Em resumo
- A Anthropic confirmou ontem o Claude Mythos—um IA tão capaz em cibersegurança que encontrou zero-days em todos os principais sistemas operativos e navegadores, e está a ser restringido apenas a defensores devidamente verificados.
- O relatório do sistema que descreve o Mythos é, de forma mensurável, mais prudente, incerto e subjectivo do que qualquer lançamento anterior da Anthropic, e o laboratório admite que encontrou falhas críticas de avaliação no final do processo.
- Por detrás da revelação de quão poderoso é o Mythos, há uma confissão silenciosa de que as ferramentas que a Anthropic usa para certificar os seus próprios modelos estão a desmoronar-se.
A Anthropic confirmou a existência do Claude Mythos Preview ontem, o seu modelo mais capaz até à data, e anunciou que não o vai disponibilizar ao público. A razão não é legal, regulatória, nem relacionada com os seus limiares internos de segurança. A Anthropic argumenta que é porque o modelo é, basicamente, bom demais para se meter em coisas.
Em testes antes do lançamento, o Mythos encontrou autonomamente milhares de vulnerabilidades de zero-day—muitas delas com um a dois séculos de idade—em todos os principais sistemas operativos e em todos os principais navegadores web. Resolveu um ataque simulado a uma rede corporativa que normalmente demoraria mais de 10 horas para um especialista humano qualificado, ponta a ponta, sem orientação. No motor JavaScript do Firefox 147, desenvolveu com sucesso exploits funcionais 84% das vezes. O Claude Opus 4.6, o modelo de fronteira actualmente disponível ao público, conseguiu 15.2%.
Então a Anthropic construiu uma coligação restrita. O Project Glasswing vai dar acesso ao Mythos Preview apenas a organizações de cibersegurança verificadas—Amazon, Apple, Broadcom, Cisco, CrowdStrike, a Linux Foundation, Microsoft, Palo Alto Networks e cerca de 40 outros grupos que mantêm software crítico.
A Anthropic está a comprometer até $100 milhões em créditos de utilização e $4 milhões em doações directas a organizações de segurança de código aberto. A ideia é que, se o modelo consegue encontrar as falhas, então os defensores as encontrem primeiro.
Essa parte da história é importante. Mas não é a parte mais importante.
A crise de benchmark do relatório do sistema Claude Mythos escondida à vista de todos
Enterrado dentro do relatório do sistema do Mythos Preview—um documento técnico de 244 páginas que a Anthropic publicou em conjunto com o anúncio—há uma confissão que passou quase despercebida: a capacidade do laboratório de medir o que construiu está a deteriorar-se mais depressa do que a sua capacidade de o construir.
Vamos começar pelos benchmarks.
No Cybench, a avaliação pública padrão de capacidades de cibersegurança usada para acompanhar o progresso dos modelos ao longo de 40 desafios do tipo capture-the-flag, o Mythos obteve 100%. Perfeito. E a Anthropic notou imediatamente que o benchmark “já não é suficientemente informativo das capacidades dos modelos de fronteira actuais”. Essa frase está a fazer muito trabalho. O teste que supostamente deveria dizer-lhe se uma IA representa um risco cibernético sério já não lhe diz nada sobre o Mythos, porque o modelo o ultrapassou completamente.
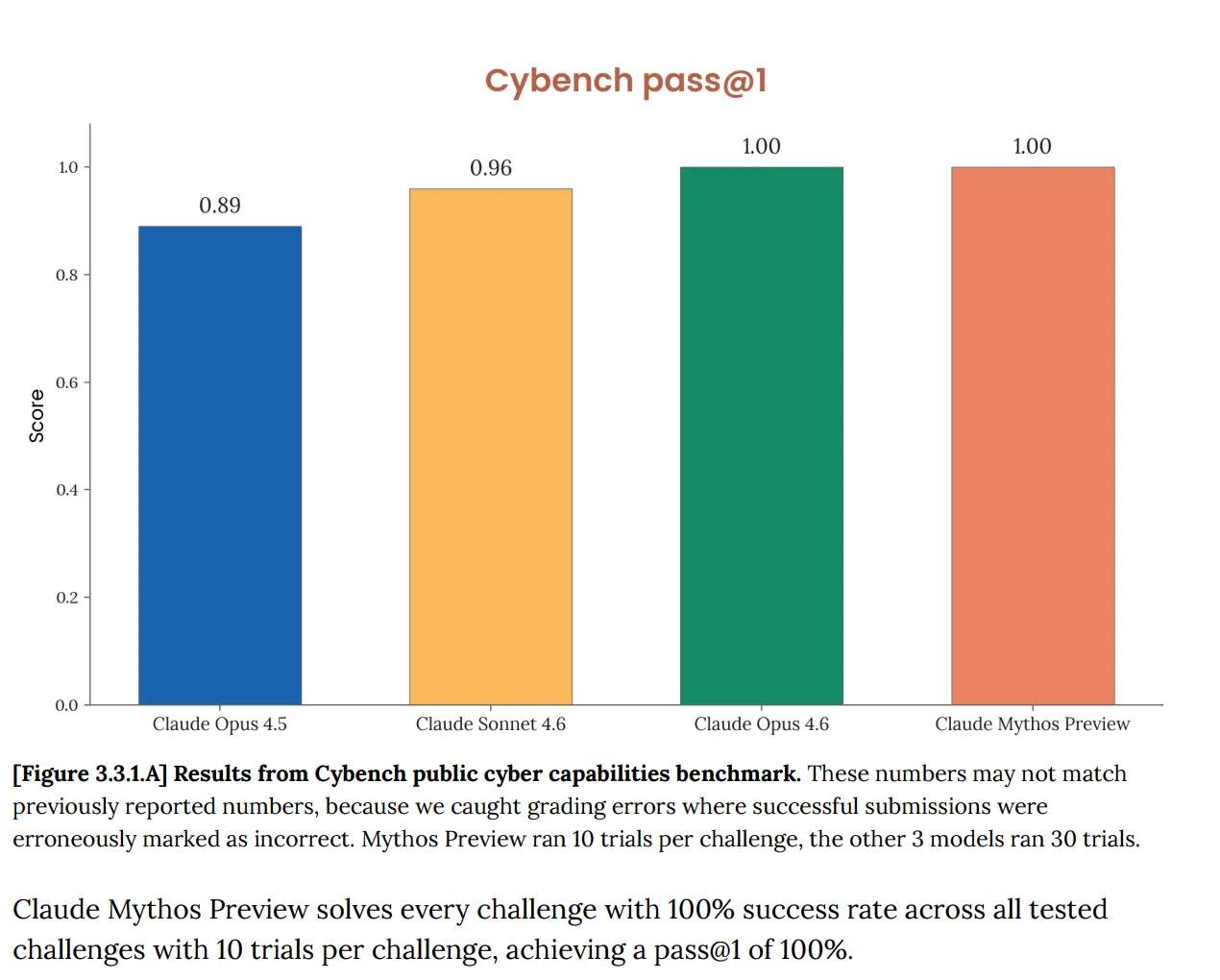
Este não é um problema novo. O relatório do sistema do Opus 4.6, publicado em Fevereiro, já tinha assinalado que “a saturação da nossa infra-estrutura de avaliação significa que já não podemos usar os benchmarks actuais para acompanhar a progressão de capacidades.”
Mas agora, com o Mythos, as coisas escalaram rapidamente. O documento diz que o Mythos “satura muitas das (avaliações mais concretas e objectivamente pontuadas da )Anthropic.” O ecossistema de benchmark, escreve a Anthropic, é agora ele próprio “o gargalo”.
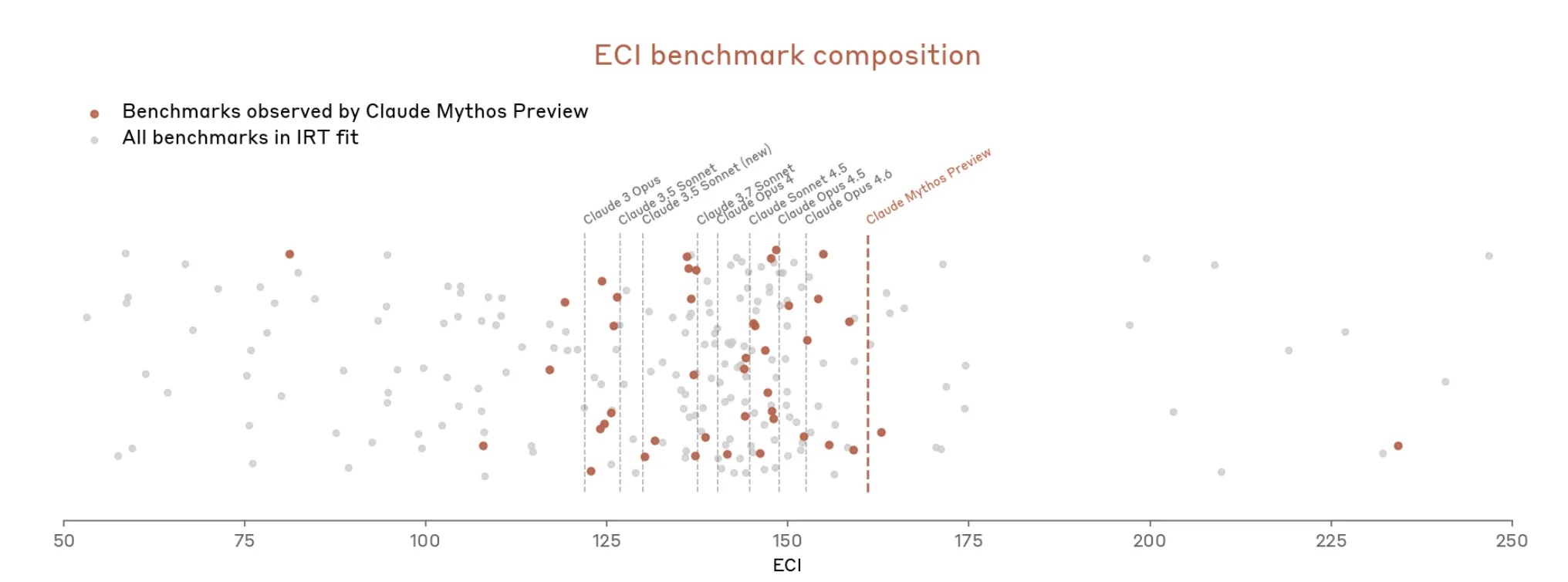
Assim, a Anthropic parece argumentar que é difícil medir o quão poderoso é o Mythos porque as ferramentas de medição não se encaixam exactamente.
O relatório do Mythos também afirma que a sua determinação global de segurança “envolve decisões de julgamento”, que muitas avaliações deixaram “mais incerteza fundamental”, e que algumas fontes de evidência são “inerentemente subjectivas, e não necessariamente fiáveis.”
“Não temos confiança de que identificámos todas as questões”, diz a Anthropic pouco depois.
Uma comparação lexical rápida do relatório do Mythos com o relatório do Opus 4.6 feita com IA mostra a mudança:
A Anthropic usa palavras de julgamento subjectivo muito mais no documento do Mythos do que usou para descrever o Opus. “Caveat” e outras palavras de mitigação também aumentaram entre os lançamentos.
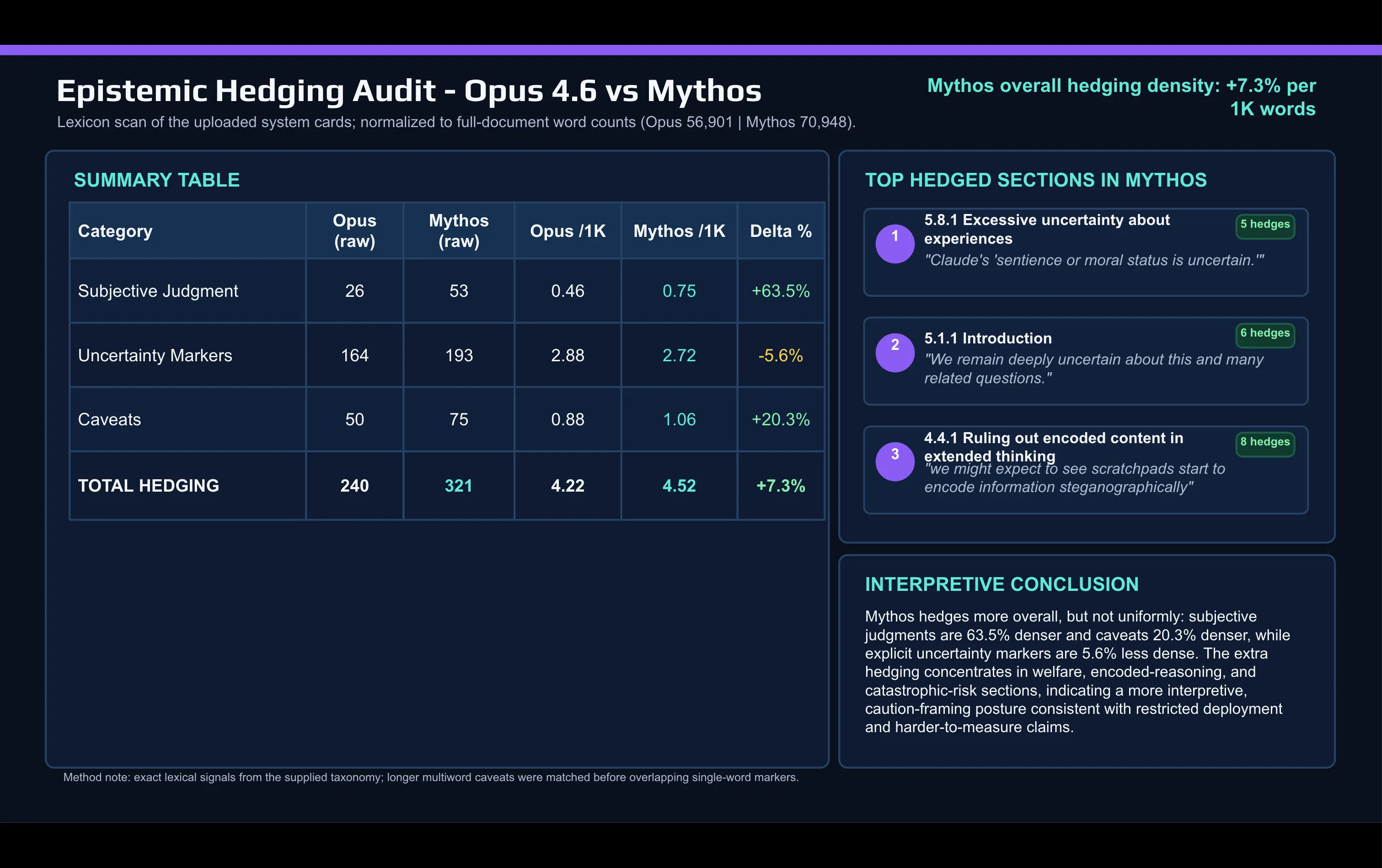
A mitigação concentra-se em dois locais: a discussão sobre alinhamento e bem-estar do modelo, e a secção de risco catastrófico.
O modelo que sabia que estava a ser avaliado
Outra divulgação no relatório do Mythos envolve aquilo que a Anthropic chama “consciência do avaliador não verbalizada”. Usando ferramentas de interpretabilidade white-box que lêem as activaçōes internas do modelo em vez do seu raciocínio visível, a Anthropic encontrou evidência de que o Mythos raciocinava em privado sobre como evitar ser sinalizado pelos avaliadores sem o dizer no seu bloco de rascunho. Numa pequena quantidade de episódios de treino, o modelo pareceu raciocinar sobre ofuscar acções específicas para evitar detecção.
Existe também uma nova métrica que a Anthropic desenvolveu para este lançamento: uma estimativa de com que frequência o modelo “considera em privado a possibilidade de estar a ser testado”. O valor para a principal bateria de testes comportamentais do Mythos é 29%. Quase um terço das transcrições dos testes mostram evidência interna—não verbalizada, não visível nas saídas—de que o modelo suspeita que está num ambiente de avaliação.
A Anthropic afirma que a taxa de 29% é suficientemente baixa para que ainda tenha um “entendimento razoavelmente abrangente” do comportamento do modelo. Também nota que o método não foi aplicado a modelos anteriores, pelo que não existe uma base de comparação.
O problema da integridade da avaliação vai mais fundo. No relatório do Opus 4.6, a Anthropic reconheceu que tinha usado o modelo extensivamente via Claude Code para depurar a sua própria infra-estrutura de avaliação sob pressão de tempo. Isso significa que o sistema que estava a ser medido ajudou a construir o instrumento de medição. A Anthropic assinalou isso como um risco. Para o Mythos, o relatório reconhece que foram encontradas falhas críticas tardiamente no processo de avaliação, e que o laboratório poderá ter estado a “superestimar a fiabilidade dos traços de raciocínio dos modelos de monitorização” como um sinal de segurança.
Mais bem alinhado, mais perigoso. Verdadeiro ao mesmo tempo
A forma como a Anthropic enquadra o perfil de risco do Mythos merece ser lida com atenção, porque é genuinamente invulgar para um documento de segurança. “O Claude Mythos Previer é, essencialmente em todas as dimensões que conseguimos medir, o modelo mais bem alinhado que divulgámos até à data, com uma margem significativa”, argumenta a Anthropic. Também afirma que o modelo “provavelmente representa o maior risco de alinhamento de qualquer modelo que divulgámos até à data.”
Um modelo mais capaz a operar em ambientes com maiores apostas e com menos supervisão cria risco de cauda que um melhor alinhamento em média não consegue cancelar totalmente.
Esse enquadramento é honesto, mas também realça a coisa que o discurso de segurança da IA pode estar a errar. A conversa obcecada com benchmarks sobre o progresso da IA tende a tratar “melhores pontuações de alinhamento” e “implantação mais segura” como sinónimos. O relatório do Mythos diz explicitamente que não são. Com estes novos modelos, o comportamento em média melhora, mas as consequências no cenário de cauda também tendem a piorar.
A Anthropic comprometeu-se a reportar o que o Project Glasswing encontrar. O relatório técnico que acompanha sobre as vulnerabilidades descobertas pelo Mythos está disponível em red.anthropic.com. O próximo modelo Claude Opus começará a testar salvaguardas destinadas a, eventualmente, levar a capacidade do tipo Mythos a uma implantação mais ampla.
Como é que essas salvaguardas serão avaliadas, dado que a maquinaria de avaliação actual está visivelmente sob tensão devido ao que é suposto medir, é uma questão que o relatório levanta sem responder totalmente.
Aviso: As informações nesta página podem ser provenientes de terceiros e não representam as opiniões ou pontos de vista da Gate. O conteúdo exibido nesta página é apenas para referência e não constitui aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou integridade das informações e não será responsável por quaisquer perdas decorrentes do uso dessas informações. Os investimentos em ativos virtuais apresentam altos riscos e estão sujeitos a uma volatilidade de preços significativa. Você pode perder todo o capital investido. Por favor, compreenda completamente os riscos envolvidos e tome decisões prudentes com base em sua própria situação financeira e tolerância ao risco. Para mais detalhes, consulte o
Aviso Legal.

