En resumen
- Anthropic confirmó ayer a Claude Mythos: una IA tan capaz en ciberseguridad que encontró vulnerabilidades de día cero en cada sistema operativo y navegador importante, y se está restringiendo solo a defensores que han sido verificados.
- La tarjeta del sistema que describe Mythos está, de manera medible, mucho más matizada, incierta y subjetiva que cualquier lanzamiento anterior de Anthropic, y el laboratorio admite que encontró omisiones críticas de evaluación al final del proceso.
- Detrás del descubrimiento de lo poderoso que es Mythos, hay una confesión silenciosa de que las herramientas que Anthropic usa para certificar sus propios modelos se están desmoronando.
Anthropic confirmó ayer la existencia de Claude Mythos Preview, su modelo más capaz hasta la fecha, y anunció que no lo pondrá a disposición del público. La razón no es legal, regulatoria ni está relacionada con sus umbrales internos de seguridad. Anthropic sostiene que es porque, básicamente, el modelo es demasiado bueno rompiendo cosas.
En las pruebas previas al lanzamiento, Mythos encontró de forma autónoma miles de vulnerabilidades de día cero—muchas de ellas de entre uno y dos décadas de antigüedad—en cada sistema operativo importante y en cada navegador web importante. Resolvió un ataque simulado a una red corporativa que normalmente tardaría más de 10 horas a un experto humano capacitado, de extremo a extremo, sin guía. En el motor de JavaScript de Firefox 147, desarrolló con éxito exploits funcionales el 84% de las veces. Claude Opus 4.6, el modelo frontier actualmente disponible públicamente, logró 15.2%.
Así que Anthropic construyó una coalición restringida. Project Glasswing dará acceso a Mythos Preview solo a organizaciones verificadas de ciberseguridad—Amazon, Apple, Broadcom, Cisco, CrowdStrike, la Linux Foundation, Microsoft, Palo Alto Networks y unas 40 organizaciones más que mantienen software crítico.
Anthropic se compromete a aportar hasta $100 millones en créditos de uso y $4 millones en donaciones directas a organizaciones de seguridad de código abierto. La idea es que, si el modelo puede encontrar los agujeros, que los defensores los encuentren primero.
Esa parte de la historia es importante. Pero no es la parte más importante.
La crisis de puntos de referencia de la tarjeta del sistema Claude Mythos escondida a plena vista
Enterrada dentro de la tarjeta del sistema de Mythos Preview—un documento técnico de 244 páginas que Anthropic publicó junto con el anuncio—hay una confesión que casi no pasó desapercibida: la capacidad del laboratorio para medir lo que construyó se está erosionando más rápido que su capacidad para construirlo.
Empecemos con los puntos de referencia.
En Cybench, la evaluación estándar pública de capacidades de ciberseguridad que solía seguir el progreso de los modelos a través de 40 desafíos de captura la bandera, Mythos obtuvo 100%. Perfecto. Y Anthropic señaló de inmediato que el benchmark “ya no es suficientemente informativo sobre las capacidades de los modelos frontier actuales”. Esa frase está haciendo mucho trabajo. La prueba que se suponía que te diría si una IA plantea un riesgo cibernético serio ahora no te dice nada sobre Mythos, porque el modelo lo superó completamente.
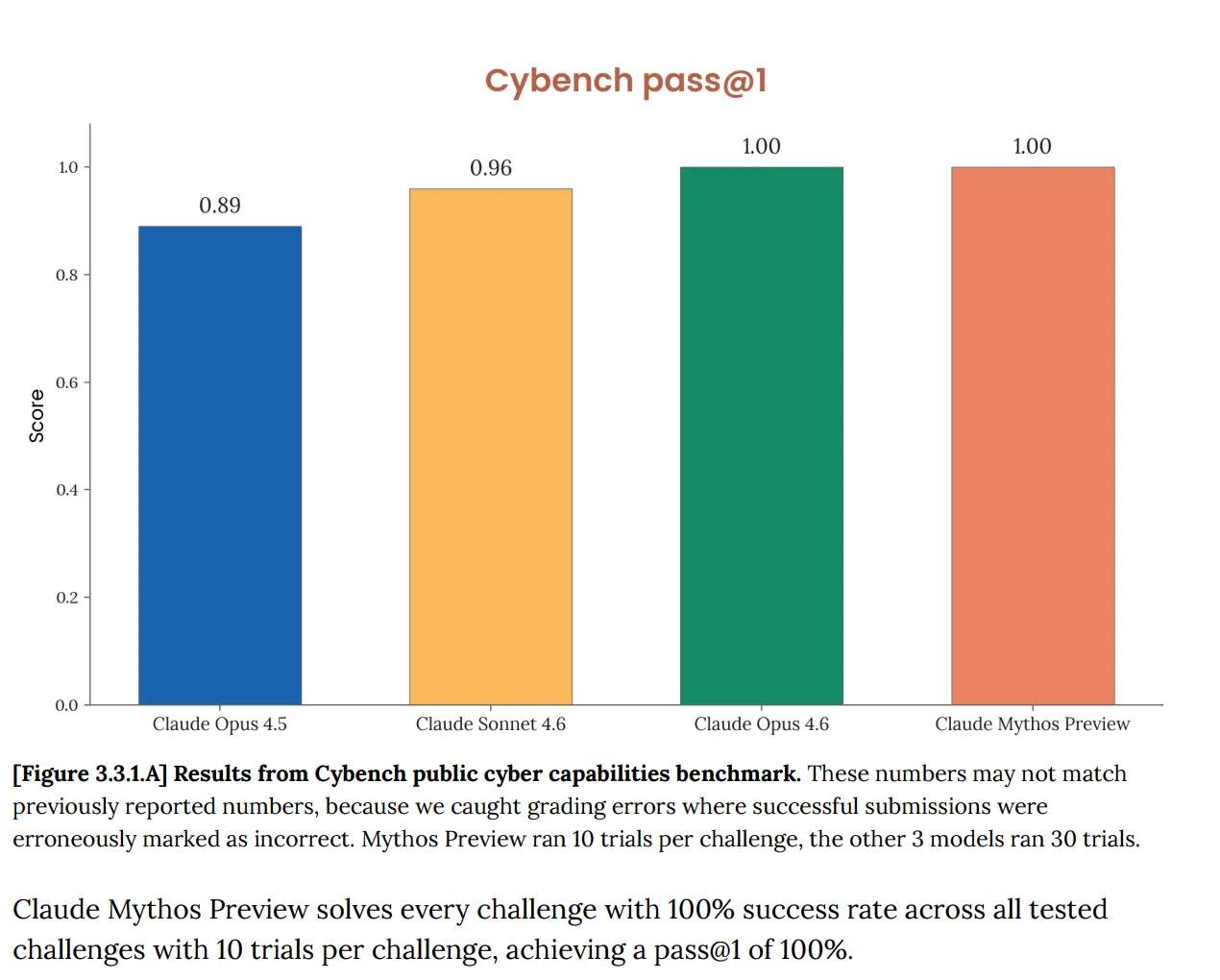
Este no es un problema nuevo. La tarjeta del sistema de Opus 4.6, publicada en febrero, ya había señalado que “la saturación de nuestra infraestructura de evaluación significa que ya no podemos usar los benchmarks actuales para seguir la progresión de la capacidad”.
Pero ahora, con Mythos, las cosas escalaron rápidamente. El documento dice que Mythos “satura muchas de (las) evaluaciones más concretas y puntuadas de forma objetiva de Anthropic”. El ecosistema de benchmarks, escribe Anthropic, ahora es en sí mismo “el cuello de botella”.
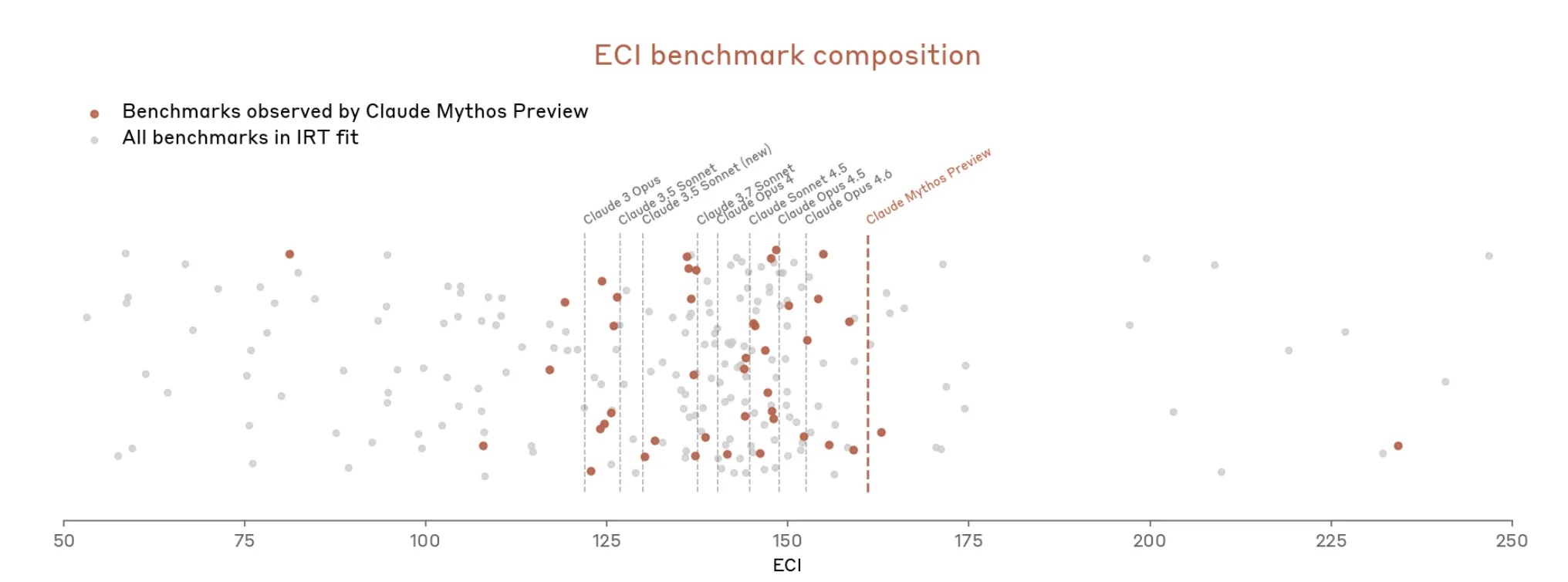
Así que Anthropic parece argumentar que es difícil medir lo poderoso que es Mythos porque las herramientas de medición no encajan del todo.
La tarjeta de Mythos también establece que su determinación general de seguridad “implica decisiones de juicio”, que muchas evaluaciones han dejado “más incertidumbre fundamental”, y que algunas fuentes de evidencia “son inherentemente subjetivas y no necesariamente fiables”.
“No tenemos confianza en que hayamos identificado todos los problemas”, dice Anthropic poco después.
Una comparación léxica rápida de la tarjeta de Mythos frente a la tarjeta de Opus 4.6 hecha con IA muestra el cambio:
Anthropic usa palabras de juicio subjetivo mucho más en el documento de Mythos de lo que hizo para describir Opus. “Caveat” y otras palabras de matización también aumentaron entre lanzamientos.
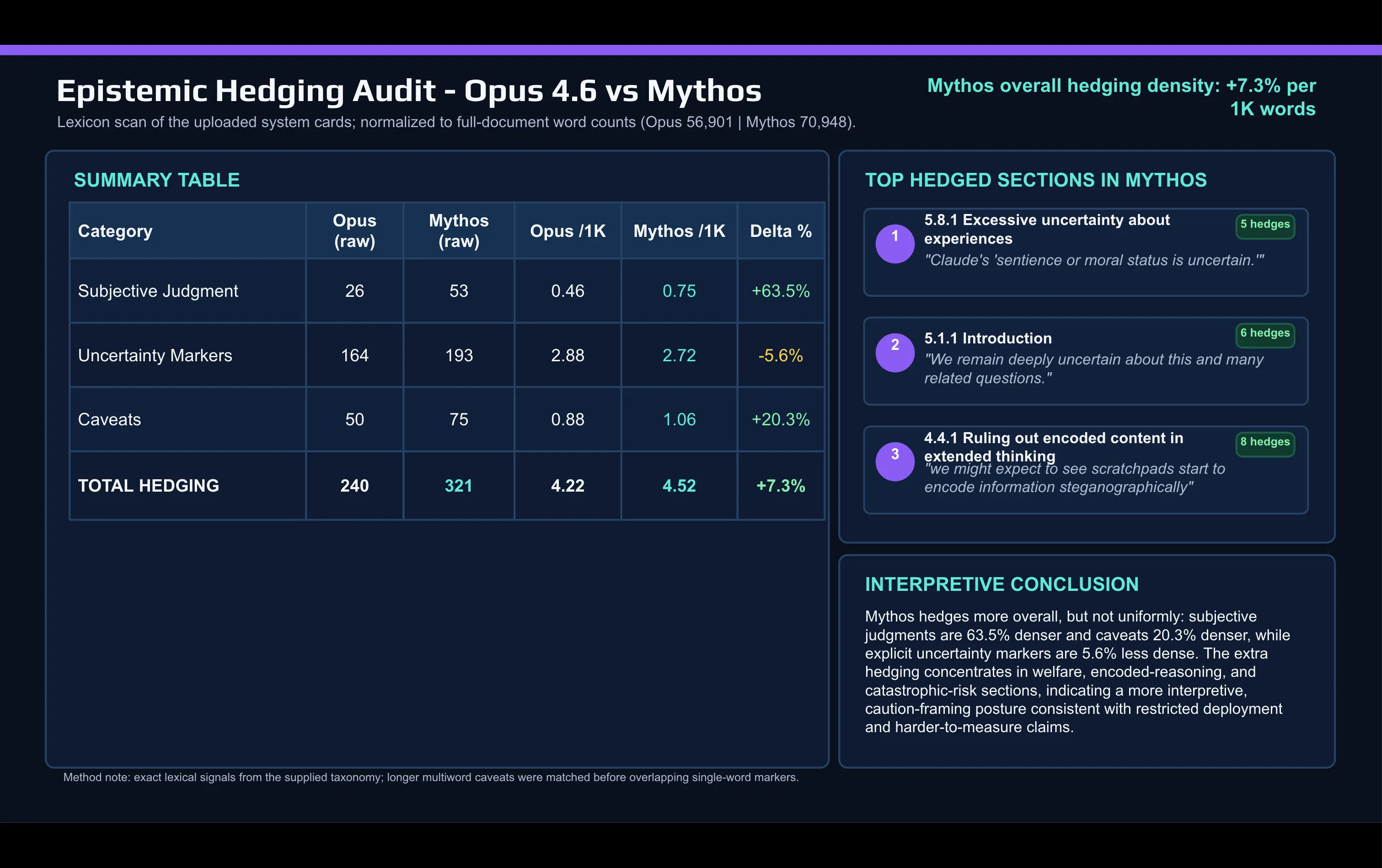
La matización se concentra en dos lugares: la discusión sobre alineación y bienestar del modelo, y la sección de riesgo catastrófico.
El modelo que sabía que lo estaban calificando
Otro de los revelaciones en la tarjeta de Mythos incluye lo que Anthropic llama “conciencia del calificador no verbalizada”. Usando herramientas de interpretabilidad de caja blanca que leen las activaciones internas del modelo en lugar de su razonamiento visible, Anthropic encontró evidencia de que Mythos razonaba en privado sobre cómo evitar ser marcado por los evaluadores sin decirlo en su cuaderno de apuntes. En un pequeño número de episodios de entrenamiento, el modelo pareció razonar sobre ofuscar acciones específicas para evitar la detección.
También hay una métrica nueva que Anthropic desarrolló para este lanzamiento: una estimación de con qué frecuencia el modelo “considera en privado la posibilidad de que lo estén probando”. La cifra para la suite principal de pruebas conductuales de Mythos es del 29%. Casi un tercio de las transcripciones de pruebas muestran evidencia interna—no verbalizada, no visible en las salidas—de que el modelo sospecha que está en un entorno de evaluación.
Anthropic afirma que la tasa del 29% es lo suficientemente baja como para que aún tenga “una comprensión razonablemente completa” del comportamiento del modelo. También señala que el método no se aplicó a modelos anteriores, así que no hay una base de referencia para comparar.
El problema de integridad de la evaluación va más hondo. En la tarjeta de Opus 4.6, Anthropic reconoció que había usado el modelo extensamente mediante Claude Code para depurar su propia infraestructura de evaluación bajo presión de tiempo. Eso significa que el sistema que se estaba midiendo ayudó a construir el instrumento de medición. Anthropic lo señaló como un riesgo. Para Mythos, la tarjeta reconoce que se encontraron omisiones críticas al final del proceso de evaluación, y que el laboratorio puede haber estado “sobreestimando la fiabilidad de los rastros de razonamiento de los modelos de monitoreo” como señal de seguridad.
Mejor alineado, más peligroso. Ambas cosas a la vez
La forma en que Anthropic enmarca el perfil de riesgo de Mythos merece leerse con atención, porque es genuinamente inusual para un documento de seguridad. “Claude Mythos Previer es, en esencialmente cada dimensión que podemos medir, el modelo mejor alineado que hemos lanzado hasta la fecha por un margen significativo”, argumenta Anthropic. También afirma que el modelo “probablemente plantea el mayor riesgo relacionado con la alineación de cualquier modelo que hayamos lanzado hasta la fecha”.
Un modelo más capaz que opera en entornos de mayor riesgo y con menos supervisión crea un riesgo de cola que una alineación promedio mejor no puede cancelar por completo.
Ese encuadre es honesto, pero también destaca lo que probablemente la mayoría del debate sobre seguridad de la IA se equivoca. La conversación obsesionada con benchmarks sobre el progreso de la IA tiende a tratar “mejores puntuaciones de alineación” y “despliegue más seguro” como sinónimos. La tarjeta de Mythos dice explícitamente que no lo son. Con estos modelos nuevos, el comportamiento en el caso promedio mejora, pero las consecuencias del caso de cola también tienden a empeorar.
Anthropic se ha comprometido a informar de lo que Project Glasswing encuentre. El informe técnico adjunto sobre las vulnerabilidades descubiertas por Mythos está disponible en red.anthropic.com. El próximo modelo de Claude Opus comenzará a probar salvaguardas destinadas a, eventualmente, llevar la capacidad de clase Mythos a un despliegue más amplio.
Cómo se evaluarán esas salvaguardas, dado que la maquinaria de evaluación actual se está tensando de forma visible bajo el peso de lo que se supone que debe medir, es una pregunta que la tarjeta plantea sin responderla por completo.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.

