win1688888888
投機

Meta Manus 退款成功😂
查看原文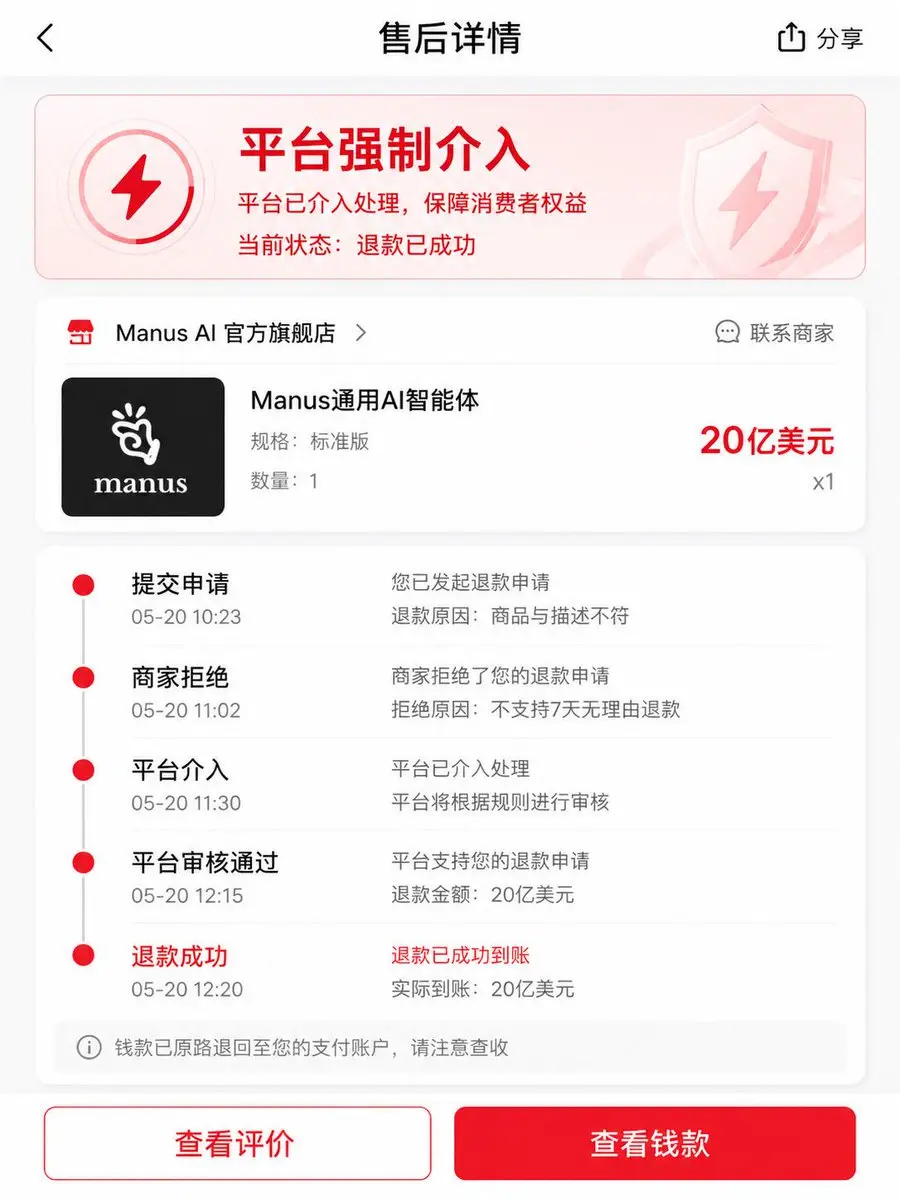
- 打賞
- 按讚
- 留言
- 轉發
- 分享
用AI起了3個號,單條播放134萬!
查看原文- 打賞
- 按讚
- 留言
- 轉發
- 分享
個體商家電商找貨源實操!
查看原文- 打賞
- 按讚
- 留言
- 轉發
- 分享
還在像無頭蒼蠅一樣全網搜尋碎片資料嗎?這個網站直接讓你“偷”看大佬的私房筆記!全網公開飛書文檔一鍵搜尋,無需登入,直接白嫖成系統的行業干貨,效率直接拉滿!
1⃣ 直達源頭( 別再去百度大海撈針了。直接打開這個站,它專門抓取全網公開的飛書雲文檔。別人花幾個月整理的“小紅書運營SOP”、“AI編程指南”,這裡直接搜尋出來。
2⃣ 降維打擊(知識庫聚合): 看到下面的“熱門飛書知識庫”了嗎?WaytoAGI、小報童專欄導航、AGI挖金庫... 這些全是行業大佬精心整理的體系化內容。你搜尋一個詞,它直接給你推一整套知識框架。
3⃣ 零門檻白嫖(無需登入): 不需要註冊,不需要付費,打開就能用。覆蓋自媒體、電商、跨境、AI、職場全領域。這就是典型的“用資訊差換時間”。
4⃣ AI精準投喂: 它不是簡單的關鍵詞匹配,是AI精準推薦。你想做TikTok,它直接把別人驗證過的實操文檔甩你臉上,照著抄作業就行。
記住,資訊差的核心,從來不是你知道得更多,而是你比別人更快拿到“能直接落地”的成系統內容。 別人還在拼湊碎片,你已經拿著框架開幹了。
網址我放評論區了,這種能拉開差距的寶藏站,趁沒火趕緊存! 下一期想看我拆解什麼搞錢神器?評論區告訴我。
查看原文1⃣ 直達源頭( 別再去百度大海撈針了。直接打開這個站,它專門抓取全網公開的飛書雲文檔。別人花幾個月整理的“小紅書運營SOP”、“AI編程指南”,這裡直接搜尋出來。
2⃣ 降維打擊(知識庫聚合): 看到下面的“熱門飛書知識庫”了嗎?WaytoAGI、小報童專欄導航、AGI挖金庫... 這些全是行業大佬精心整理的體系化內容。你搜尋一個詞,它直接給你推一整套知識框架。
3⃣ 零門檻白嫖(無需登入): 不需要註冊,不需要付費,打開就能用。覆蓋自媒體、電商、跨境、AI、職場全領域。這就是典型的“用資訊差換時間”。
4⃣ AI精準投喂: 它不是簡單的關鍵詞匹配,是AI精準推薦。你想做TikTok,它直接把別人驗證過的實操文檔甩你臉上,照著抄作業就行。
記住,資訊差的核心,從來不是你知道得更多,而是你比別人更快拿到“能直接落地”的成系統內容。 別人還在拼湊碎片,你已經拿著框架開幹了。
網址我放評論區了,這種能拉開差距的寶藏站,趁沒火趕緊存! 下一期想看我拆解什麼搞錢神器?評論區告訴我。

- 打賞
- 按讚
- 留言
- 轉發
- 分享
網址🔗:
查看原文- 打賞
- 按讚
- 留言
- 轉發
- 分享
申請填寫核心步驟與高分技巧
基本信息填寫
請填寫個人常用郵箱,並注明日常使用的開發工具(例如:Claude Code),以及常用的底層模型(例如:Kimi、GLM)。
核心加分項 1:項目介紹(重中之重)
不提倡單純羅列項目內容,建議採用「提出行業問題 + 給出解決方案」的邏輯來撰寫,其風格類似於向投資人進行項目展示,用百字左右清楚闡述核心要點。
可著重說明:項目的核心定位、開發過程中的關鍵里程碑、當前行業現有方案存在的缺陷、項目旨在解決的核心痛點。即便項目尚處於半成品階段,也應清晰闡述項目規劃及其核心價值。
核心加分項 2:影響力證明(關鍵篩選因素)
優先提供項目代碼倉庫地址,並展示倉庫的 Star 數據,以此體現項目在行業內的認可度。
若 Star 數據不夠突出,可提供大模型 Token 消耗截圖,通過真實的高頻使用數據,有力證明自身的開發需求與活躍度,這是極具說服力的證明材料。
查看原文基本信息填寫
請填寫個人常用郵箱,並注明日常使用的開發工具(例如:Claude Code),以及常用的底層模型(例如:Kimi、GLM)。
核心加分項 1:項目介紹(重中之重)
不提倡單純羅列項目內容,建議採用「提出行業問題 + 給出解決方案」的邏輯來撰寫,其風格類似於向投資人進行項目展示,用百字左右清楚闡述核心要點。
可著重說明:項目的核心定位、開發過程中的關鍵里程碑、當前行業現有方案存在的缺陷、項目旨在解決的核心痛點。即便項目尚處於半成品階段,也應清晰闡述項目規劃及其核心價值。
核心加分項 2:影響力證明(關鍵篩選因素)
優先提供項目代碼倉庫地址,並展示倉庫的 Star 數據,以此體現項目在行業內的認可度。
若 Star 數據不夠突出,可提供大模型 Token 消耗截圖,通過真實的高頻使用數據,有力證明自身的開發需求與活躍度,這是極具說服力的證明材料。
- 打賞
- 按讚
- 留言
- 轉發
- 分享
阿里“快樂小馬”上線!免費薅羊毛,動漫劇情號新神器?
別再死磕排隊 4 小時的模型了!阿里新出的 Happy Horse 速度起飛,註冊就送積分。 親測動漫風格極強,適合做“漫劇”賽道。 👇 詳細測評 + 白嫖攻略:
1️⃣ 註冊白嫖: 官網 註冊直接送 66 積分(約等於 2 次 5 秒視頻生成)。 不用充值也能玩,適合先嘗鮮。
2️⃣ 核心玩法(參考模式): 目前 Beta 版只支持“圖生視頻”。
✅ 優勢: 支持上傳最多 9 張參考圖! 這意味著你可以把分鏡圖一股腦丟進去,讓 AI 理解連續動作。
✅ 提示詞: 重點描述鏡頭運動(如:緩慢推近、跟隨)+ 氛圍(如:日系校園、陽光斑駁)。
3️⃣ 實測效果: 🚀 速度: 免費用戶排隊約 4 分鐘,比某舞快太多。 🎨 風格: 日系動漫感拉滿,光影效果(丁達爾效應)很絕。 ⚠️ 缺點: 暫時只有“首幀控制”,沒有“尾幀控制”。人物細節比原圖略有下降,免費版有水印且限 720P。
💡 搞錢思路: 目前適合做“動漫劇情號”或“動態漫”。 趁現在 Beta 期免費 + 速度快,趕緊批量生產內容佔坑。 等它開放“首尾幀控制”,就是製作連貫短劇的爆發期。
🔗 官網指路:
查看原文別再死磕排隊 4 小時的模型了!阿里新出的 Happy Horse 速度起飛,註冊就送積分。 親測動漫風格極強,適合做“漫劇”賽道。 👇 詳細測評 + 白嫖攻略:
1️⃣ 註冊白嫖: 官網 註冊直接送 66 積分(約等於 2 次 5 秒視頻生成)。 不用充值也能玩,適合先嘗鮮。
2️⃣ 核心玩法(參考模式): 目前 Beta 版只支持“圖生視頻”。
✅ 優勢: 支持上傳最多 9 張參考圖! 這意味著你可以把分鏡圖一股腦丟進去,讓 AI 理解連續動作。
✅ 提示詞: 重點描述鏡頭運動(如:緩慢推近、跟隨)+ 氛圍(如:日系校園、陽光斑駁)。
3️⃣ 實測效果: 🚀 速度: 免費用戶排隊約 4 分鐘,比某舞快太多。 🎨 風格: 日系動漫感拉滿,光影效果(丁達爾效應)很絕。 ⚠️ 缺點: 暫時只有“首幀控制”,沒有“尾幀控制”。人物細節比原圖略有下降,免費版有水印且限 720P。
💡 搞錢思路: 目前適合做“動漫劇情號”或“動態漫”。 趁現在 Beta 期免費 + 速度快,趕緊批量生產內容佔坑。 等它開放“首尾幀控制”,就是製作連貫短劇的爆發期。
🔗 官網指路:
- 打賞
- 按讚
- 留言
- 轉發
- 分享
為什麼有些人20出頭,就已經把人生看透了?
很多人以為:認知是熬出來的。
年紀越大、鹽吃越多、坑踩越多,腦子就越靈。
錯得離譜。
真正拉開差距的,從來不是年齡,而是輸入質量、思考密度、和經歷濃度。
你身邊肯定有這種年輕人:
二十多歲,看問題像開了天眼,做決策穩得嚇人,彷彿提前活成了“老妖精”。
他們不是裝深沉,是認知閉環早就甩開同齡人好幾條街。 到底是什麼,讓他們這麼早就“開掛”?
我拆出5個最狠的原因:
1. 他們從小就泡在高密度信息裡
別人刷短視頻、吃瓜、追星,他們早早就開始啃歷史興衰、拆人性邏輯、研究商業底層。
當同齡人還在為明星撕逼,他們已經在給大腦裝“社會操作系統”。
信息密度決定起點,他們直接把別人起步線甩在身後。
2. 他們被現實提前毒打,而且打得狠
認知很多時候不是想通的,是疼醒的。
家庭突變、突然斷供、被背叛、一次慘敗……
越早被迫獨立、自己扛事、自己買單,進化速度就越快。
真正的高手,都是被生活逼出來的。
3. 他們把每一次經歷都做成“復盤實驗室”
普通人:經歷→情緒→翻篇→白活。
高手:經歷→復盤→提煉規律→下次直接避坑。
他們不允許任何痛苦白流,每道傷疤最後都變成透視世界的X光。
4. 他們練就了“穿透表象”的本能
大眾被情緒帶著跑,他們永遠先問三句:
這件事的本質是什麼?
核心利益在哪?
底層邏輯通不通?
情緒、立場、觀點、事實,他們一眼拆開。
查看原文很多人以為:認知是熬出來的。
年紀越大、鹽吃越多、坑踩越多,腦子就越靈。
錯得離譜。
真正拉開差距的,從來不是年齡,而是輸入質量、思考密度、和經歷濃度。
你身邊肯定有這種年輕人:
二十多歲,看問題像開了天眼,做決策穩得嚇人,彷彿提前活成了“老妖精”。
他們不是裝深沉,是認知閉環早就甩開同齡人好幾條街。 到底是什麼,讓他們這麼早就“開掛”?
我拆出5個最狠的原因:
1. 他們從小就泡在高密度信息裡
別人刷短視頻、吃瓜、追星,他們早早就開始啃歷史興衰、拆人性邏輯、研究商業底層。
當同齡人還在為明星撕逼,他們已經在給大腦裝“社會操作系統”。
信息密度決定起點,他們直接把別人起步線甩在身後。
2. 他們被現實提前毒打,而且打得狠
認知很多時候不是想通的,是疼醒的。
家庭突變、突然斷供、被背叛、一次慘敗……
越早被迫獨立、自己扛事、自己買單,進化速度就越快。
真正的高手,都是被生活逼出來的。
3. 他們把每一次經歷都做成“復盤實驗室”
普通人:經歷→情緒→翻篇→白活。
高手:經歷→復盤→提煉規律→下次直接避坑。
他們不允許任何痛苦白流,每道傷疤最後都變成透視世界的X光。
4. 他們練就了“穿透表象”的本能
大眾被情緒帶著跑,他們永遠先問三句:
這件事的本質是什麼?
核心利益在哪?
底層邏輯通不通?
情緒、立場、觀點、事實,他們一眼拆開。
- 打賞
- 按讚
- 留言
- 轉發
- 分享
为什么有人每天只学2小时,效率却吊打熬夜党?🤫
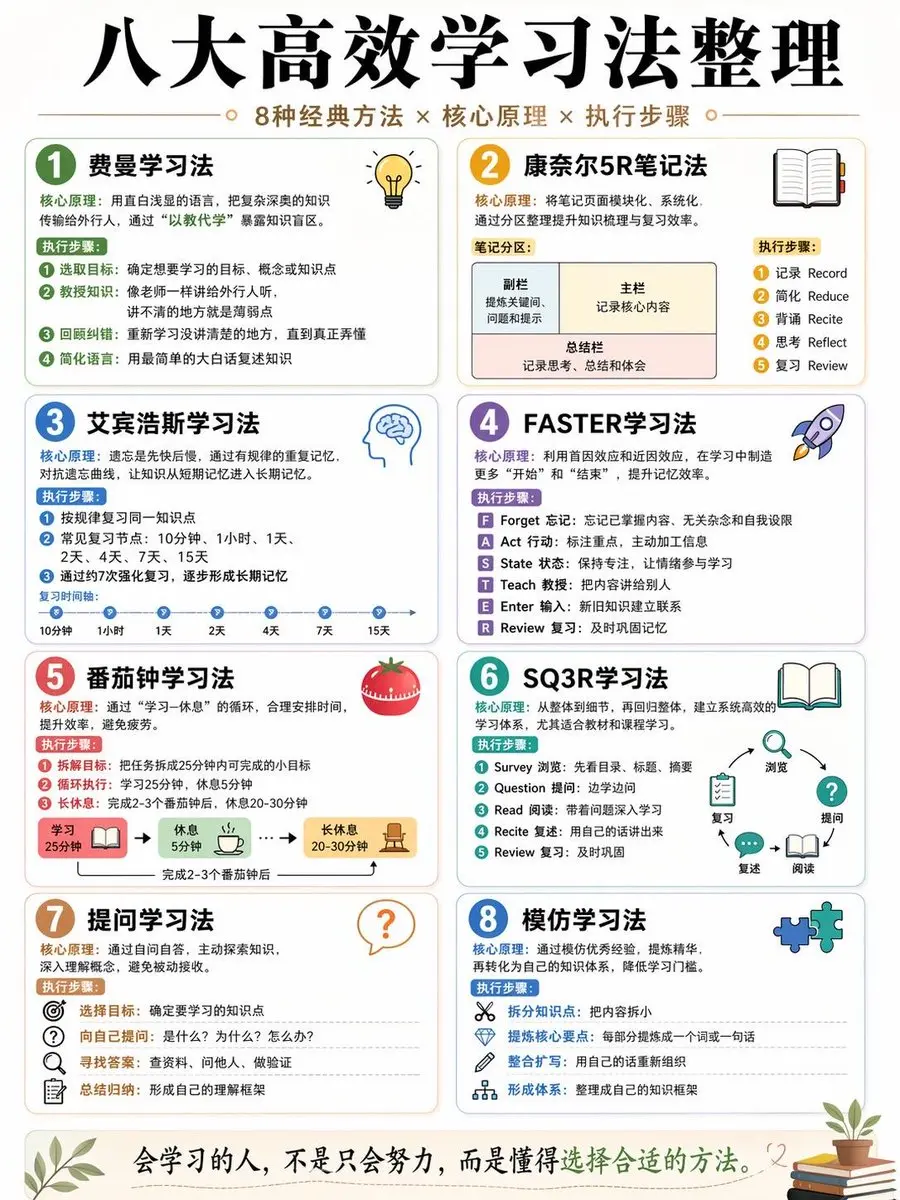
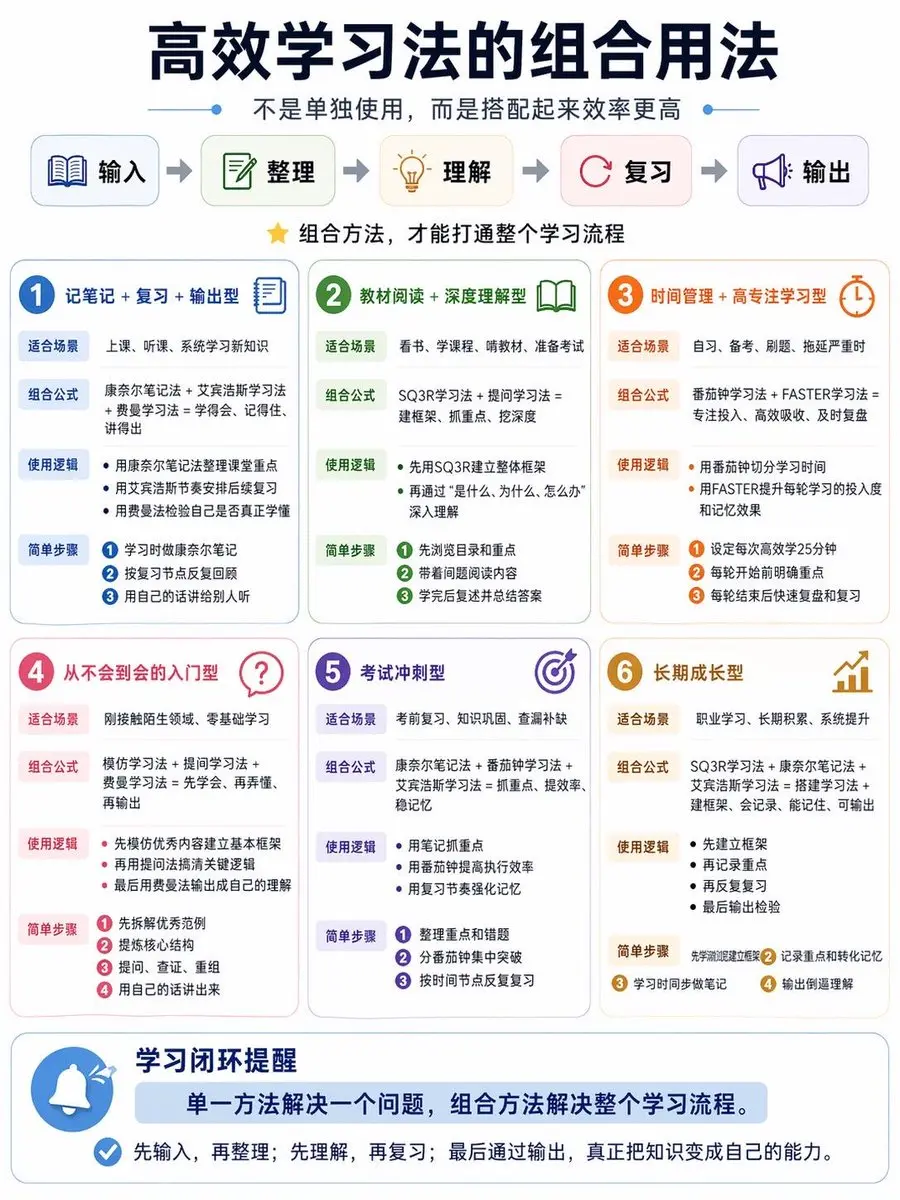
秘密就在于他们掌握了“学习的复利”。死记硬背早就过时了,你需要的是一套可以即插即用的【学习法组合拳】。
我把费曼学习法、康奈尔笔记、艾宾浩斯记忆曲线等8大硬核方法进行了底层逻辑重组,针对“考试冲刺”、“零基础入门”、“深度阅读”等场景给出了直接的【公式】。
花3分钟看懂这两张图,胜过瞎忙3个月。拿走不谢 👇
#学习技巧 #成長思維 #知识管理 #效率提升
查看原文秘密就在于他们掌握了“学习的复利”。死记硬背早就过时了,你需要的是一套可以即插即用的【学习法组合拳】。
我把费曼学习法、康奈尔笔记、艾宾浩斯记忆曲线等8大硬核方法进行了底层逻辑重组,针对“考试冲刺”、“零基础入门”、“深度阅读”等场景给出了直接的【公式】。
花3分钟看懂这两张图,胜过瞎忙3个月。拿走不谢 👇
#学习技巧 #成長思維 #知识管理 #效率提升
- 打賞
- 按讚
- 留言
- 轉發
- 分享
最強大的心理暗示只有四句話!幫你度過人生低谷。
查看原文- 打賞
- 按讚
- 留言
- 轉發
- 分享
別再只做“對標帳號”了!教你 10 分鐘把喜歡的博主“蒸餾”成 AI 技能,無限復用。
很多人做對標,只是抄了人家的句子(What),沒學到人家的腦子(How)。 結果就是:每次寫都要從頭想,累死。 真正的做法是:把博主的“操作系統”提取出來,變成你的 AI 技能包。
👇 分享一套我總結的 RIA-TV++ 五步萃取法:
1️⃣ R - Read(讀取)不要只看幾篇,要用工具(爬蟲/MCP)批量抓取該博主最火的 50-60 篇筆記。 关键字段:標題、正文、點贊、收藏、評論。 數據量不夠,AI 看不出規律。
2️⃣ I - Identify(識別三層系統)這是核心!讓 AI 分析這 60 篇內容,提取出三層邏輯:
認知層(Core Belief): 他相信什麼?(例:財經不是分析,是翻譯。把宏大事件翻譯成對用戶錢包的影響。)
策略層(Strategy): 他怎麼打?(例:97% 純視頻,絕不搞連載,單集獨立。)
內容層(Formulas): 爆款公式是什麼?(例:宏觀事件 + 對你的具體生活影響。)
3️⃣ A - Archive(歸檔)把上面識別出的三層內容,整理成一個結構化的 Markdown 文件。 ⚠️ 重點:這不是給人看的筆記,這是給 AI 看的“靜態資產”。 把流動的筆記變成靜態的資產,這才是 Skill 的核心。
4️⃣ T - Template(模板化/翻譯規則)把
查看原文很多人做對標,只是抄了人家的句子(What),沒學到人家的腦子(How)。 結果就是:每次寫都要從頭想,累死。 真正的做法是:把博主的“操作系統”提取出來,變成你的 AI 技能包。
👇 分享一套我總結的 RIA-TV++ 五步萃取法:
1️⃣ R - Read(讀取)不要只看幾篇,要用工具(爬蟲/MCP)批量抓取該博主最火的 50-60 篇筆記。 关键字段:標題、正文、點贊、收藏、評論。 數據量不夠,AI 看不出規律。
2️⃣ I - Identify(識別三層系統)這是核心!讓 AI 分析這 60 篇內容,提取出三層邏輯:
認知層(Core Belief): 他相信什麼?(例:財經不是分析,是翻譯。把宏大事件翻譯成對用戶錢包的影響。)
策略層(Strategy): 他怎麼打?(例:97% 純視頻,絕不搞連載,單集獨立。)
內容層(Formulas): 爆款公式是什麼?(例:宏觀事件 + 對你的具體生活影響。)
3️⃣ A - Archive(歸檔)把上面識別出的三層內容,整理成一個結構化的 Markdown 文件。 ⚠️ 重點:這不是給人看的筆記,這是給 AI 看的“靜態資產”。 把流動的筆記變成靜態的資產,這才是 Skill 的核心。
4️⃣ T - Template(模板化/翻譯規則)把
- 打賞
- 按讚
- 留言
- 轉發
- 分享
熱門話題
查看更多32.24萬 熱度
22.25萬 熱度
65.66萬 熱度
1274.9萬 熱度
1.28萬 熱度
置頂
🔥 WCTC S8 全球交易賽正式開賽!
8,000,000 USDT 超級獎池解鎖開啟
🏆 團隊賽:上半場正式開啟,預報名階段 5,500+ 戰隊現已集結
交易量收益額雙重比拼,解鎖上半場 1,800,000 USDT 獎池
🏆 個人賽:現貨、合約、TradFi、ETF、閃兌、跟單齊上陣
全場交易量比拼,瓜分 2,000,000 USDT 獎池
🏆 王者 PK 賽:零門檻參與,實時匹配享受戰鬥快感
收益率即時 PK,瓜分 1,600,000 USDT 獎池
活動時間:2026 年 4 月 23 日 16:00:00 - 2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即參與:https://www.gate.com/competition/wctc-s8
#WCTCS810,000 USDT 悬賞,尋找跟單金牌星探!🕵️
挖掘頂級帶單員,贏取高額跟單體驗金!
立即參與:https://www.gate.com/campaigns/4624
🎁 三大活動,獎金疊滿:
1️⃣ 慧眼識英:發帖推薦帶單員,分享跟單體驗,抽 100 位送 30 USDT!
2️⃣ 強力應援:曬出你的跟單截圖,為大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交達人:同步至 X/Twitter,憑流量贏取 100 USDT!
📍 標籤: #跟单金牌星探 #GateCopyTrading
⏰ 限時: 4/22 16:00 - 5/10 16:00 (UTC+8)
詳情:https://www.gate.com/announcements/article/50848✍️ Gate 廣場「創作者認證激勵計劃」進行中!
我們歡迎優質創作者積極創作,申請認證
贏取豪華代幣獎池、Gate 精美周邊、流量曝光等超過 $10,000+ 豐厚獎勵!
立即報名 👉 https://www.gate.com/questionnaire/7159
📕 認證申請步驟:
1️⃣ App 首頁底部進入【廣場】 → 點擊右上角頭像進入個人主頁
2️⃣ 點擊頭像右下角【申請認證】進入認證頁面,等待審核
讓優質內容被更多人看到,一起共建創作者社區!
活動詳情:https://www.gate.com/announcements/article/47889