ツールを展開して、寝ている間やコーヒーを飲んでいる間、ドラマを見ている間に静かに稼ぐ。私は爆発的に人気のX投稿を見つけたので、パッシブでお金を印刷できる本物のオープンソースGitHubリポジトリを10個厳選した:
1. AutoHedge
自動ヘッジ取引エンジン、市場の変動時に賢くポジションを保護し、あなたの投資ポートフォリオをより堅実に。
🔗
2. Vibe-Trading
あなた専用の取引エージェント、一つのコマンドで全面的な取引能力を解放、Python + FastAPI駆動。
🔗
3. Claude Ads
Claude駆動の有料広告監査ツール、Google、Meta、TikTokなど250以上の監査チェックをカバーし、自動でレポートを生成。
🔗
4. Toprank
効率的なランキング最適化ツール、製品やコンテンツを素早くトップに押し上げる。
🔗
5. Fincept Terminal
オープンソースのBloomberg代替品、多資産のリアルタイムデータ端末、トレーダー必携。
🔗
6. Agentic Inbox
Cloudflare Workersによるセルフホスト型AIメールクライアント、AIエージ
10のGitHub神レベルリポジトリ、AIが24/7であなたのために働く!💰
自動化ツールを展開して、寝ている間やコーヒーを飲んでいる間、ドラマを見ている間に静かに稼ぐ。私は爆発的に人気のX投稿を見つけたので、パッシブでお金を印刷できる本物のオープンソースGitHubリポジトリを10個厳選した:
1. AutoHedge
自動ヘッジ取引エンジン、市場の変動時に賢くポジションを保護し、あなたの投資ポートフォリオをより堅実に。
🔗
2. Vibe-Trading
あなた専用の取引エージェント、一つのコマンドで全面的な取引能力を解放、Python + FastAPI駆動。
🔗
3. Claude Ads
Claude駆動の有料広告監査ツール、Google、Meta、TikTokなど250以上の監査チェックをカバーし、自動でレポートを生成。
🔗
4. Toprank
効率的なランキング最適化ツール、製品やコンテンツを素早くトップに押し上げる。
🔗
5. Fincept Terminal
オープンソースのBloomberg代替品、多資産のリアルタイムデータ端末、トレーダー必携。
🔗
6. Agentic Inbox
Cloudflare Workersによるセルフホスト型AIメールクライアント、AIエージ
原文表示

- 報酬
- いいね
- コメント
- リポスト
- 共有
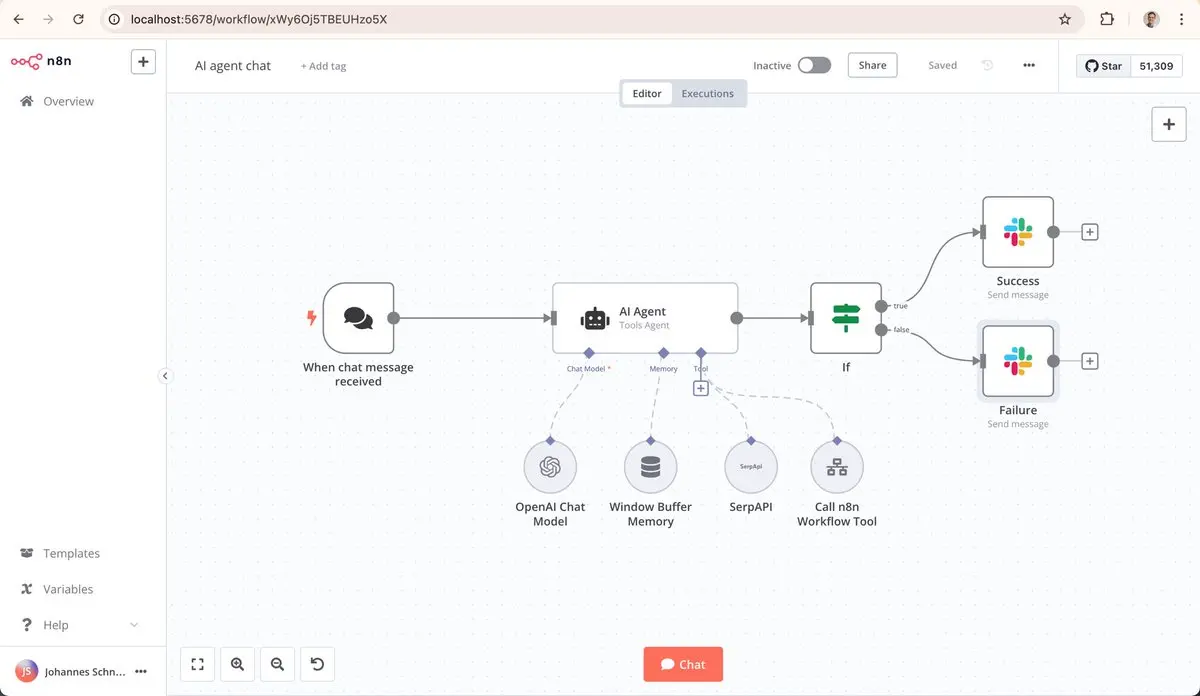
Zapier のオープンソース自動化ツールがGitHubで大人気!
2026年節約自動化ツール、1ヶ月であなたのZapier / Makeのサブスクリプション費用(楽に30〜200+ドル)を節約!
それはn8nと呼ばれ、GitHubで186k+スター、使いやすく、Docker対応、500+統合、データは自分のサーバーに全て保存、サブスクリプション不要の無限ワークフロー!
🟢
実際の機能はどれほど素晴らしい?
• 500+統合(Slack/Notion/データベース/メール/AIモデル/企業システム全対応)
• ネイティブAIエージェントワークフロー + LangChain多エージェント + RAG
• ドラッグ&ドロップのビジュアル構築 + JS/Pythonカスタムコード + npm拡張
• 美しいダッシュボード + 900+テンプレート + リアルタイムデバッグ/リラン/ログ
• 複数チャネル通知/手動承認 + 定期トリガー + 履歴記録
• Dockerワンクリック展開 + 自ホスティング完全コントロール、データは絶対漏洩しない
オープンソースでセルフホスティング、隠れた費用なし!
🟢🟢
どうやって無料で使う?2分で始めよう
1. メインリポジトリを開く:
2. Dockerでワンクリック起動:
docker volume create n8n_data
docke
原文表示2026年節約自動化ツール、1ヶ月であなたのZapier / Makeのサブスクリプション費用(楽に30〜200+ドル)を節約!
それはn8nと呼ばれ、GitHubで186k+スター、使いやすく、Docker対応、500+統合、データは自分のサーバーに全て保存、サブスクリプション不要の無限ワークフロー!
🟢
実際の機能はどれほど素晴らしい?
• 500+統合(Slack/Notion/データベース/メール/AIモデル/企業システム全対応)
• ネイティブAIエージェントワークフロー + LangChain多エージェント + RAG
• ドラッグ&ドロップのビジュアル構築 + JS/Pythonカスタムコード + npm拡張
• 美しいダッシュボード + 900+テンプレート + リアルタイムデバッグ/リラン/ログ
• 複数チャネル通知/手動承認 + 定期トリガー + 履歴記録
• Dockerワンクリック展開 + 自ホスティング完全コントロール、データは絶対漏洩しない
オープンソースでセルフホスティング、隠れた費用なし!
🟢🟢
どうやって無料で使う?2分で始めよう
1. メインリポジトリを開く:
2. Dockerでワンクリック起動:
docker volume create n8n_data
docke
- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
GPT Hermes VS Gemini Hermes
ヒントワード :時代感と創造力のある画像
あなたはどちらが優れていると思いますか?
原文表示ヒントワード :時代感と創造力のある画像
あなたはどちらが優れていると思いますか?


- 報酬
- いいね
- コメント
- リポスト
- 共有
香港カーニバルが完璧に幕を閉じました 🇭🇰
今回の香港旅行は、個人的にとても素晴らしく、最大の収穫はあのプライベートミーティングと深い交流から得られました。まず最初に第一日から振り返りますと、Gateの晩餐会では彼らの今後の展望と野心を見ることができ、採用活動も全力で行われているのがわかりました、わかりますよね!
Sui Houseのイベントでは、彼らのオンチェーン金融とステーブルコインの次の重要な戦略を目の当たりにし、さらに驚いたのはハッカー防御メカニズムが徹底されていて、去年のあの事件も十日も経たずに完全に解決されたことです!もっと驚いたのは、私が立ち上げたハッカソン賞金チャンネルでも、Dorahacksに監査賞金を設置しているのを見て、安全意識が一気に高まったことです!
異なる取引所のオフラインミーティングの雰囲気もまったく別世界:SNSでは取引所同士の罵り合いが見られるかもしれませんが、実際には皆とても和やかで、私も二人の取引所の幹部が一緒にいるのを目の当たりにしました(具体的な内容はネタバレしません😂)。プロジェクト関係者や友人たちと話すと、ほぼAIとエージェントが主な話題です。皆さんはAIツールを使ってコスト削減と効率化に狂っており、自動取引システムや、何人かの取引所の友人は全社員が毎日AIを使って打刻しなければならないと直言しています。私の友人のビッ
原文表示今回の香港旅行は、個人的にとても素晴らしく、最大の収穫はあのプライベートミーティングと深い交流から得られました。まず最初に第一日から振り返りますと、Gateの晩餐会では彼らの今後の展望と野心を見ることができ、採用活動も全力で行われているのがわかりました、わかりますよね!
Sui Houseのイベントでは、彼らのオンチェーン金融とステーブルコインの次の重要な戦略を目の当たりにし、さらに驚いたのはハッカー防御メカニズムが徹底されていて、去年のあの事件も十日も経たずに完全に解決されたことです!もっと驚いたのは、私が立ち上げたハッカソン賞金チャンネルでも、Dorahacksに監査賞金を設置しているのを見て、安全意識が一気に高まったことです!
異なる取引所のオフラインミーティングの雰囲気もまったく別世界:SNSでは取引所同士の罵り合いが見られるかもしれませんが、実際には皆とても和やかで、私も二人の取引所の幹部が一緒にいるのを目の当たりにしました(具体的な内容はネタバレしません😂)。プロジェクト関係者や友人たちと話すと、ほぼAIとエージェントが主な話題です。皆さんはAIツールを使ってコスト削減と効率化に狂っており、自動取引システムや、何人かの取引所の友人は全社員が毎日AIを使って打刻しなければならないと直言しています。私の友人のビッ

- 報酬
- いいね
- 1
- リポスト
- 共有
どうやってマカオを格安旅行するか?
セントポール大聖堂で満腹試食試飲、一日三食節約 ✌️
原文表示セントポール大聖堂で満腹試食試飲、一日三食節約 ✌️



- 報酬
- いいね
- コメント
- リポスト
- 共有
昨晚親臨 @Gate GALA 13周年慶典晚宴,直接被拿捏!
Dr. Han 親自上台,激情分享 Gate 13年從一行代碼到服務 5000萬用戶的征程,用行動告訴我們 Gate 從未止步、繼續邁進!
很高興參與這樣的夜晚,我知道這是加速衝向 iWeb3 新時代的開始!期待住啦!
@Han_Gate @Gate @Godot_gate @JoeyJia11 @kevinlee_gate @GateVIP_zh @GateLive_Ric @Gate_Leisel @Micky_Gate @Scottz_Gate @gate_kol26
原文表示Dr. Han 親自上台,激情分享 Gate 13年從一行代碼到服務 5000萬用戶的征程,用行動告訴我們 Gate 從未止步、繼續邁進!
很高興參與這樣的夜晚,我知道這是加速衝向 iWeb3 新時代的開始!期待住啦!
@Han_Gate @Gate @Godot_gate @JoeyJia11 @kevinlee_gate @GateVIP_zh @GateLive_Ric @Gate_Leisel @Micky_Gate @Scottz_Gate @gate_kol26


- 報酬
- いいね
- コメント
- リポスト
- 共有
Gate 13周年おめでとうございます!
決して止まらず、最近のIPO、TradeFi&GateClawのように、着実に前進し続け、先手を取る。これこそ取引所のあるべき姿だ!
@Gate @Gate_zh @gate_kol26
#Gate13周年
原文表示決して止まらず、最近のIPO、TradeFi&GateClawのように、着実に前進し続け、先手を取る。これこそ取引所のあるべき姿だ!
@Gate @Gate_zh @gate_kol26
#Gate13周年

- 報酬
- いいね
- コメント
- リポスト
- 共有
昨晚我差点被这个工具干到失语!
我把 Hermes 整个架构+所有第三方插件甩给它,30秒后,它给我画出了一张像艺术品一样的架构图。层次分明、配色高级、连我自己都没这么清晰地看过自己的系统。
那一刻我突然明白:
AI 真正牛逼的地方,从来不是帮你省代码,而是把你脑子里最复杂的混沌,变成一眼就能看懂的美。以前我们画架构图,像在黑暗里摸索搭积木。
现在,它直接把灯打开,还顺手帮你调了最舒服的光。这不是工具,这是把系统思考可视化的浪漫。
真正的独立开发者,不该只卷代码,更该学会把自己的世界画出来,让别人一眼就懂、就爱、就想一起玩。
神器奉上(已亲测上头):
原文表示我把 Hermes 整个架构+所有第三方插件甩给它,30秒后,它给我画出了一张像艺术品一样的架构图。层次分明、配色高级、连我自己都没这么清晰地看过自己的系统。
那一刻我突然明白:
AI 真正牛逼的地方,从来不是帮你省代码,而是把你脑子里最复杂的混沌,变成一眼就能看懂的美。以前我们画架构图,像在黑暗里摸索搭积木。
现在,它直接把灯打开,还顺手帮你调了最舒服的光。这不是工具,这是把系统思考可视化的浪漫。
真正的独立开发者,不该只卷代码,更该学会把自己的世界画出来,让别人一眼就懂、就爱、就想一起玩。
神器奉上(已亲测上头):
- 報酬
- いいね
- コメント
- リポスト
- 共有
多くの人が知らない真の暗号市場:
• 単一の大口操縦者がいない - 複数の大口投資家 + MM + 機関 + 個人投資家の博弈と混沌
• MMは資金吸収をしない、マーケットメイキングの利益はスプレッドからであり、方向性ではない - 彼らは両方向のマーケットメイキングを行う
• 実際にポジションを構築するのはOTCの店外買い手と大口投資家であり、彼らはより多く現物取引 + 先物現物裁定を利用し、永続契約のOIに必ずしも反映されない
原文表示• 単一の大口操縦者がいない - 複数の大口投資家 + MM + 機関 + 個人投資家の博弈と混沌
• MMは資金吸収をしない、マーケットメイキングの利益はスプレッドからであり、方向性ではない - 彼らは両方向のマーケットメイキングを行う
• 実際にポジションを構築するのはOTCの店外買い手と大口投資家であり、彼らはより多く現物取引 + 先物現物裁定を利用し、永続契約のOIに必ずしも反映されない
- 報酬
- いいね
- コメント
- リポスト
- 共有
みんな妖币を研究している、OI、じゃあ誰が儲けたの?
ちょっと学んでみるね
原文表示ちょっと学んでみるね
- 報酬
- いいね
- コメント
- リポスト
- 共有