La IA generativa ha entrado en la era del vídeo.
Fuente original: Heart of the Machine
 Fuente de la imagen: Generado por Unbounded AI
Fuente de la imagen: Generado por Unbounded AI
Cuando se trata de generación de video, muchas personas probablemente piensen primero en Gen-2 y Pika Labs. Pero justo ahora, Meta anunció que han superado a ambos en términos de generación de video y son más flexibles en la edición.

 Esta “trompeta, conejo bailarín” es la última demo lanzada por Meta. Como puede ver, la tecnología de Meta admite tanto la edición flexible de imágenes (por ejemplo, convertir un “conejo” en un “conejito trompeta” y luego un “conejito trompeta con los colores del arcoíris”) como la generación de videos de alta resolución a partir de texto e imágenes (por ejemplo, hacer que un “conejito trompeta” baile felizmente).
Esta “trompeta, conejo bailarín” es la última demo lanzada por Meta. Como puede ver, la tecnología de Meta admite tanto la edición flexible de imágenes (por ejemplo, convertir un “conejo” en un “conejito trompeta” y luego un “conejito trompeta con los colores del arcoíris”) como la generación de videos de alta resolución a partir de texto e imágenes (por ejemplo, hacer que un “conejito trompeta” baile felizmente).
En realidad, hay dos cosas involucradas.
La edición flexible de imágenes se realiza mediante un modelo llamado “Emu Edit”. Admite la edición gratuita de imágenes con texto, incluida la edición local y global, la eliminación y adición de fondos, las conversiones de color y geometría, la detección y segmentación, y más. Además, sigue las instrucciones con precisión, lo que garantiza que los píxeles de la imagen de entrada que no están relacionados con las instrucciones permanezcan intactos.
 Viste al avestruz con falda
Viste al avestruz con falda
El video de alta resolución es generado por un modelo llamado “Emu Video”. Emu Video es un modelo basado en la difusión del video Wensheng que es capaz de generar video de alta resolución de 512x512 de 4 segundos basado en texto (los videos más largos también se discuten en el documento). Una rigurosa evaluación humana mostró que Emu Video obtuvo una puntuación más alta tanto en la calidad de la generación como en la fidelidad del texto en comparación con el Gen-2 de Runway y el rendimiento de la generación de Pika Labs. Así es como se verá:

 En su blog oficial, Meta imaginó el futuro de ambas tecnologías, incluyendo permitir a los usuarios de las redes sociales generar sus propios GIF, memes y editar fotos e imágenes como deseen. Con respecto a esto, Meta también lo mencionó cuando lanzó el modelo Emu en la conferencia Meta Connect anterior (ver: “La versión de ChatGPT de Meta está aquí: bendición de Llama 2, acceso a la búsqueda de Bing, demostración en vivo de Xiaozha”).
En su blog oficial, Meta imaginó el futuro de ambas tecnologías, incluyendo permitir a los usuarios de las redes sociales generar sus propios GIF, memes y editar fotos e imágenes como deseen. Con respecto a esto, Meta también lo mencionó cuando lanzó el modelo Emu en la conferencia Meta Connect anterior (ver: “La versión de ChatGPT de Meta está aquí: bendición de Llama 2, acceso a la búsqueda de Bing, demostración en vivo de Xiaozha”).
 A continuación, presentaremos cada uno de estos dos nuevos modelos.
A continuación, presentaremos cada uno de estos dos nuevos modelos.
EmuVideo
El modelo de grafo de Wensheng grande se entrena en pares de imagen y texto a escala web para producir imágenes diversas y de alta calidad. Si bien estos modelos se pueden adaptar aún más a la generación de texto a video (T2V) mediante el uso de pares de video y texto, la generación de video aún está rezagada con respecto a la generación de imágenes en términos de calidad y variedad. En comparación con la generación de imágenes, la generación de vídeo es más difícil porque requiere modelar una dimensión más alta del espacio de salida espacio-temporal, que aún puede basarse en indicaciones de texto. Además, los conjuntos de datos de vídeo y texto suelen ser un orden de magnitud menor que los conjuntos de datos de imagen y texto.
El modo predominante de generación de vídeo es utilizar un modelo de difusión para generar todos los fotogramas de vídeo a la vez. En marcado contraste, en PNL, la generación de secuencias largas se formula como un problema autorregresivo: predecir la siguiente palabra bajo la condición de una palabra previamente predicha. Como resultado, la señal de condicionamiento de la predicción posterior se hará gradualmente más fuerte. Los investigadores plantean la hipótesis de que el acondicionamiento mejorado también es importante para la generación de video de alta calidad, que es en sí misma una serie temporal. Sin embargo, la decodificación autorregresiva con modelos de difusión es un desafío, ya que la generación de una imagen de un solo fotograma con la ayuda de dichos modelos requiere múltiples iteraciones en sí misma.
Como resultado, los investigadores de Meta propusieron EMU VIDEO, que aumenta la generación de texto a video basada en la difusión con un paso intermedio explícito de generación de imágenes.
 Dirección:
Dirección:
Dirección del proyecto:
Específicamente, descompusieron el problema del video de Wensheng en dos subproblemas: (1) generar una imagen basada en el mensaje de texto de entrada y (2) generar un video basado en las condiciones de refuerzo de la imagen y el texto. De forma intuitiva, dar al modelo una imagen y un texto iniciales facilita la generación de vídeo, ya que el modelo solo necesita predecir cómo evolucionará la imagen en el futuro.
 * Los investigadores de Meta dividieron el video de Wensheng en dos pasos: primero generar la imagen I condicional en el texto p, y luego usar condiciones más fuertes (la imagen y el texto resultantes) para generar el video v. Para restringir el modelo F con una imagen, se centraron temporalmente en la imagen y la conectaron a una máscara binaria que indica qué fotogramas se pusieron a cero, así como a una entrada ruidosa. *
* Los investigadores de Meta dividieron el video de Wensheng en dos pasos: primero generar la imagen I condicional en el texto p, y luego usar condiciones más fuertes (la imagen y el texto resultantes) para generar el video v. Para restringir el modelo F con una imagen, se centraron temporalmente en la imagen y la conectaron a una máscara binaria que indica qué fotogramas se pusieron a cero, así como a una entrada ruidosa. *
Dado que el conjunto de datos de video-texto es mucho más pequeño que el conjunto de datos de imagen-texto, los investigadores también inicializaron su modelo de texto a video con un modelo de texto-imagen preentrenado (T2I) congelado por peso. Identificaron decisiones de diseño clave (cambiar la programación de ruido difuso y entrenamiento de varias etapas) para producir directamente video de alta resolución de 512 px.
A diferencia del método de generar un video directamente a partir del texto, su método de descomposición genera explícitamente una imagen al inferir, lo que les permite preservar fácilmente la diversidad visual, el estilo y la calidad del modelo de diagrama de Wensheng (como se muestra en la Figura 1). ESTO PERMITE QUE EMU VIDEO SUPERE A LOS MÉTODOS DIRECTOS DE T2V INCLUSO CON LOS MISMOS DATOS DE ENTRENAMIENTO, CANTIDAD DE CÓMPUTO Y PARÁMETROS ENTRENABLES.

 Este estudio muestra que la calidad de la generación de video Wensheng se puede mejorar en gran medida a través de un método de entrenamiento de varias etapas. Este método admite la generación directa de vídeo de alta resolución a 512 px sin necesidad de algunos de los modelos de cascada profunda utilizados en el método anterior.
Este estudio muestra que la calidad de la generación de video Wensheng se puede mejorar en gran medida a través de un método de entrenamiento de varias etapas. Este método admite la generación directa de vídeo de alta resolución a 512 px sin necesidad de algunos de los modelos de cascada profunda utilizados en el método anterior.

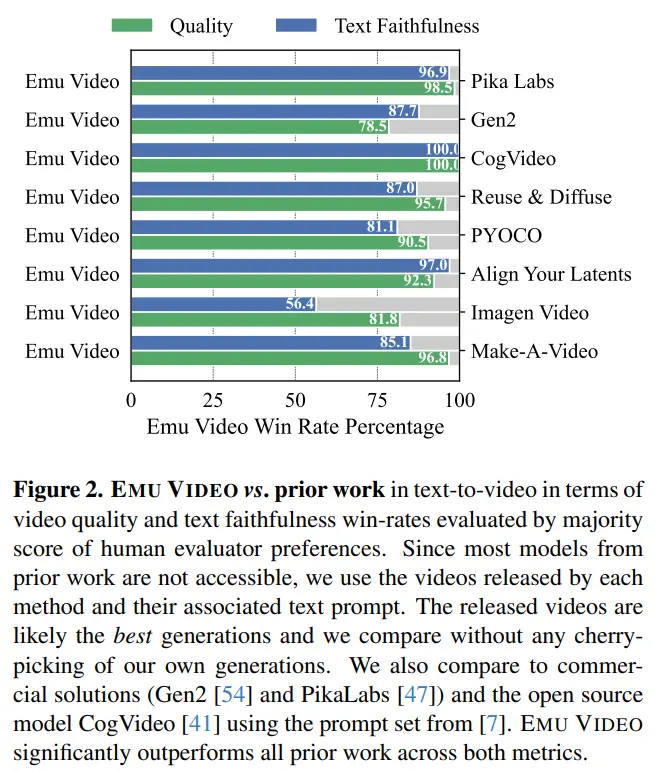
 Los investigadores idearon un sólido protocolo de evaluación humana, JUICE, en el que se pidió a los evaluadores que demostraran que su elección era correcta al hacer una elección entre parejas. Como se muestra en la Figura 2, las tasas de ganancia promedio de EMU VIDEO del 91,8 % y el 86,6 % en términos de calidad y fidelidad del texto están muy por delante de todo el trabajo inicial, incluidas las soluciones comerciales como Pika, Gen-2 y otras. ADEMÁS DE T2V, EMU VIDEO TAMBIÉN SE PUEDE USAR PARA LA GENERACIÓN DE IMAGEN A VIDEO, DONDE EL MODELO GENERA VIDEO BASADO EN IMÁGENES Y MENSAJES DE TEXTO PROPORCIONADOS POR EL USUARIO. En este caso, los resultados de generación de EMU VIDEO son un 96% mejores que los de VideoComposer.
Los investigadores idearon un sólido protocolo de evaluación humana, JUICE, en el que se pidió a los evaluadores que demostraran que su elección era correcta al hacer una elección entre parejas. Como se muestra en la Figura 2, las tasas de ganancia promedio de EMU VIDEO del 91,8 % y el 86,6 % en términos de calidad y fidelidad del texto están muy por delante de todo el trabajo inicial, incluidas las soluciones comerciales como Pika, Gen-2 y otras. ADEMÁS DE T2V, EMU VIDEO TAMBIÉN SE PUEDE USAR PARA LA GENERACIÓN DE IMAGEN A VIDEO, DONDE EL MODELO GENERA VIDEO BASADO EN IMÁGENES Y MENSAJES DE TEXTO PROPORCIONADOS POR EL USUARIO. En este caso, los resultados de generación de EMU VIDEO son un 96% mejores que los de VideoComposer.
 Como se puede ver en la demostración mostrada, EMU VIDEO ya puede admitir la generación de video de 4 segundos. En el documento, también exploran formas de aumentar la duración del video. Con una pequeña modificación arquitectónica, los autores dicen que pueden restringir el modelo en un marco en T y extender el video. POR LO TANTO, ENTRENARON UNA VARIANTE DE EMU VIDEO PARA GENERAR LOS SIGUIENTES 16 FOTOGRAMAS CON LA CONDICIÓN DE “PASAR” 16 FOTOGRAMAS. Al expandir el vídeo, utilizan un mensaje de texto futuro diferente al del vídeo original, como se muestra en la figura 7. Descubrieron que el video extendido sigue tanto el video original como las indicaciones de texto futuras.
Como se puede ver en la demostración mostrada, EMU VIDEO ya puede admitir la generación de video de 4 segundos. En el documento, también exploran formas de aumentar la duración del video. Con una pequeña modificación arquitectónica, los autores dicen que pueden restringir el modelo en un marco en T y extender el video. POR LO TANTO, ENTRENARON UNA VARIANTE DE EMU VIDEO PARA GENERAR LOS SIGUIENTES 16 FOTOGRAMAS CON LA CONDICIÓN DE “PASAR” 16 FOTOGRAMAS. Al expandir el vídeo, utilizan un mensaje de texto futuro diferente al del vídeo original, como se muestra en la figura 7. Descubrieron que el video extendido sigue tanto el video original como las indicaciones de texto futuras.
 Emu Edit: Edición precisa de imágenes
Emu Edit: Edición precisa de imágenes
Millones de personas utilizan la edición de imágenes todos los días. Sin embargo, las herramientas de edición de imágenes más populares requieren una experiencia considerable y su uso requiere mucho tiempo, o son muy limitadas y ofrecen solo un conjunto de operaciones de edición predefinidas, como filtros específicos. En esta etapa, la edición de imágenes basada en instrucciones intenta que los usuarios usen instrucciones en lenguaje natural para evitar estas limitaciones. Por ejemplo, un usuario puede proporcionar una imagen a un modelo e indicarle que “vista a un emú con un disfraz de bombero” (consulte la Figura 1).
 Sin embargo, aunque los modelos de edición de imágenes basados en instrucciones como InstructPix2Pix se pueden utilizar para manejar una variedad de instrucciones dadas, a menudo son difíciles de interpretar y ejecutar instrucciones con precisión. Además, estos modelos tienen capacidades de generalización limitadas y, a menudo, no pueden realizar tareas que son ligeramente diferentes de aquellas en las que fueron entrenados (consulte la Figura 3), como hacer que un conejo bebé toque una trompeta con los colores del arco iris y otros modelos tiñan el conejo con los colores del arco iris o generan directamente una trompeta con los colores del arco iris.
Sin embargo, aunque los modelos de edición de imágenes basados en instrucciones como InstructPix2Pix se pueden utilizar para manejar una variedad de instrucciones dadas, a menudo son difíciles de interpretar y ejecutar instrucciones con precisión. Además, estos modelos tienen capacidades de generalización limitadas y, a menudo, no pueden realizar tareas que son ligeramente diferentes de aquellas en las que fueron entrenados (consulte la Figura 3), como hacer que un conejo bebé toque una trompeta con los colores del arco iris y otros modelos tiñan el conejo con los colores del arco iris o generan directamente una trompeta con los colores del arco iris.
 Para abordar estos problemas, Meta presentó Emu Edit, el primer modelo de edición de imágenes entrenado en una amplia y diversa gama de tareas, que puede realizar ediciones de forma libre basadas en comandos, incluida la edición local y global, la eliminación y adición de fondos, los cambios de color y las transformaciones geométricas, y la detección y segmentación.
Para abordar estos problemas, Meta presentó Emu Edit, el primer modelo de edición de imágenes entrenado en una amplia y diversa gama de tareas, que puede realizar ediciones de forma libre basadas en comandos, incluida la edición local y global, la eliminación y adición de fondos, los cambios de color y las transformaciones geométricas, y la detección y segmentación.
 Dirección:
Dirección:
Dirección del proyecto:
A diferencia de muchos de los modelos de IA generativa actuales, Emu Edit puede seguir instrucciones con precisión, lo que garantiza que los píxeles no relacionados de la imagen de entrada permanezcan intactos. Por ejemplo, si el usuario da la orden “retira al cachorro de la hierba”, la imagen después de retirar el objeto es apenas perceptible.
 La eliminación del texto en la esquina inferior izquierda de la imagen y el cambio del fondo de la imagen también serán manejados por Emu Edit:
La eliminación del texto en la esquina inferior izquierda de la imagen y el cambio del fondo de la imagen también serán manejados por Emu Edit:
 Para entrenar este modelo, Meta desarrolló un conjunto de datos de 10 millones de muestras sintéticas, cada una de las cuales contiene una imagen de entrada, una descripción de la tarea que se va a realizar y una imagen de salida de destino. Como resultado, Emu Edit muestra resultados de edición sin precedentes en términos de fidelidad de comandos y calidad de imagen.
Para entrenar este modelo, Meta desarrolló un conjunto de datos de 10 millones de muestras sintéticas, cada una de las cuales contiene una imagen de entrada, una descripción de la tarea que se va a realizar y una imagen de salida de destino. Como resultado, Emu Edit muestra resultados de edición sin precedentes en términos de fidelidad de comandos y calidad de imagen.
A nivel metodológico, los modelos entrenados con Meta pueden realizar dieciséis tareas diferentes de edición de imágenes, que abarcan la edición basada en regiones, la edición de forma libre y las tareas de visión artificial, todas ellas formuladas como tareas generativas, y Meta también ha desarrollado una canalización de gestión de datos única para cada tarea. Meta ha descubierto que a medida que aumenta el número de tareas de entrenamiento, también lo hace el rendimiento de Emu Edit.
En segundo lugar, con el fin de manejar de manera efectiva una amplia variedad de tareas, Meta introdujo el concepto de incrustación de tareas aprendidas, que se utiliza para guiar el proceso de generación en la dirección correcta de la tarea de compilación. Específicamente, para cada tarea, este documento aprende un vector de incrustación de tarea único y lo integra en el modelo a través de la interacción de atención cruzada y lo agrega a la incrustación de paso de tiempo. Los resultados muestran que la incrustación de tareas de aprendizaje mejora significativamente la capacidad del modelo para razonar con precisión a partir de instrucciones de forma libre y realizar ediciones correctas.
En abril de este año, Meta lanzó el modelo de IA “Split Everything”, y el efecto fue tan sorprendente que muchas personas comenzaron a preguntarse si el campo de CV todavía existe. En solo unos meses, Meta ha lanzado Emu Video y Emu Edit en el campo de las imágenes y los videos, y solo podemos decir que el campo de la IA generativa es realmente demasiado volátil.

