HKU-Alibaba の「Visual AI Any Door」は、ワンクリックでオブジェクトをシーンにシームレスに送信できます
巴比特_
出典: 量子ビット
マウスを 2 回クリックするだけで、オブジェクトを写真シーンにシームレスに「送信」でき、光の角度や遠近感も自動的に調整できます。
AliとHKUのAI版「Any Gate」はゼロサンプル画像埋め込みを実現。
これにより、オンラインショッピングの服も上半身の効果を直接確認できるようになります。

AnyDoor は、一度に複数のオブジェクトをテレポートできます。



サンプル生成ゼロのリアルな効果
既存の同様のモデルと比較して、AnyDoor はゼロサンプル操作の機能を備えており、特定の項目に合わせてモデルを調整する必要がありません。

実際、他の Reference クラス モデルは意味的な一貫性を維持することしかできません。
平たく言えば、送信対象が猫の場合、他のモデルでは結果に猫も含まれていることを保証することしかできませんが、類似性は保証できません。



既存の画像内のオブジェクトの移動、置換、さらには姿勢の変更についても、AnyDoor は優れたパフォーマンスを発揮します。

動作原理
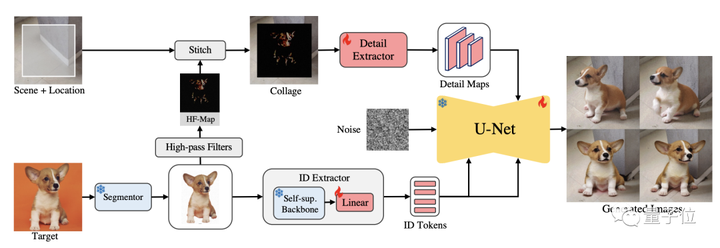
ただし、ターゲット オブジェクトを含む画像をエクストラクターに供給する前に、AnyDoor はまず背景の除去を実行します。
次に、AnyDoor は自己監視型オブジェクトの抽出を実行し、それをトークンに変換します。
このステップで使用されるエンコーダーは、現在の最良の自己教師ありモデル DINO-V2 に基づいて設計されています。
角度や光の変化に適応するには、アイテムの全体的な特徴を抽出することに加えて、追加の詳細情報を抽出する必要があります。
このステップでは、過度の制約を避けるために、チームは高頻度マップで地物情報を表現する方法を設計しました。

同時に、AnyDoor はアダマールを使用して画像内の RGB カラー情報を抽出します。
この情報をエッジ情報をフィルタリングするマスクと組み合わせると、高周波の詳細のみを含む HF マップが生成されます。

AnyDoor は、取得したトークンを使用して、ヴィンセン グラフ モデルを通じて画像を合成します。
具体的には、AnyDoor は ControlNet で Stable Diffusion を使用します。
AnyDoorのワークフローは大まかにこんな感じです。トレーニングに関しては、特別な戦略もいくつかあります。
AnyDoor は静止画を対象としていますが、学習に使用するデータの一部は動画からも抽出されます。
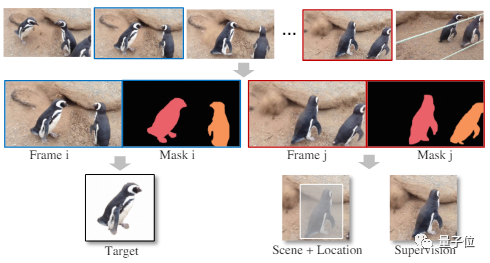
AnyDoor のトレーニング データは、オブジェクトを背景から分離し、そのペアをマークすることによって形成されます。
しかし、ビデオ データは学習には適していますが、解決する必要がある品質の問題もあります。
そこでチームは、さまざまな時点で変更情報と詳細情報を収集するための適応型タイムステップ サンプリング戦略を設計しました。
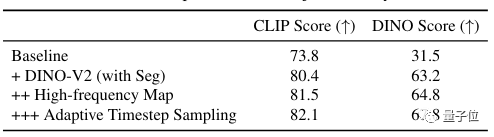
アブレーション実験の結果から、これらの戦略を追加すると、CLIP スコアと DINO スコアの両方が徐々に増加したことがわかります。
チームプロフィール
この論文の筆頭著者は、アリババグループのアルゴリズムエンジニアだった香港大学の博士課程学生、シー・チェン氏です。
Chen Xi の指導教員である Hengshuang Zhao はこの記事の責任著者であり、彼の研究分野にはマシン ビジョンと機械学習が含まれます。
さらに、Alibaba DAMO Academy と Cainiao Group の研究者もこのプロジェクトに参加しました。
用紙のアドレス:
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし