Sumber: Qubit
Dengan dua klik mouse, objek dapat “ditransmisikan” dengan mulus ke pemandangan foto, dan sudut cahaya serta perspektif juga dapat diadaptasi secara otomatis.
Versi AI Ali dan HKU dari “Any Gate” mewujudkan penyematan gambar tanpa sampel.
Dengannya, belanja baju online juga bisa langsung melihat efek tubuh bagian atas.
 Karena fungsinya sangat mirip dengan pintu manapun, maka tim R&D menamakannya AnyDoor.
Karena fungsinya sangat mirip dengan pintu manapun, maka tim R&D menamakannya AnyDoor.
AnyDoor dapat memindahkan banyak objek sekaligus.
 Tidak hanya itu, ia juga dapat memindahkan objek yang ada pada gambar.
Tidak hanya itu, ia juga dapat memindahkan objek yang ada pada gambar.
 Beberapa netizen kagum setelah menontonnya, mungkin selanjutnya akan berkembang menjadi (melewati objek menjadi) video.
Beberapa netizen kagum setelah menontonnya, mungkin selanjutnya akan berkembang menjadi (melewati objek menjadi) video.

Efek realistis pembuatan sampel nol
Dibandingkan dengan model serupa yang ada, AnyDoor memiliki kemampuan operasi sampel nol, dan tidak perlu menyesuaikan model untuk item tertentu.
 Selain model-model tersebut yang memerlukan penyesuaian parameter, AnyDoor juga lebih akurat dibandingkan model Referensi lainnya.
Selain model-model tersebut yang memerlukan penyesuaian parameter, AnyDoor juga lebih akurat dibandingkan model Referensi lainnya.
Faktanya, model kelas Referensi lainnya hanya dapat mempertahankan konsistensi semantik.
Dalam istilah awam, jika objek yang akan ditransmisikan adalah kucing, model lain hanya dapat menjamin bahwa hasilnya juga ada kucing, tetapi kesamaannya tidak dapat dijamin.
 Kami mungkin juga memperbesar efek AnyDoor, tidak bisakah kami melihat kekurangannya?
Kami mungkin juga memperbesar efek AnyDoor, tidak bisakah kami melihat kekurangannya?

 Hasil ulasan pengguna juga mengonfirmasi bahwa AnyDoor mengungguli model yang ada baik dalam kualitas maupun akurasi (dari 4 poin).
Hasil ulasan pengguna juga mengonfirmasi bahwa AnyDoor mengungguli model yang ada baik dalam kualitas maupun akurasi (dari 4 poin).
Untuk pergerakan, transposisi, bahkan perubahan postur objek pada gambar yang ada, AnyDoor juga dapat bekerja dengan baik.
 Jadi, bagaimana AnyDoor mencapai fungsi-fungsi ini?
Jadi, bagaimana AnyDoor mencapai fungsi-fungsi ini?
prinsip bekerja
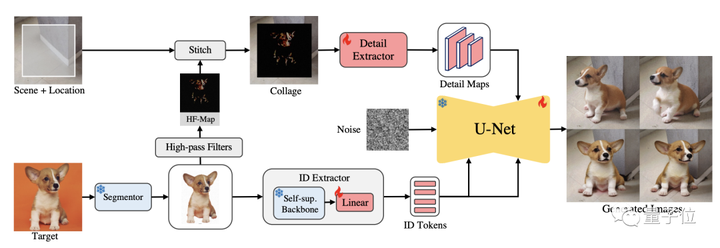 Untuk mewujudkan transmisi suatu objek, objek tersebut harus diekstraksi terlebih dahulu.
Untuk mewujudkan transmisi suatu objek, objek tersebut harus diekstraksi terlebih dahulu.
Namun, sebelum memasukkan gambar yang berisi objek target ke ekstraktor, AnyDoor terlebih dahulu melakukan penghapusan latar belakang di atasnya.
Kemudian, AnyDoor akan melakukan ekstraksi objek yang diawasi sendiri dan mengubahnya menjadi token.
Encoder yang digunakan dalam langkah ini dirancang berdasarkan model DINO-V2 swakelola terbaik saat ini.
Untuk beradaptasi dengan perubahan sudut dan cahaya, selain mengekstraksi fitur keseluruhan item, informasi detail tambahan perlu diekstrak.
Pada langkah ini, untuk menghindari kendala yang berlebihan, tim merancang cara untuk merepresentasikan informasi fitur dengan peta frekuensi tinggi.
 Dengan menggabungkan gambar target dengan filter high-pass seperti operator Sobel, gambar dengan detail frekuensi tinggi dapat diperoleh.
Dengan menggabungkan gambar target dengan filter high-pass seperti operator Sobel, gambar dengan detail frekuensi tinggi dapat diperoleh.
Pada saat yang sama, AnyDoor menggunakan Hadamard untuk mengekstrak informasi warna RGB pada gambar.
Menggabungkan informasi ini dengan topeng yang memfilter informasi tepi menghasilkan HF-Map yang hanya berisi detail frekuensi tinggi.
 Langkah terakhir adalah menyuntikkan informasi ini.
Langkah terakhir adalah menyuntikkan informasi ini.
Menggunakan token yang diperoleh, AnyDoor mensintesis gambar melalui model grafik Vinsen.
Secara khusus, AnyDoor menggunakan Difusi Stabil dengan ControlNet.
Alur kerja AnyDoor kira-kira seperti ini. Dalam hal pelatihan, ada juga beberapa strategi khusus.
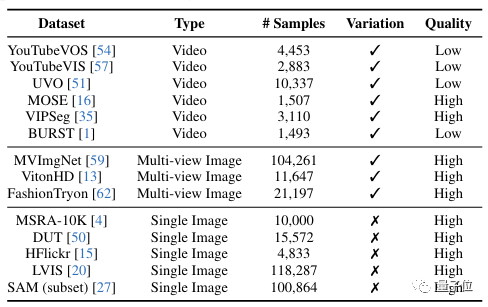 ###### △ Kumpulan data pelatihan yang digunakan oleh AnyDoor
###### △ Kumpulan data pelatihan yang digunakan oleh AnyDoor
Meskipun AnyDoor menargetkan gambar diam, sebagian data yang digunakan untuk pelatihan diambil dari video.
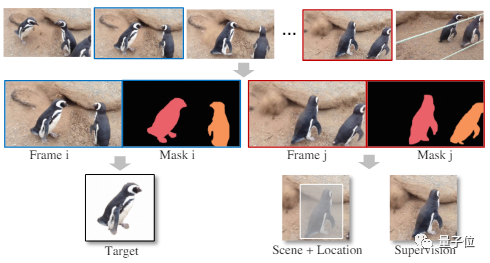 Untuk objek yang sama, gambar yang mengandung latar belakang berbeda dapat diekstraksi dari video.
Untuk objek yang sama, gambar yang mengandung latar belakang berbeda dapat diekstraksi dari video.
Data pelatihan AnyDoor dibentuk dengan memisahkan objek dari latar belakang dan menandai pasangannya.
Namun, meskipun data video bagus untuk pembelajaran, ada masalah kualitas yang perlu ditangani.
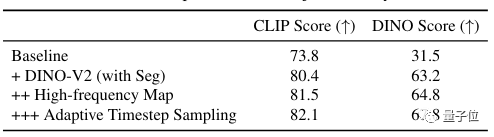
Jadi, tim merancang strategi pengambilan sampel langkah waktu yang adaptif untuk mengumpulkan informasi perubahan dan detail pada waktu yang berbeda.
Dari hasil percobaan ablasi terlihat bahwa dengan penambahan strategi tersebut, baik skor CLIP maupun DINO berangsur-angsur meningkat.
Profil Tim
Penulis pertama makalah ini adalah Xi Chen, seorang mahasiswa doktoral di Universitas Hong Kong, yang pernah menjadi insinyur algoritme di Alibaba Group.
Penyelia Chen Xi, Hengshuang Zhao, adalah penulis korespondensi makalah ini Bidang penelitiannya meliputi visi mesin dan pembelajaran mesin.
Selain itu, peneliti dari Alibaba DAMO Academy dan Cainiao Group juga berpartisipasi dalam proyek ini.
Alamat kertas:
