Генеративний штучний інтелект вступив в епоху відео.
Першоджерело: Heart of the Machine
 Джерело зображення: Створено Unbounded AI
Джерело зображення: Створено Unbounded AI
Коли справа доходить до генерації відео, багато людей, ймовірно, в першу чергу думають про Gen-2 і Pika Labs. Але тільки зараз Meta оголосила, що перевершила їх обох у плані генерації відео та є більш гнучкими в монтажі.

 Цей “труба, танцюючий кролик” є останньою демоверсією, випущеною Meta. Як бачите, технологія Meta підтримує як гнучке редагування зображень (наприклад, перетворення «кролика» на «зайчика-труба», а потім «райдужного зайчика-труба»), так і генерацію відео з високою роздільною здатністю з тексту та зображень (наприклад, «зайчик-труба» радісно танцює).
Цей “труба, танцюючий кролик” є останньою демоверсією, випущеною Meta. Як бачите, технологія Meta підтримує як гнучке редагування зображень (наприклад, перетворення «кролика» на «зайчика-труба», а потім «райдужного зайчика-труба»), так і генерацію відео з високою роздільною здатністю з тексту та зображень (наприклад, «зайчик-труба» радісно танцює).
Насправді, тут є дві речі.
Гнучке редагування зображень виконується моделлю під назвою «Emu Edit». Він підтримує безкоштовне редагування зображень з текстом, включаючи локальне та глобальне редагування, видалення та додавання фону, перетворення кольорів та геометрії, виявлення та сегментацію тощо. Крім того, він точно дотримується інструкцій, гарантуючи, що пікселі на вхідному зображенні, які не пов’язані з інструкціями, залишаються недоторканими.
 Одягніть страуса в спідницю
Одягніть страуса в спідницю
Відео з високою роздільною здатністю генерується моделлю під назвою «Emu Video». Emu Video — це дифузійна модель відео Wensheng, яка здатна генерувати 4-секундне відео високої роздільної здатності 512x512 на основі тексту (довші відео також обговорюються в статті). Сувора оцінка на людях показала, що Emu Video отримала вищі бали як за якістю генерації, так і за точністю тексту порівняно з продуктивністю покоління Runway Gen-2 та Pika Labs. Ось як це буде виглядати:

 У своєму офіційному блозі Meta передбачила майбутнє обох технологій, включаючи дозвіл користувачам соціальних мереж створювати власні GIF-файли, меми та редагувати фотографії та зображення на свій розсуд. Щодо цього, Meta також згадала про це, коли випустила модель Emu на попередній конференції Meta Connect (див.: «Версія ChatGPT від Meta тут: благословення Llama 2, доступ до пошуку Bing, демонстрація Xiaozha в реальному часі»).
У своєму офіційному блозі Meta передбачила майбутнє обох технологій, включаючи дозвіл користувачам соціальних мереж створювати власні GIF-файли, меми та редагувати фотографії та зображення на свій розсуд. Щодо цього, Meta також згадала про це, коли випустила модель Emu на попередній конференції Meta Connect (див.: «Версія ChatGPT від Meta тут: благословення Llama 2, доступ до пошуку Bing, демонстрація Xiaozha в реальному часі»).
 Далі ми представимо кожну з цих двох нових моделей.
Далі ми представимо кожну з цих двох нових моделей.
EmuVideo
Велика графова модель Веньшен навчається на парах зображення-текст веб-масштабу для отримання високоякісних, різноманітних зображень. Хоча ці моделі можуть бути додатково адаптовані до генерації текст-відео (T2V) за допомогою пар відео-текст, генерація відео все ще відстає від генерації зображень з точки зору якості та різноманітності. У порівнянні з генерацією зображень, генерація відео є більш складною, оскільки вимагає моделювання більш високого виміру просторово-часового вихідного простору, який все ще може базуватися на текстових підказках. Крім того, відео-текстові набори даних, як правило, на порядок менші, ніж набори даних із зображенням-текстом.
Переважаючим способом генерації відео є використання дифузійної моделі для генерації всіх відеокадрів одночасно. На противагу цьому, в НЛП генерація довгих послідовностей формулюється як авторегресійна задача: передбачення наступного слова за умови раніше передбаченого слова. В результаті обумовлений сигнал подальшого прогнозу буде поступово ставати сильніше. Дослідники припускають, що покращене кондиціонування також важливе для генерації високоякісного відео, яке саме по собі є часовим рядом. Однак авторегресійне декодування за допомогою дифузійних моделей є складним завданням, оскільки генерація однокадрового зображення за допомогою таких моделей сама по собі вимагає кількох ітерацій.
У результаті дослідники Meta запропонували EMU VIDEO, який доповнює генерацію тексту у відео на основі дифузії явним проміжним етапом генерації зображень.
 Адреса:
Адреса:
Адреса проекту:
Зокрема, вони розклали проблему відео Веньшен на дві підзадачі: (1) генерація зображення на основі вхідної текстової підказки та (2) генерація відео на основі умов підкріплення зображення та тексту. Інтуїтивно надання моделі вихідного зображення та тексту полегшує генерацію відео, оскільки моделі потрібно лише передбачити, як зображення розвиватиметься в майбутньому.
 *Дослідники Meta розділили відео Wensheng на два етапи: спочатку згенеруйте зображення I за умови тексту p, а потім використовуйте сильніші умови – результуюче зображення та текст – для створення відео v. Щоб обмежити Model F зображенням, вони тимчасово зосередилися на зображенні та підключили його до двійкової маски, яка вказує, які кадри були обнулені, а також до шумного входу. *
*Дослідники Meta розділили відео Wensheng на два етапи: спочатку згенеруйте зображення I за умови тексту p, а потім використовуйте сильніші умови – результуюче зображення та текст – для створення відео v. Щоб обмежити Model F зображенням, вони тимчасово зосередилися на зображенні та підключили його до двійкової маски, яка вказує, які кадри були обнулені, а також до шумного входу. *
Оскільки набір відео-текстових даних набагато менший, ніж набір даних «зображення-текст», дослідники також ініціалізували свою модель «текст-відео» за допомогою попередньо навченої моделі «текст-зображення» (T2I). Вони визначили ключові дизайнерські рішення — зміну графіка дифузного шуму та багатоетапне навчання — для безпосереднього створення відео з високою роздільною здатністю 512 пікселів.
На відміну від методу генерації відео безпосередньо з тексту, їх метод декомпозиції явно генерує зображення при виведенні, що дозволяє їм легко зберегти візуальне різноманіття, стиль і якість моделі діаграми Веньшена (як показано на малюнку 1). ЦЕ ДОЗВОЛЯЄ ВІДЕО EMU ПЕРЕВЕРШУВАТИ ПРЯМІ МЕТОДИ T2V НАВІТЬ З ТИМИ Ж НАВЧАЛЬНИМИ ДАНИМИ, ОБСЯГОМ ОБЧИСЛЕНЬ І ПАРАМЕТРАМИ, ЩО НАВЧАЮТЬСЯ.

 Це дослідження показує, що якість генерації відео Wensheng може бути значно покращена за допомогою багатоступеневого методу навчання. Цей метод підтримує пряму генерацію відео з високою роздільною здатністю з роздільною здатністю 512 пікселів без необхідності використання деяких моделей глибоких каскадів, що використовуються в попередньому методі.
Це дослідження показує, що якість генерації відео Wensheng може бути значно покращена за допомогою багатоступеневого методу навчання. Цей метод підтримує пряму генерацію відео з високою роздільною здатністю з роздільною здатністю 512 пікселів без необхідності використання деяких моделей глибоких каскадів, що використовуються в попередньому методі.

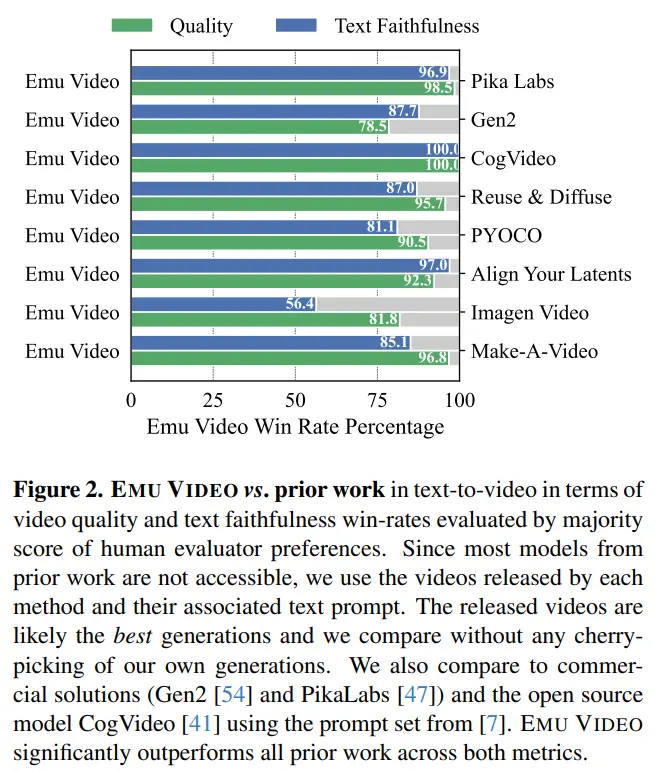
 Дослідники розробили надійний протокол оцінки людини JUICE, в якому оцінювачів попросили довести, що їхній вибір був правильним, роблячи вибір між парами. Як показано на малюнку 2, середні показники виграшу EMU VIDEO становлять 91,8% і 86,6% з точки зору якості та точності тексту, що значно випереджає всі попередні роботи, включаючи комерційні рішення, такі як Pika, Gen-2 та інші. ОКРІМ T2V, EMU VIDEO ТАКОЖ МОЖНА ВИКОРИСТОВУВАТИ ДЛЯ ГЕНЕРАЦІЇ ЗОБРАЖЕННЯ У ВІДЕО, ДЕ МОДЕЛЬ ГЕНЕРУЄ ВІДЕО НА ОСНОВІ НАДАНИХ КОРИСТУВАЧЕМ ЗОБРАЖЕНЬ І ТЕКСТОВИХ ПІДКАЗОК. У цьому випадку результати генерації EMU VIDEO на 96% кращі, ніж у VideoComposer.
Дослідники розробили надійний протокол оцінки людини JUICE, в якому оцінювачів попросили довести, що їхній вибір був правильним, роблячи вибір між парами. Як показано на малюнку 2, середні показники виграшу EMU VIDEO становлять 91,8% і 86,6% з точки зору якості та точності тексту, що значно випереджає всі попередні роботи, включаючи комерційні рішення, такі як Pika, Gen-2 та інші. ОКРІМ T2V, EMU VIDEO ТАКОЖ МОЖНА ВИКОРИСТОВУВАТИ ДЛЯ ГЕНЕРАЦІЇ ЗОБРАЖЕННЯ У ВІДЕО, ДЕ МОДЕЛЬ ГЕНЕРУЄ ВІДЕО НА ОСНОВІ НАДАНИХ КОРИСТУВАЧЕМ ЗОБРАЖЕНЬ І ТЕКСТОВИХ ПІДКАЗОК. У цьому випадку результати генерації EMU VIDEO на 96% кращі, ніж у VideoComposer.
 Як видно з показаної демонстрації, EMU VIDEO вже може підтримувати 4-секундну генерацію відео. У статті вони також досліджують способи збільшення тривалості відео. За допомогою невеликої архітектурної модифікації, за словами авторів, вони можуть обмежити модель на Т-подібному кадрі та розширити відео. ТАК, ВОНИ НАВЧИЛИ ВАРІАНТ ВІДЕО ЕМУ ГЕНЕРУВАТИ НАСТУПНІ 16 КАДРІВ ЗА УМОВИ «МИНУЛИХ» 16 КАДРІВ. При розгортанні відео вони використовують іншу текстову підказку майбутнього, ніж оригінальне відео, як показано на малюнку 7. Вони виявили, що розширене відео слідує як оригінальному відео, так і майбутнім текстовим підказкам.
Як видно з показаної демонстрації, EMU VIDEO вже може підтримувати 4-секундну генерацію відео. У статті вони також досліджують способи збільшення тривалості відео. За допомогою невеликої архітектурної модифікації, за словами авторів, вони можуть обмежити модель на Т-подібному кадрі та розширити відео. ТАК, ВОНИ НАВЧИЛИ ВАРІАНТ ВІДЕО ЕМУ ГЕНЕРУВАТИ НАСТУПНІ 16 КАДРІВ ЗА УМОВИ «МИНУЛИХ» 16 КАДРІВ. При розгортанні відео вони використовують іншу текстову підказку майбутнього, ніж оригінальне відео, як показано на малюнку 7. Вони виявили, що розширене відео слідує як оригінальному відео, так і майбутнім текстовим підказкам.
 Emu Edit: точне редагування зображень
Emu Edit: точне редагування зображень
Мільйони людей щодня використовують редагування зображень. Однак популярні інструменти для редагування зображень або вимагають значного досвіду та займають багато часу у використанні, або є дуже обмеженими та пропонують лише набір попередньо визначених операцій редагування, таких як спеціальні фільтри. На цьому етапі редагування зображень на основі інструкцій намагається змусити користувачів використовувати інструкції природною мовою, щоб обійти ці обмеження. Наприклад, користувач може надати зображення моделі та доручити їй «одягнути ему в костюм пожежника» (див. Малюнок 1).
 Однак, хоча моделі редагування зображень на основі інструкцій, такі як InstructPix2Pix, можна використовувати для обробки різноманітних заданих інструкцій, їх часто важко інтерпретувати та точно виконувати інструкції. Крім того, ці моделі мають обмежені можливості узагальнення і часто не в змозі виконувати завдання, які дещо відрізняються від тих, на яких вони були навчені (див. Малюнок 3), наприклад, кроленя сурмить у трубу райдужного кольору, а інші моделі або фарбують кролика в райдужний колір, або безпосередньо генерують райдужну трубу.
Однак, хоча моделі редагування зображень на основі інструкцій, такі як InstructPix2Pix, можна використовувати для обробки різноманітних заданих інструкцій, їх часто важко інтерпретувати та точно виконувати інструкції. Крім того, ці моделі мають обмежені можливості узагальнення і часто не в змозі виконувати завдання, які дещо відрізняються від тих, на яких вони були навчені (див. Малюнок 3), наприклад, кроленя сурмить у трубу райдужного кольору, а інші моделі або фарбують кролика в райдужний колір, або безпосередньо генерують райдужну трубу.
 Щоб вирішити ці проблеми, Meta представила Emu Edit, першу модель редагування зображень, навчену на широкому та різноманітному спектрі завдань, яка може виконувати редагування у довільній формі на основі команд, включаючи локальне та глобальне редагування, видалення та додавання фону, зміни кольору та геометричні перетворення, а також виявлення та сегментацію.
Щоб вирішити ці проблеми, Meta представила Emu Edit, першу модель редагування зображень, навчену на широкому та різноманітному спектрі завдань, яка може виконувати редагування у довільній формі на основі команд, включаючи локальне та глобальне редагування, видалення та додавання фону, зміни кольору та геометричні перетворення, а також виявлення та сегментацію.
 Адреса:
Адреса:
Адреса проекту:
На відміну від багатьох сучасних генеративних моделей штучного інтелекту, Emu Edit може точно слідувати інструкціям, гарантуючи, що непов’язані пікселі на вхідному зображенні залишаться недоторканими. Наприклад, якщо користувач дає команду «прибрати цуценя на траву», картинка після видалення об’єкта ледь помітна.
 Видаленням тексту в нижньому лівому куті зображення і зміною фону зображення також буде займатися Emu Edit:
Видаленням тексту в нижньому лівому куті зображення і зміною фону зображення також буде займатися Emu Edit:
 Щоб навчити цю модель, Meta розробила набір даних із 10 мільйонів синтетичних зразків, кожен з яких містить вхідне зображення, опис завдання, яке потрібно виконати, і цільове вихідне зображення. В результаті Emu Edit показує безпрецедентні результати редагування з точки зору точності команд і якості зображення.
Щоб навчити цю модель, Meta розробила набір даних із 10 мільйонів синтетичних зразків, кожен з яких містить вхідне зображення, опис завдання, яке потрібно виконати, і цільове вихідне зображення. В результаті Emu Edit показує безпрецедентні результати редагування з точки зору точності команд і якості зображення.
На рівні методології моделі, навчені Meta, можуть виконувати шістнадцять різних завдань з редагування зображень, що охоплюють регіональне редагування, редагування довільної форми та завдання комп’ютерного зору, усі з яких сформульовані як генеративні завдання, і Meta також розробила унікальний конвеєр керування даними для кожного завдання. Meta виявила, що зі збільшенням кількості навчальних завдань зростає і продуктивність Emu Edit.
По-друге, щоб ефективно справлятися з широким спектром завдань, Meta представила концепцію вбудовування вивчених завдань, яка використовується для спрямування процесу генерації в правильному напрямку завдання збірки. Зокрема, для кожного завдання ця стаття вивчає унікальний вектор вбудовування завдань та інтегрує його в модель через взаємодію перехресної уваги та додає його до вбудовування за кроком у часі. Результати показують, що вбудовування навчальних завдань значно підвищує здатність моделі точно міркувати з інструкцій довільної форми та виконувати правильні редагування.
У квітні цього року Meta запустила модель штучного інтелекту «Split Everything», і ефект був настільки приголомшливим, що багато людей почали замислюватися, чи існує сфера резюме досі. Всього за кілька місяців Meta запустила Emu Video та Emu Edit у сфері зображень та відео, і ми можемо лише сказати, що сфера генеративного ШІ справді надто мінлива.

