谷歌凭借 Gemma 4 再次投身开源 AI 竞赛公开争夺
简而言之
- Google 推出 Gemma 4,这是一组在 Apache 2.0 许可证下的开源模型家族。
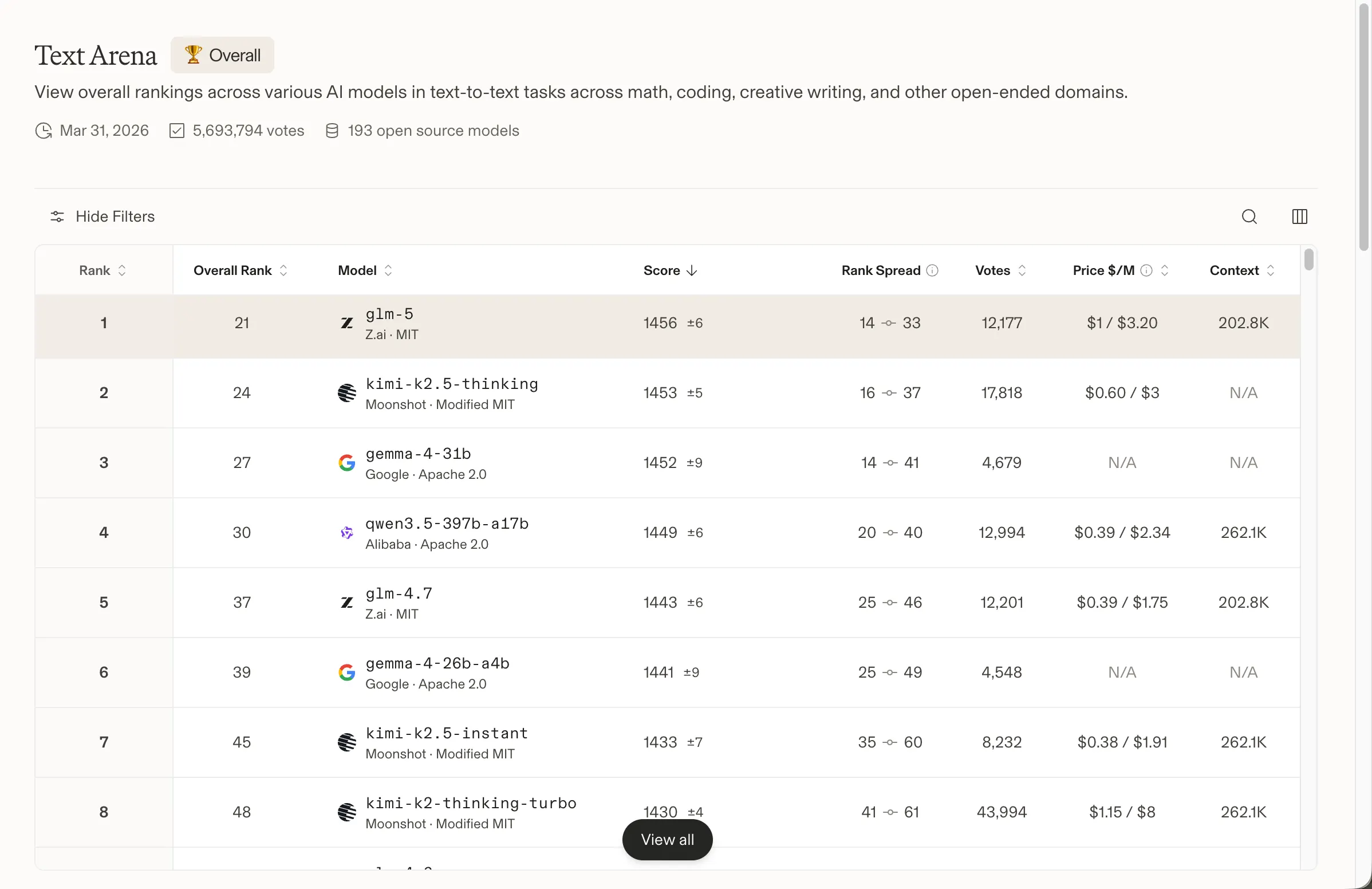
- 这套四模型阵容覆盖从手机到数据中心的场景,其中 31B 模型已在全球排名第 #3。
- 美国开源 AI 得到了一次急需的助推,因为由 DeepMind 背书的 Gemma 4 将自身定位为对抗 DeepSeek、Qwen 和其他中国头部团队的最强美国竞争者。
Google 的开源 AI 野心今天变得更认真了。该公司发布了 Gemma 4,这是一组四款开源权重模型,基于与 Gemini 3 相同的研究成果,并采用 Apache 2.0 许可——这与此前 Gemma 各版本中更为严格的条款形成了显著差异。 开发者过去已经下载了先前各代 Gemma 超过 4 亿次,催生了超过 10 万个社区变体。此次发布是迄今为止最雄心勃勃的一次。
我们刚刚发布了 Gemma 4——迄今为止我们最智能的开源模型。
基于与 Gemini 3 相同的世界级研究,Gemma 4 将突破性的智能直接带到你自己的硬件上,用于更高级的推理和具备行动能力的工作流。
在商业…… pic.twitter.com/W6Tvj9CuHW
— Google (@Google) 2026年4月2日
过去一年里,开源 AI 排行榜在很大程度上成了中国的事情。DeepSeek、Minimax、GLM 和 Qwen 主宰了榜单前列,让美国的替代方案在相关性上焦急寻找立足点。正如 Decrypt 去年报道的那样,中国开源模型在 2024 年底全球开源模型使用中仅约 1.2%,到 2025 年底已达到大约 30%;而阿里巴巴的 Qwen 甚至还超过了 Meta 的 Llama,成为全球使用最多的自托管模型。 Meta 的 Llama 过去是开发者寻找具备能力、且可在本地运行的模型时的默认选择。这个口碑正在衰退——Llama 由 Meta 控制的许可引发了关于其真正开源身份的疑问,并且其性能已落后于中国竞争对手。Allen Institute 的 OLMo 家族曾试图填补空白,但未能获得有意义的关注度。OpenAI 于 2025 年 8 月发布了它的 gpt-oss 模型,给生态系统带来了一口新鲜空气,但它们从未被设计为前沿竞争者。 而就在昨天,一家名为 Arcee AI 的美国创业公司(30 人团队)发布了 Trinity,这是一款拥有 4000 亿参数的开源模型,给人一个有说服力的理由:美国现场并没有完全死去。Gemma 4 延续了这种势头,这一次是由 Google DeepMind 全力加持,使其有望成为开源 AI 领域中“最好的美国模型”。
Google 在其公告中表示,该模型“基于与 Gemini 3 相同的世界级研究与技术”构建。Gemma 4 提供四种规格:用于手机和边缘设备的 Effective 2B 和 4B;面向速度的 26B Mixture of Experts(混合专家)模型;以及为原始质量优化的 31B Dense(稠密)模型。
31B Dense 目前在 Arena AI 的文本排行榜中位列所有开源模型的第三。26B MoE 排在第六。Google 声称两者都能击败规模是自身 20 倍的模型——这一说法至少在 Arena AI 的数据上站得住脚:尽管如此,中国模型仍占据前两名。
我们测试了 Gemma 4。它很有能力,但也有一些顾虑。模型即使在不需要推理的任务上也会进行推理,这可能会让对简单提示的回答显得过度工程化。创意写作还不错——可用但不算灵感爆发——并且可能在获得更具体的指导与提示工程后会进一步提升。 它最清晰的强项在代码上。被要求生成一款游戏时,输出并不特别炫目或精雕细琢,但它在第一次尝试时就能无报错地运行。对于一个 410 亿参数的模型来说,这并不差。那种零样本可靠性,或许比需要调试的“更漂亮结果”更有价值。 你可以在这里尝试这个(基础但可用的)游戏。
四种变体覆盖了完整的硬件光谱。E2B 和 E4B 模型面向 Android 手机、Raspberry Pi 以及边缘设备,完全可离线运行,接近零延迟,并提供原生音频输入,以及 128K 的上下文窗口。26B 和 31B 模型面向工作站和云端部署,将上下文扩展到 256K,并加入原生的函数调用以及用于构建自主代理的结构化 JSON 输出。四个模型都能原生处理图像和视频。更大模型的全精度权重可装进一张 80GB 的 NVIDIA H100 GPU 上;量化版本则可在消费级硬件上运行。 Apache 2.0 许可证是另一个重要卖点。Google 之前的 Gemma 发布使用的是自定义许可,该许可会在商业产品层面制造法律上的模糊性。Apache 2.0 则彻底消除了这种摩擦——开发者可以修改、重新分发并进行商业化,而不必担心 Google 之后会更改条款。Hugging Face 的联合创始人 Clement Delangue 称赞了这一点,他表示:“本地 AI 正在迎来它的时刻”,而这将是 AI 行业的未来。Google DeepMind CEO Demis Hassabis 则更进一步,称 Gemma 4 是“在各自尺寸上,世界上最好的开源模型”。
兴奋地发布 Gemma 4:在各自尺寸上,世界上最好的开源模型。提供 4 种规格,你可以针对你的具体任务进行微调:31B dense 用于出色的原始性能,26B MoE 用于低延迟,以及适用于边缘设备的 effective 2B & 4B——祝你构建顺利! pic.twitter.com/Sjbe3ph8xr
— Demis Hassabis (@demishassabis) 2026年4月2日
这是一个强有力的说法。来自 Anthropic、OpenAI 以及 Google 自己的 Gemini 的专有系统,仍在最艰难的基准测试中处于领先地位。但对于那些你能在本地运行、可以自由修改、并部署到你自有基础设施上的开源权重模型而言?竞争刚刚变得显著更薄了。你现在可以在 Google AI Studio(31B 和 26B)或 Google AI Edge Gallery(E2B 和 E4B)中试用 Gemma 4。模型权重也可在 Hugging Face、Kaggle 和 Ollama 上获取。