A IA generativa entrou na era do vídeo.
Fonte original: Heart of the Machine
 Fonte da imagem: Gerado por Unbounded AI
Fonte da imagem: Gerado por Unbounded AI
Quando se trata de geração de vídeo, muitas pessoas provavelmente pensam em Gen-2 e Pika Labs primeiro. Mas só agora, a Meta anunciou que eles superaram ambos em termos de geração de vídeo e são mais flexíveis na edição.

 Este “trompete, coelho dançante” é a mais recente demo lançada pela Meta. Como você pode ver, a tecnologia da Meta suporta edição de imagem flexível (por exemplo, transformando um “coelho” em um “coelhinho de trompete” e, em seguida, um “coelhinho de trompete colorido de arco-íris”) e gerando vídeo de alta resolução a partir de texto e imagens (por exemplo, ter um “coelhinho de trompete” dançando feliz).
Este “trompete, coelho dançante” é a mais recente demo lançada pela Meta. Como você pode ver, a tecnologia da Meta suporta edição de imagem flexível (por exemplo, transformando um “coelho” em um “coelhinho de trompete” e, em seguida, um “coelhinho de trompete colorido de arco-íris”) e gerando vídeo de alta resolução a partir de texto e imagens (por exemplo, ter um “coelhinho de trompete” dançando feliz).
Na verdade, há duas coisas envolvidas.
A edição de imagem flexível é feita por um modelo chamado “Emu Edit”. Ele suporta edição gratuita de imagens com texto, incluindo edição local e global, remoção e adição de fundos, conversões de cor e geometria, deteção e segmentação e muito mais. Além disso, ele segue as instruções com precisão, garantindo que os pixels na imagem de entrada que não estão relacionados às instruções permaneçam intactos.
 Vista a avestruz com uma saia
Vista a avestruz com uma saia
O vídeo de alta resolução é gerado por um modelo chamado “Emu Video”. Emu Video é um modelo baseado em difusão de vídeo Wensheng que é capaz de gerar 512x512 4 segundos de vídeo de alta resolução com base em texto (vídeos mais longos também são discutidos no artigo). Uma avaliação humana rigorosa mostrou que o Emu Video obteve pontuações mais altas tanto na qualidade da geração quanto na fidelidade do texto em comparação com o desempenho da geração Gen-2 e Pika Labs da Runway. Veja como ficará:

 Em seu blog oficial, a Meta imaginou o futuro de ambas as tecnologias, incluindo permitir que os usuários de mídia social gerem seus próprios GIFs, memes e editem fotos e imagens como desejarem. Em relação a isso, a Meta também mencionou isso quando lançou o modelo Emu na conferência anterior do Meta Connect (veja: “A versão da Meta do ChatGPT está aqui: bênção Llama 2, acesso à pesquisa do Bing, demonstração ao vivo Xiaozha”).
Em seu blog oficial, a Meta imaginou o futuro de ambas as tecnologias, incluindo permitir que os usuários de mídia social gerem seus próprios GIFs, memes e editem fotos e imagens como desejarem. Em relação a isso, a Meta também mencionou isso quando lançou o modelo Emu na conferência anterior do Meta Connect (veja: “A versão da Meta do ChatGPT está aqui: bênção Llama 2, acesso à pesquisa do Bing, demonstração ao vivo Xiaozha”).
 Em seguida, apresentaremos cada um desses dois novos modelos.
Em seguida, apresentaremos cada um desses dois novos modelos.
EmuVideo
O grande modelo gráfico de Wensheng é treinado em pares imagem-texto em escala web para produzir imagens diversificadas e de alta qualidade. Embora estes modelos possam ser ainda mais adaptados à geração de texto para vídeo (T2V) através da utilização de pares vídeo-texto, a geração de vídeo ainda está atrasada em relação à geração de imagens em termos de qualidade e variedade. Em comparação com a geração de imagens, a geração de vídeo é mais desafiadora porque requer a modelagem de uma dimensão maior do espaço de saída espaço-temporal, que ainda pode ser baseado em prompts de texto. Além disso, os conjuntos de dados de vídeo-texto são normalmente uma ordem de grandeza menor do que os conjuntos de dados de texto-imagem.
O modo predominante de geração de vídeo é usar um modelo de difusão para gerar todos os quadros de vídeo de uma só vez. Em contraste gritante, na PNL, a geração de sequências longas é formulada como um problema autorregressivo: prever a próxima palavra na condição de uma palavra previamente prevista. Como resultado, o sinal condicionante da previsão subsequente tornar-se-á gradualmente mais forte. Os pesquisadores levantam a hipótese de que o condicionamento aprimorado também é importante para a geração de vídeo de alta qualidade, que é em si uma série temporal. No entanto, a decodificação autorregressiva com modelos de difusão é um desafio, pois gerar uma imagem de quadro único com a ajuda de tais modelos requer múltiplas iterações em si.
Como resultado, os pesquisadores da Meta propuseram o EMU VIDEO, que aumenta a geração de texto para vídeo baseada em difusão com uma etapa de geração de imagem intermediária explícita.
 Endereço:
Endereço:
Endereço do projeto:
Especificamente, eles decompuseram o problema de vídeo de Wensheng em dois sub-problemas: (1) gerar uma imagem com base no prompt de texto de entrada, e (2) gerar um vídeo com base nas condições de reforço da imagem e do texto. Intuitivamente, dar ao modelo uma imagem inicial e texto facilita a geração de vídeo, pois o modelo só precisa prever como a imagem evoluirá no futuro.
 *Os pesquisadores da Meta dividiram o vídeo de Wensheng em duas etapas: primeiro gerar a imagem I condicional ao texto p e, em seguida, usar condições mais fortes – a imagem e o texto resultantes – para gerar o vídeo v. Para restringir o Modelo F com uma imagem, eles se concentraram temporariamente na imagem e a conectaram a uma máscara binária que indica quais quadros foram zerados, bem como uma entrada barulhenta. *
*Os pesquisadores da Meta dividiram o vídeo de Wensheng em duas etapas: primeiro gerar a imagem I condicional ao texto p e, em seguida, usar condições mais fortes – a imagem e o texto resultantes – para gerar o vídeo v. Para restringir o Modelo F com uma imagem, eles se concentraram temporariamente na imagem e a conectaram a uma máscara binária que indica quais quadros foram zerados, bem como uma entrada barulhenta. *
Como o conjunto de dados vídeo-texto é muito menor do que o conjunto de dados imagem-texto, os pesquisadores também inicializaram seu modelo de texto para vídeo com um modelo de imagem de texto pré-treinada (T2I) com peso congelado. Eles identificaram as principais decisões de projeto — alterando a programação de ruído difuso e o treinamento em vários estágios — para produzir diretamente vídeo de alta resolução de 512 px.
Ao contrário do método de gerar um vídeo diretamente do texto, seu método de decomposição gera explicitamente uma imagem ao inferir, o que lhes permite preservar facilmente a diversidade visual, estilo e qualidade do modelo de diagrama de Wensheng (como mostrado na Figura 1). ISSO PERMITE QUE O VÍDEO DA EMU SUPERE OS MÉTODOS T2V DIRETOS, MESMO COM OS MESMOS DADOS DE TREINAMENTO, QUANTIDADE DE COMPUTAÇÃO E PARÂMETROS TREINÁVEIS.

 Este estudo mostra que a qualidade da geração de vídeo Wensheng pode ser muito melhorada através de um método de treinamento de vários estágios. Este método suporta a geração direta de vídeo de alta resolução em 512px sem a necessidade de alguns dos modelos em cascata profunda usados no método anterior.
Este estudo mostra que a qualidade da geração de vídeo Wensheng pode ser muito melhorada através de um método de treinamento de vários estágios. Este método suporta a geração direta de vídeo de alta resolução em 512px sem a necessidade de alguns dos modelos em cascata profunda usados no método anterior.

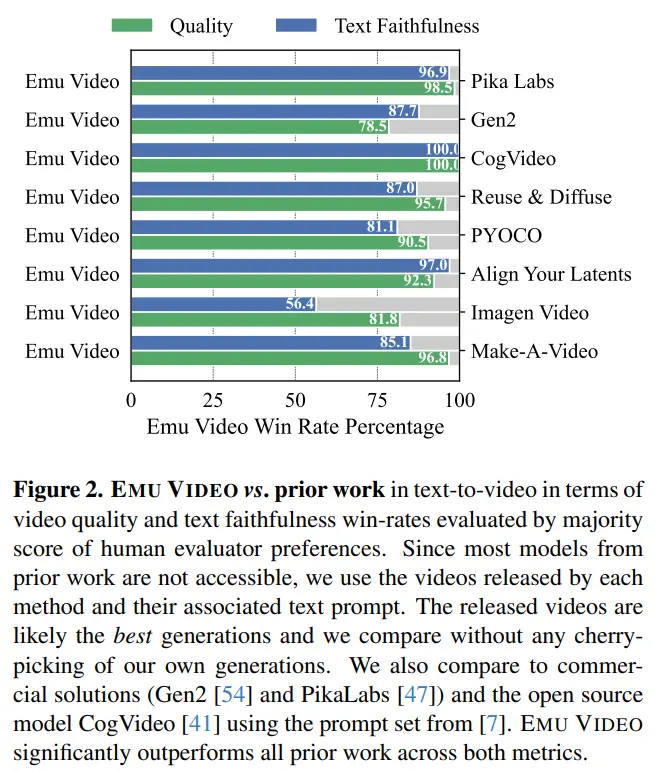
 Os pesquisadores desenvolveram um protocolo robusto de avaliação humana, o JUICE, no qual os avaliadores foram solicitados a provar que sua escolha estava correta ao fazer uma escolha entre pares. Como mostrado na Figura 2, as taxas médias de vitória do EMU VIDEO de 91,8% e 86,6% em termos de qualidade e fidelidade de texto estão muito à frente de todo o trabalho inicial, incluindo soluções comerciais como Pika, Gen-2 e outros. ALÉM DO T2V, O VÍDEO EMU TAMBÉM PODE SER USADO PARA GERAÇÃO DE IMAGEM PARA VÍDEO, ONDE O MODELO GERA VÍDEO COM BASE EM IMAGENS FORNECIDAS PELO USUÁRIO E PROMPTS DE TEXTO. Neste caso, os resultados da geração do EMU VIDEO são 96% melhores do que o VideoComposer.
Os pesquisadores desenvolveram um protocolo robusto de avaliação humana, o JUICE, no qual os avaliadores foram solicitados a provar que sua escolha estava correta ao fazer uma escolha entre pares. Como mostrado na Figura 2, as taxas médias de vitória do EMU VIDEO de 91,8% e 86,6% em termos de qualidade e fidelidade de texto estão muito à frente de todo o trabalho inicial, incluindo soluções comerciais como Pika, Gen-2 e outros. ALÉM DO T2V, O VÍDEO EMU TAMBÉM PODE SER USADO PARA GERAÇÃO DE IMAGEM PARA VÍDEO, ONDE O MODELO GERA VÍDEO COM BASE EM IMAGENS FORNECIDAS PELO USUÁRIO E PROMPTS DE TEXTO. Neste caso, os resultados da geração do EMU VIDEO são 96% melhores do que o VideoComposer.
 Como você pode ver na demonstração mostrada, EMU VIDEO já pode suportar geração de vídeo de 4 segundos. No artigo, eles também exploram maneiras de aumentar a duração do vídeo. Com uma pequena modificação arquitetônica, os autores dizem que podem restringir o modelo em um quadro em T e estender o vídeo. ENTÃO, ELES TREINARAM UMA VARIANTE DE VÍDEO EMU PARA GERAR OS PRÓXIMOS 16 QUADROS NA CONDIÇÃO DE “PASSADO” 16 QUADROS. Ao expandir o vídeo, eles usam um prompt de texto futuro diferente do vídeo original, como mostra a Figura 7. Eles descobriram que o vídeo estendido segue tanto o vídeo original quanto os prompts de texto futuros.
Como você pode ver na demonstração mostrada, EMU VIDEO já pode suportar geração de vídeo de 4 segundos. No artigo, eles também exploram maneiras de aumentar a duração do vídeo. Com uma pequena modificação arquitetônica, os autores dizem que podem restringir o modelo em um quadro em T e estender o vídeo. ENTÃO, ELES TREINARAM UMA VARIANTE DE VÍDEO EMU PARA GERAR OS PRÓXIMOS 16 QUADROS NA CONDIÇÃO DE “PASSADO” 16 QUADROS. Ao expandir o vídeo, eles usam um prompt de texto futuro diferente do vídeo original, como mostra a Figura 7. Eles descobriram que o vídeo estendido segue tanto o vídeo original quanto os prompts de texto futuros.
 Emu Edit: Edição de imagem precisa
Emu Edit: Edição de imagem precisa
Milhões de pessoas usam a edição de imagens todos os dias. No entanto, as ferramentas populares de edição de imagem exigem experiência considerável e são demoradas para usar, ou são muito limitadas e oferecem apenas um conjunto de operações de edição predefinidas, como filtros específicos. Nesta fase, a edição de imagem baseada em instruções tenta fazer com que os usuários usem instruções de linguagem natural para contornar essas limitações. Por exemplo, um usuário pode fornecer uma imagem a um modelo e instruí-lo a “vestir uma ema com uma fantasia de bombeiro” (veja a Figura 1).
 No entanto, embora modelos de edição de imagem baseados em instruções como o InstructPix2Pix possam ser usados para lidar com uma variedade de instruções dadas, eles geralmente são difíceis de interpretar e executar instruções com precisão. Além disso, esses modelos têm capacidades limitadas de generalização e muitas vezes são incapazes de executar tarefas ligeiramente diferentes daquelas em que foram treinados (ver Figura 3), como fazer um coelho bebê tocar uma trombeta com as cores do arco-íris e outros modelos tingindo o coelho com a cor do arco-íris ou gerando diretamente uma trombeta com as cores do arco-íris.
No entanto, embora modelos de edição de imagem baseados em instruções como o InstructPix2Pix possam ser usados para lidar com uma variedade de instruções dadas, eles geralmente são difíceis de interpretar e executar instruções com precisão. Além disso, esses modelos têm capacidades limitadas de generalização e muitas vezes são incapazes de executar tarefas ligeiramente diferentes daquelas em que foram treinados (ver Figura 3), como fazer um coelho bebê tocar uma trombeta com as cores do arco-íris e outros modelos tingindo o coelho com a cor do arco-íris ou gerando diretamente uma trombeta com as cores do arco-íris.
 Para resolver esses problemas, a Meta introduziu o Emu Edit, o primeiro modelo de edição de imagem treinado em uma ampla e diversificada gama de tarefas, que pode realizar edições de forma livre com base em comandos, incluindo edição local e global, remoção e adição de fundos, alterações de cor e transformações geométricas, e deteção e segmentação.
Para resolver esses problemas, a Meta introduziu o Emu Edit, o primeiro modelo de edição de imagem treinado em uma ampla e diversificada gama de tarefas, que pode realizar edições de forma livre com base em comandos, incluindo edição local e global, remoção e adição de fundos, alterações de cor e transformações geométricas, e deteção e segmentação.
 Endereço:
Endereço:
Endereço do projeto:
Ao contrário de muitos dos modelos de IA generativa atuais, o Emu Edit pode seguir instruções com precisão, garantindo que os pixels não relacionados na imagem de entrada permaneçam intactos. Por exemplo, se o usuário der o comando “remover o cachorro na grama”, a imagem depois de remover o objeto é quase impercetível.
 Remover o texto no canto inferior esquerdo da imagem e alterar o fundo da imagem também será tratado pelo Emu Edit:
Remover o texto no canto inferior esquerdo da imagem e alterar o fundo da imagem também será tratado pelo Emu Edit:
 Para treinar esse modelo, a Meta desenvolveu um conjunto de dados de 10 milhões de amostras sintéticas, cada uma contendo uma imagem de entrada, uma descrição da tarefa a ser executada e uma imagem de saída de destino. Como resultado, o Emu Edit mostra resultados de edição sem precedentes em termos de fidelidade de comando e qualidade de imagem.
Para treinar esse modelo, a Meta desenvolveu um conjunto de dados de 10 milhões de amostras sintéticas, cada uma contendo uma imagem de entrada, uma descrição da tarefa a ser executada e uma imagem de saída de destino. Como resultado, o Emu Edit mostra resultados de edição sem precedentes em termos de fidelidade de comando e qualidade de imagem.
No nível da metodologia, os modelos metatreinados podem executar dezesseis tarefas diferentes de edição de imagem, abrangendo edição baseada em região, edição de forma livre e tarefas de visão computacional, todas formuladas como tarefas generativas, e a Meta também desenvolveu um pipeline de gerenciamento de dados exclusivo para cada tarefa. A Meta descobriu que, à medida que o número de tarefas de treinamento aumenta, o mesmo acontece com o desempenho do Emu Edit.
Em segundo lugar, a fim de lidar efetivamente com uma ampla variedade de tarefas, a Meta introduziu o conceito de incorporação de tarefas aprendidas, que é usado para orientar o processo de geração na direção certa da tarefa de construção. Especificamente, para cada tarefa, este artigo aprende um vetor de incorporação de tarefa exclusivo e o integra no modelo por meio da interação de atenção cruzada e o adiciona à incorporação de etapas de tempo. Os resultados mostram que a incorporação de tarefas de aprendizagem melhora significativamente a capacidade do modelo de raciocinar com precisão a partir de instruções de forma livre e realizar edições corretas.
Em abril deste ano, a Meta lançou o modelo de IA “Split Everything”, e o efeito foi tão incrível que muitas pessoas começaram a se perguntar se o campo CV ainda existe. Em apenas alguns meses, a Meta lançou Emu Video e Emu Edit no campo de imagens e vídeos, e só podemos dizer que o campo da IA generativa é realmente muito volátil.

