Generative AI đã bước vào thời đại video.
Nguồn gốc: Heart of the Machine
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Khi nói đến thế hệ video, nhiều người có thể nghĩ đến Gen-2 và Pika Labs đầu tiên. Nhưng mới đây, Meta thông báo rằng họ đã vượt qua cả hai về mặt tạo video và linh hoạt hơn trong việc chỉnh sửa.

 “Trumpet, dancing rabbit” này là bản demo mới nhất được Meta phát hành. Như bạn có thể thấy, công nghệ của Meta hỗ trợ cả chỉnh sửa hình ảnh linh hoạt (ví dụ: biến “thỏ” thành “thỏ kèn” và sau đó là “thỏ kèn màu cầu vồng”) và tạo video có độ phân giải cao từ văn bản và hình ảnh (ví dụ: nhảy “thỏ kèn” một cách vui vẻ).
“Trumpet, dancing rabbit” này là bản demo mới nhất được Meta phát hành. Như bạn có thể thấy, công nghệ của Meta hỗ trợ cả chỉnh sửa hình ảnh linh hoạt (ví dụ: biến “thỏ” thành “thỏ kèn” và sau đó là “thỏ kèn màu cầu vồng”) và tạo video có độ phân giải cao từ văn bản và hình ảnh (ví dụ: nhảy “thỏ kèn” một cách vui vẻ).
Trên thực tế, có hai điều liên quan.
Chỉnh sửa hình ảnh linh hoạt được thực hiện bởi một mô hình có tên là “Emu Edit”. Nó hỗ trợ chỉnh sửa miễn phí hình ảnh bằng văn bản, bao gồm chỉnh sửa cục bộ và toàn cầu, xóa và thêm hình nền, chuyển đổi màu sắc và hình học, phát hiện và phân đoạn, v.v. Ngoài ra, nó tuân theo các hướng dẫn một cách chính xác, đảm bảo rằng các pixel trong hình ảnh đầu vào không liên quan đến các hướng dẫn vẫn còn nguyên.
 * Mặc váy cho đà điểu *
* Mặc váy cho đà điểu *
Video độ phân giải cao được tạo bởi một mô hình có tên là “Emu Video”. Emu Video là một mô hình dựa trên khuếch tán của video Wensheng có khả năng tạo video độ phân giải cao 512x512 4 giây dựa trên văn bản (video dài hơn cũng được thảo luận trong bài báo). Một đánh giá nghiêm ngặt của con người cho thấy Emu Video đạt điểm cao hơn cả về chất lượng của thế hệ và độ trung thực của văn bản so với hiệu suất thế hệ Gen-2 của Runway và Pika Labs. Đây là cách nó sẽ trông:

 Trong blog chính thức của mình, Meta đã hình dung ra tương lai của cả hai công nghệ, bao gồm cho phép người dùng mạng xã hội tạo GIF, meme của riêng họ và chỉnh sửa ảnh và hình ảnh theo ý muốn. Về điều này, Meta cũng đã đề cập đến điều này khi phát hành mô hình Emu tại hội nghị Meta Connect trước đó (xem: “Phiên bản ChatGPT của Meta ở đây: Llama 2 blessing, access to Bing search, Xiaozha live demo”).
Trong blog chính thức của mình, Meta đã hình dung ra tương lai của cả hai công nghệ, bao gồm cho phép người dùng mạng xã hội tạo GIF, meme của riêng họ và chỉnh sửa ảnh và hình ảnh theo ý muốn. Về điều này, Meta cũng đã đề cập đến điều này khi phát hành mô hình Emu tại hội nghị Meta Connect trước đó (xem: “Phiên bản ChatGPT của Meta ở đây: Llama 2 blessing, access to Bing search, Xiaozha live demo”).
 Tiếp theo, chúng tôi sẽ giới thiệu từng mô hình trong số hai mô hình mới này.
Tiếp theo, chúng tôi sẽ giới thiệu từng mô hình trong số hai mô hình mới này.
EmuVideo
Mô hình đồ thị Wensheng lớn được đào tạo trên các cặp hình ảnh-văn bản quy mô web để tạo ra hình ảnh đa dạng, chất lượng cao. Mặc dù các mô hình này có thể được điều chỉnh thêm để tạo văn bản thành video (T2V) thông qua việc sử dụng các cặp văn bản video, việc tạo video vẫn tụt hậu so với việc tạo hình ảnh về chất lượng và sự đa dạng. So với tạo hình ảnh, việc tạo video khó khăn hơn vì nó đòi hỏi phải mô hình hóa một chiều cao hơn của không gian đầu ra không gian thời gian, vẫn có thể dựa trên lời nhắc văn bản. Ngoài ra, bộ dữ liệu văn bản video thường có độ lớn nhỏ hơn bộ dữ liệu văn bản hình ảnh.
Chế độ phổ biến của việc tạo video là sử dụng mô hình khuếch tán để tạo tất cả các khung hình video cùng một lúc. Ngược lại, trong NLP, tạo chuỗi dài được xây dựng như một vấn đề tự hồi quy: dự đoán từ tiếp theo với điều kiện của một từ đã dự đoán trước đó. Do đó, tín hiệu điều hòa của dự đoán tiếp theo sẽ dần trở nên mạnh mẽ hơn. Các nhà nghiên cứu đưa ra giả thuyết rằng điều hòa nâng cao cũng rất quan trọng đối với việc tạo video chất lượng cao, bản thân nó là một chuỗi thời gian. Tuy nhiên, việc giải mã tự hồi quy với các mô hình khuếch tán là một thách thức, vì việc tạo ra một hình ảnh một khung hình với sự trợ giúp của các mô hình như vậy đòi hỏi nhiều lần lặp lại.
Do đó, các nhà nghiên cứu của Meta đã đề xuất EMU VIDEO, giúp tăng cường tạo văn bản thành video dựa trên khuếch tán với bước tạo hình ảnh trung gian rõ ràng.
 Địa chỉ:
Địa chỉ:
Địa chỉ dự án:
Cụ thể, họ đã phân tách vấn đề video Wensheng thành hai vấn đề phụ: (1) tạo hình ảnh dựa trên lời nhắc văn bản đầu vào và (2) tạo video dựa trên các điều kiện củng cố của hình ảnh và văn bản. Theo trực giác, việc cung cấp cho mô hình hình ảnh và văn bản bắt đầu giúp tạo video dễ dàng hơn, vì mô hình chỉ cần dự đoán hình ảnh sẽ phát triển như thế nào trong tương lai.
 *Các nhà nghiên cứu của Meta đã chia video Wensheng thành hai bước: đầu tiên tạo hình ảnh I có điều kiện trên văn bản p, sau đó sử dụng các điều kiện mạnh hơn - hình ảnh và văn bản kết quả - để tạo video v. Để hạn chế Model F với một hình ảnh, họ tạm thời tập trung vào hình ảnh và kết nối nó với mặt nạ nhị phân cho biết khung hình nào bằng không, cũng như đầu vào nhiễu. *
*Các nhà nghiên cứu của Meta đã chia video Wensheng thành hai bước: đầu tiên tạo hình ảnh I có điều kiện trên văn bản p, sau đó sử dụng các điều kiện mạnh hơn - hình ảnh và văn bản kết quả - để tạo video v. Để hạn chế Model F với một hình ảnh, họ tạm thời tập trung vào hình ảnh và kết nối nó với mặt nạ nhị phân cho biết khung hình nào bằng không, cũng như đầu vào nhiễu. *
Vì bộ dữ liệu văn bản video nhỏ hơn nhiều so với bộ dữ liệu văn bản hình ảnh, các nhà nghiên cứu cũng khởi tạo mô hình chuyển văn bản thành video của họ bằng mô hình hình ảnh văn bản được đào tạo trước (T2I) được đông lạnh trọng lượng. Họ đã xác định các quyết định thiết kế quan trọng — thay đổi lịch trình tiếng ồn khuếch tán và đào tạo nhiều giai đoạn — để trực tiếp sản xuất video độ phân giải cao 512px.
Không giống như phương pháp tạo video trực tiếp từ văn bản, phương pháp phân tách của chúng tạo ra hình ảnh rõ ràng khi suy luận, cho phép chúng dễ dàng duy trì sự đa dạng hình ảnh, phong cách và chất lượng của mô hình sơ đồ Wensheng (như trong Hình 1). ĐIỀU NÀY CHO PHÉP VIDEO EMU HOẠT ĐỘNG TỐT HƠN CÁC PHƯƠNG PHÁP T2V TRỰC TIẾP NGAY CẢ VỚI CÙNG DỮ LIỆU ĐÀO TẠO, LƯỢNG TÍNH TOÁN VÀ CÁC THÔNG SỐ CÓ THỂ ĐÀO TẠO.

 Nghiên cứu này cho thấy chất lượng tạo video Wensheng có thể được cải thiện rất nhiều thông qua phương pháp đào tạo nhiều giai đoạn. Phương pháp này hỗ trợ tạo trực tiếp video độ phân giải cao ở 512px mà không cần một số mô hình tầng sâu được sử dụng trong phương pháp trước.
Nghiên cứu này cho thấy chất lượng tạo video Wensheng có thể được cải thiện rất nhiều thông qua phương pháp đào tạo nhiều giai đoạn. Phương pháp này hỗ trợ tạo trực tiếp video độ phân giải cao ở 512px mà không cần một số mô hình tầng sâu được sử dụng trong phương pháp trước.

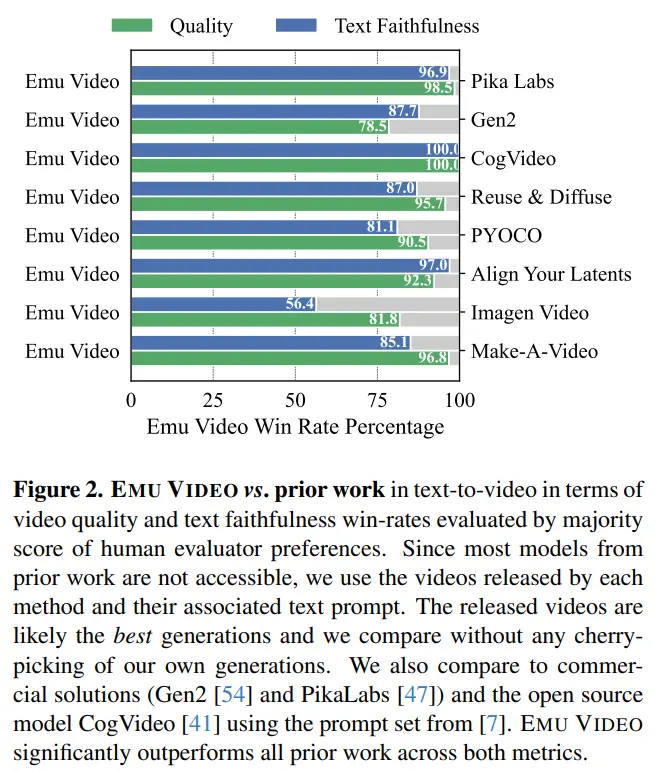
 Các nhà nghiên cứu đã nghĩ ra một giao thức đánh giá mạnh mẽ của con người, JUICE, trong đó các nhà đánh giá được yêu cầu chứng minh rằng lựa chọn của họ là chính xác khi đưa ra lựa chọn giữa các cặp. Như thể hiện trong Hình 2, tỷ lệ thắng trung bình của EMU VIDEO là 91,8% và 86,6% về chất lượng và độ trung thực của văn bản vượt xa tất cả các công việc trả trước bao gồm các giải pháp thương mại như Pika, Gen-2 và các giải pháp khác. NGOÀI T2V, VIDEO EMU CŨNG CÓ THỂ ĐƯỢC SỬ DỤNG ĐỂ TẠO HÌNH ẢNH THÀNH VIDEO, TRONG ĐÓ MÔ HÌNH TẠO VIDEO DỰA TRÊN HÌNH ẢNH VÀ LỜI NHẮC VĂN BẢN DO NGƯỜI DÙNG CUNG CẤP. Trong trường hợp này, kết quả tạo của EMU VIDEO tốt hơn 96% so với VideoComposer.
Các nhà nghiên cứu đã nghĩ ra một giao thức đánh giá mạnh mẽ của con người, JUICE, trong đó các nhà đánh giá được yêu cầu chứng minh rằng lựa chọn của họ là chính xác khi đưa ra lựa chọn giữa các cặp. Như thể hiện trong Hình 2, tỷ lệ thắng trung bình của EMU VIDEO là 91,8% và 86,6% về chất lượng và độ trung thực của văn bản vượt xa tất cả các công việc trả trước bao gồm các giải pháp thương mại như Pika, Gen-2 và các giải pháp khác. NGOÀI T2V, VIDEO EMU CŨNG CÓ THỂ ĐƯỢC SỬ DỤNG ĐỂ TẠO HÌNH ẢNH THÀNH VIDEO, TRONG ĐÓ MÔ HÌNH TẠO VIDEO DỰA TRÊN HÌNH ẢNH VÀ LỜI NHẮC VĂN BẢN DO NGƯỜI DÙNG CUNG CẤP. Trong trường hợp này, kết quả tạo của EMU VIDEO tốt hơn 96% so với VideoComposer.
 Như bạn có thể thấy từ bản demo được hiển thị, EMU VIDEO đã có thể hỗ trợ tạo video 4 giây. Trong bài báo, họ cũng khám phá các cách để tăng thời lượng của video. Với một sửa đổi kiến trúc nhỏ, các tác giả cho biết họ có thể hạn chế mô hình trên khung chữ T và mở rộng video. VÌ VẬY, HỌ ĐÃ ĐÀO TẠO MỘT BIẾN THỂ CỦA VIDEO EMU ĐỂ TẠO RA 16 KHUNG HÌNH TIẾP THEO VỚI ĐIỀU KIỆN “QUÁ KHỨ” 16 KHUNG HÌNH. Khi mở rộng video, họ sử dụng lời nhắc văn bản trong tương lai khác với video gốc, như thể hiện trong Hình 7. Họ phát hiện ra rằng video mở rộng tuân theo cả video gốc và lời nhắc văn bản trong tương lai.
Như bạn có thể thấy từ bản demo được hiển thị, EMU VIDEO đã có thể hỗ trợ tạo video 4 giây. Trong bài báo, họ cũng khám phá các cách để tăng thời lượng của video. Với một sửa đổi kiến trúc nhỏ, các tác giả cho biết họ có thể hạn chế mô hình trên khung chữ T và mở rộng video. VÌ VẬY, HỌ ĐÃ ĐÀO TẠO MỘT BIẾN THỂ CỦA VIDEO EMU ĐỂ TẠO RA 16 KHUNG HÌNH TIẾP THEO VỚI ĐIỀU KIỆN “QUÁ KHỨ” 16 KHUNG HÌNH. Khi mở rộng video, họ sử dụng lời nhắc văn bản trong tương lai khác với video gốc, như thể hiện trong Hình 7. Họ phát hiện ra rằng video mở rộng tuân theo cả video gốc và lời nhắc văn bản trong tương lai.
 **Emu Edit: Chỉnh sửa hình ảnh chính xác **
**Emu Edit: Chỉnh sửa hình ảnh chính xác **
Hàng triệu người sử dụng chỉnh sửa hình ảnh mỗi ngày. Tuy nhiên, các công cụ chỉnh sửa hình ảnh phổ biến đòi hỏi chuyên môn đáng kể và tốn thời gian sử dụng hoặc rất hạn chế và chỉ cung cấp một tập hợp các thao tác chỉnh sửa được xác định trước, chẳng hạn như các bộ lọc cụ thể. Ở giai đoạn này, chỉnh sửa hình ảnh dựa trên hướng dẫn cố gắng khiến người dùng sử dụng các hướng dẫn ngôn ngữ tự nhiên để khắc phục những hạn chế này. Ví dụ: người dùng có thể cung cấp hình ảnh cho người mẫu và hướng dẫn người mẫu “mặc trang phục lính cứu hỏa” (xem Hình 1).
 Tuy nhiên, trong khi các mô hình chỉnh sửa hình ảnh dựa trên hướng dẫn như InstructPix2Pix có thể được sử dụng để xử lý nhiều hướng dẫn nhất định, chúng thường khó diễn giải và thực hiện các hướng dẫn một cách chính xác. Ngoài ra, các mô hình này có khả năng khái quát hóa hạn chế và thường không thể thực hiện các nhiệm vụ hơi khác so với những gì chúng được đào tạo (xem Hình 3), chẳng hạn như cho thỏ con thổi kèn màu cầu vồng và các mô hình khác nhuộm màu cầu vồng thỏ hoặc trực tiếp tạo ra kèn màu cầu vồng.
Tuy nhiên, trong khi các mô hình chỉnh sửa hình ảnh dựa trên hướng dẫn như InstructPix2Pix có thể được sử dụng để xử lý nhiều hướng dẫn nhất định, chúng thường khó diễn giải và thực hiện các hướng dẫn một cách chính xác. Ngoài ra, các mô hình này có khả năng khái quát hóa hạn chế và thường không thể thực hiện các nhiệm vụ hơi khác so với những gì chúng được đào tạo (xem Hình 3), chẳng hạn như cho thỏ con thổi kèn màu cầu vồng và các mô hình khác nhuộm màu cầu vồng thỏ hoặc trực tiếp tạo ra kèn màu cầu vồng.
 Để giải quyết những vấn đề này, Meta đã giới thiệu Emu Edit, mô hình chỉnh sửa hình ảnh đầu tiên được đào tạo trên một loạt các tác vụ rộng và đa dạng, có thể thực hiện các chỉnh sửa dạng tự do dựa trên các lệnh, bao gồm chỉnh sửa cục bộ và toàn cầu, xóa và thêm nền, thay đổi màu sắc và biến đổi hình học, phát hiện và phân đoạn.
Để giải quyết những vấn đề này, Meta đã giới thiệu Emu Edit, mô hình chỉnh sửa hình ảnh đầu tiên được đào tạo trên một loạt các tác vụ rộng và đa dạng, có thể thực hiện các chỉnh sửa dạng tự do dựa trên các lệnh, bao gồm chỉnh sửa cục bộ và toàn cầu, xóa và thêm nền, thay đổi màu sắc và biến đổi hình học, phát hiện và phân đoạn.
 Địa chỉ:
Địa chỉ:
Địa chỉ dự án:
Không giống như nhiều mô hình AI tạo ra ngày nay, Emu Edit có thể làm theo hướng dẫn chính xác, đảm bảo rằng các pixel không liên quan trong hình ảnh đầu vào vẫn còn nguyên vẹn. Ví dụ: nếu người dùng đưa ra lệnh “loại bỏ con trên cỏ”, hình ảnh sau khi loại bỏ đối tượng hầu như không đáng chú ý.
 Xóa văn bản ở góc dưới cùng bên trái của hình ảnh và thay đổi nền của hình ảnh cũng sẽ được Emu Edit xử lý:
Xóa văn bản ở góc dưới cùng bên trái của hình ảnh và thay đổi nền của hình ảnh cũng sẽ được Emu Edit xử lý:
 Để đào tạo mô hình này, Meta đã phát triển một bộ dữ liệu gồm 10 triệu mẫu tổng hợp, mỗi mẫu chứa một hình ảnh đầu vào, mô tả về nhiệm vụ sẽ được thực hiện và hình ảnh đầu ra mục tiêu. Kết quả là, Emu Edit cho thấy kết quả chỉnh sửa chưa từng có về độ trung thực của lệnh và chất lượng hình ảnh.
Để đào tạo mô hình này, Meta đã phát triển một bộ dữ liệu gồm 10 triệu mẫu tổng hợp, mỗi mẫu chứa một hình ảnh đầu vào, mô tả về nhiệm vụ sẽ được thực hiện và hình ảnh đầu ra mục tiêu. Kết quả là, Emu Edit cho thấy kết quả chỉnh sửa chưa từng có về độ trung thực của lệnh và chất lượng hình ảnh.
Ở cấp độ phương pháp luận, các mô hình được đào tạo Meta có thể thực hiện mười sáu tác vụ chỉnh sửa hình ảnh khác nhau, bao gồm chỉnh sửa dựa trên khu vực, chỉnh sửa dạng tự do và các tác vụ thị giác máy tính, tất cả đều được xây dựng dưới dạng nhiệm vụ tạo và Meta cũng đã phát triển một quy trình quản lý dữ liệu duy nhất cho từng tác vụ. Meta nhận thấy rằng khi số lượng nhiệm vụ đào tạo tăng lên, hiệu suất của Emu Edit cũng tăng theo.
Thứ hai, để xử lý hiệu quả nhiều tác vụ khác nhau, Meta đã đưa ra khái niệm nhúng tác vụ đã học, được sử dụng để hướng dẫn quá trình tạo đi đúng hướng của nhiệm vụ xây dựng. Cụ thể, đối với mỗi tác vụ, bài viết này tìm hiểu một vector nhúng nhiệm vụ duy nhất và tích hợp nó vào mô hình thông qua tương tác chú ý chéo và thêm nó vào nhúng bước thời gian. Kết quả cho thấy việc nhúng tác vụ học tập giúp tăng cường đáng kể khả năng suy luận chính xác của mô hình từ các hướng dẫn dạng tự do và thực hiện các chỉnh sửa chính xác.
Vào tháng 4 năm nay, Meta đã ra mắt mô hình AI “Split Everything” và hiệu quả đáng kinh ngạc đến mức nhiều người bắt đầu tự hỏi liệu lĩnh vực CV có còn tồn tại hay không. Chỉ trong vài tháng, Meta đã ra mắt Emu Video và Emu Edit trong lĩnh vực hình ảnh và video, và chúng ta chỉ có thể nói rằng lĩnh vực AI tạo ra thực sự quá biến động.