Acheter Cryptos
Payer en
USD
Acheter & Vendre
HOT
Achetez et vendez des cryptomonnaies via Apple Pay, cartes bancaires, Google Pay, virements bancaires et d'autres méthodes de paiement.
P2P
0 Fees
Zéro frais, +400 options de paiement et une expérience ultra fluide pour acheter et vendre vos cryptos
Carte Gate
Carte de paiement crypto, permettant d'effectuer des transactions mondiales en toute transparence.
Trader
Basique
Spot
Échangez des cryptos librement
Marge
Augmentez vos bénéfices grâce à l'effet de levier
Conversion & Trading en blocs
0 Fees
Tradez n’importe quel volume sans frais ni slippage
Tokens à effet de levier
Soyez facilement exposé à des positions à effet de levier
Pré-marché
Trade de nouveaux jetons avant qu'ils ne soient officiellement listés
Futures
Futures
Des centaines de contrats réglés en USDT ou en BTC
Options
HOT
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Trading démo
Lancement Futures
Préparez-vous à trader des contrats futurs
Événements futures
Participez à des événements pour gagner de généreuses récompenses
Trading démo
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
Earn
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
Launchpad
Soyez les premiers à participer au prochain grand projet de jetons
Points Alpha
NEW
Tradez des actifs on-chain et profitez des récompenses en airdrop !
Points Futures
NEW
Gagnez des points Futures et réclamez vos récompenses d’airdrop.
Investissement
Simple Earn
Gagner des intérêts avec des jetons inutilisés
Investissement automatique
Auto-invest régulier
Double investissement
Acheter à bas prix et vendre à prix élevé pour tirer profit des fluctuations de prix
Staking souple
Gagnez des récompenses grâce au staking flexible
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Gestion de patrimoine VIP
La gestion qui fait grandir votre richesse
Gestion privée de patrimoine
Gestion personnalisée des actifs pour accroître vos actifs numériques
Fonds Quant
Une équipe de gestion d'actifs de premier plan vous aide à réaliser des bénéfices en toute simplicité
Staking
Stakez des cryptos pour gagner avec les produits PoS.
Levier Smart
NEW
Pas de liquidation forcée avant l'échéance, des gains à effet de levier en toute sérénité
Mint de GUSD
Utilisez des USDT/USDC pour minter des GUSD et obtenir des rendements de niveau trésorerie
Plus
L'organisme de réglementation australien signale Grok dans la montée des plaintes pour abus d'images IA
Il y a 3h
Des hommes armés masqués ligotent une femme en France, volent une clé USB de crypto
Il y a 3h
Sujets populaires
Afficher plus18.99K Popularité
42.35K Popularité
12.23K Popularité
9.58K Popularité
38.49K Popularité
Hot Gate Fun
Afficher plus- MC:$4.3KDétenteurs:34.03%
- MC:$3.54KDétenteurs:10.00%
- 3

啥币
啥币
MC:$3.54KDétenteurs:10.00% - MC:$3.54KDétenteurs:10.00%
- MC:$3.61KDétenteurs:30.21%
Épingler
Les initiés affirment que DeepSeek V4 surpassera Claude et ChatGPT en programmation, lancement prévu dans quelques semaines
En bref
DeepSeek prévoit apparemment de lancer son modèle V4 vers la mi-février, et si les tests internes en sont une indication, les géants de l’IA de la Silicon Valley devraient être nerveux. La startup d’IA basée à Hangzhou pourrait viser une sortie autour du 17 février—le Nouvel An lunaire, naturellement—avec un modèle spécifiquement conçu pour les tâches de codage, selon The Information. Des personnes ayant une connaissance directe du projet affirment que V4 dépasse à la fois Claude d’Anthropic et la série GPT d’OpenAI dans des benchmarks internes, notamment lorsqu’il s’agit de gérer des prompts de code extrêmement longs. Bien sûr, aucun benchmark ni aucune information sur le modèle n’a été partagé publiquement, il est donc impossible de vérifier directement ces affirmations. DeepSeek n’a pas non plus confirmé les rumeurs.
Cependant, la communauté de développeurs n’attend pas de communiqué officiel. Reddit’s r/DeepSeek et r/LocalLLaMA s’animent déjà, les utilisateurs accumulent des crédits API, et les passionnés sur X ont rapidement partagé leurs prédictions selon lesquelles V4 pourrait consolider la position de DeepSeek comme le petit outsider déterminé à ne pas jouer selon les règles milliardaires de la Silicon Valley.
Ce ne serait pas la première disruption de DeepSeek. Lorsqu’il a lancé son modèle de raisonnement R1 en janvier 2025, cela a déclenché une vente massive de $1 trillions sur les marchés mondiaux. La raison ? Le R1 de DeepSeek égalait le modèle o1 d’OpenAI sur les benchmarks de mathématiques et de raisonnement, malgré un coût de développement rapporté à seulement $6 millions—environ 68 fois moins cher que ce que dépensaient les concurrents. Son modèle V3 a ensuite atteint 90,2 % sur le benchmark MATH-500, dépassant largement les 78,3 % de Claude, et la mise à jour récente “V3.2 Speciale” a encore amélioré ses performances.
Image : DeepSeek
L’objectif de codage de V4 représenterait une pivot stratégique. Alors que R1 mettait l’accent sur le raisonnement pur—logique, mathématiques, preuves formelles—V4 est un modèle hybride (raisonnement et tâches non-raisonnement) qui cible le marché des développeurs d’entreprise où une génération de code haute précision se traduit directement en revenus. Pour prétendre à la domination, V4 devrait battre Claude Opus 4.5, qui détient actuellement le record vérifié du SWE-bench à 80,9 %. Mais si l’on se fie aux lancements passés de DeepSeek, cela pourrait ne pas être impossible à réaliser, même avec toutes les contraintes auxquelles un laboratoire d’IA chinois serait confronté. La sauce pas si secrète Supposons que les rumeurs soient vraies, comment ce petit laboratoire pourrait-il réaliser un tel exploit ? L’arme secrète de l’entreprise pourrait se trouver dans son article de recherche du 1er janvier : Manifold-Constrained Hyper-Connections, ou mHC. Co-écrit par le fondateur Liang Wenfeng, cette nouvelle méthode d’entraînement aborde un problème fondamental dans la montée en puissance des grands modèles de langage—comment augmenter la capacité d’un modèle sans qu’il devienne instable ou n’explose lors de l’entraînement. Les architectures traditionnelles d’IA forcent toutes les informations à passer par une seule voie étroite. mHC élargit cette voie en plusieurs flux pouvant échanger des informations sans provoquer l’effondrement de l’entraînement.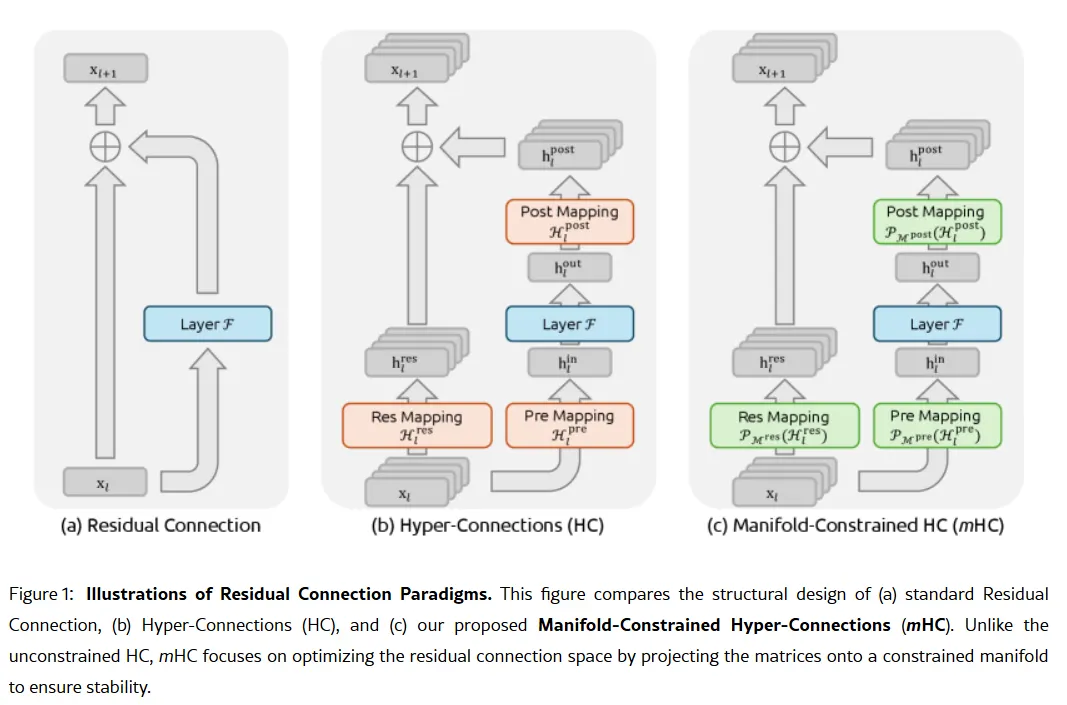
Image : DeepSeek
Wei Sun, analyste principal en IA chez Counterpoint Research, a qualifié mHC de “percée remarquable” dans des commentaires à Business Insider. La technique, a-t-elle dit, montre que DeepSeek peut “contourner les goulets d’étranglement de calcul et réaliser des progrès en intelligence,” même avec un accès limité aux puces avancées en raison des restrictions à l’exportation américaines. Lian Jye Su, analyste en chef chez Omdia, a noté que la volonté de DeepSeek de publier ses méthodes témoigne d’une “confiance nouvelle dans l’industrie chinoise de l’IA.” L’approche open-source de l’entreprise en a fait un favori parmi les développeurs qui la voient comme incarnant ce qu’OpenAI était avant de pivoter vers des modèles fermés et des levées de fonds de milliards de dollars.
Tout le monde n’est pas convaincu. Certains développeurs sur Reddit se plaignent que les modèles de raisonnement de DeepSeek gaspillent du calcul sur des tâches simples, tandis que des critiques soutiennent que les benchmarks de l’entreprise ne reflètent pas la complexité du monde réel. Un post Medium intitulé “DeepSeek Craint—Et J’en Ai Fini de Faire semblant que ça n’est pas” est devenu viral en avril 2025, accusant les modèles de produire du “nonsense standardisé avec des bugs” et des “bibliothèques hallucinnées.” DeepSeek porte aussi un bagage. Des préoccupations concernant la vie privée ont hanté l’entreprise, certains gouvernements interdisant l’application native de DeepSeek. Les liens de l’entreprise avec la Chine et les questions sur la censure dans ses modèles ajoutent une friction géopolitique aux débats techniques. Pourtant, l’élan est indéniable. DeepSeek a été largement adopté en Asie, et si V4 tient ses promesses en matière de codage, l’adoption en entreprise en Occident pourrait suivre.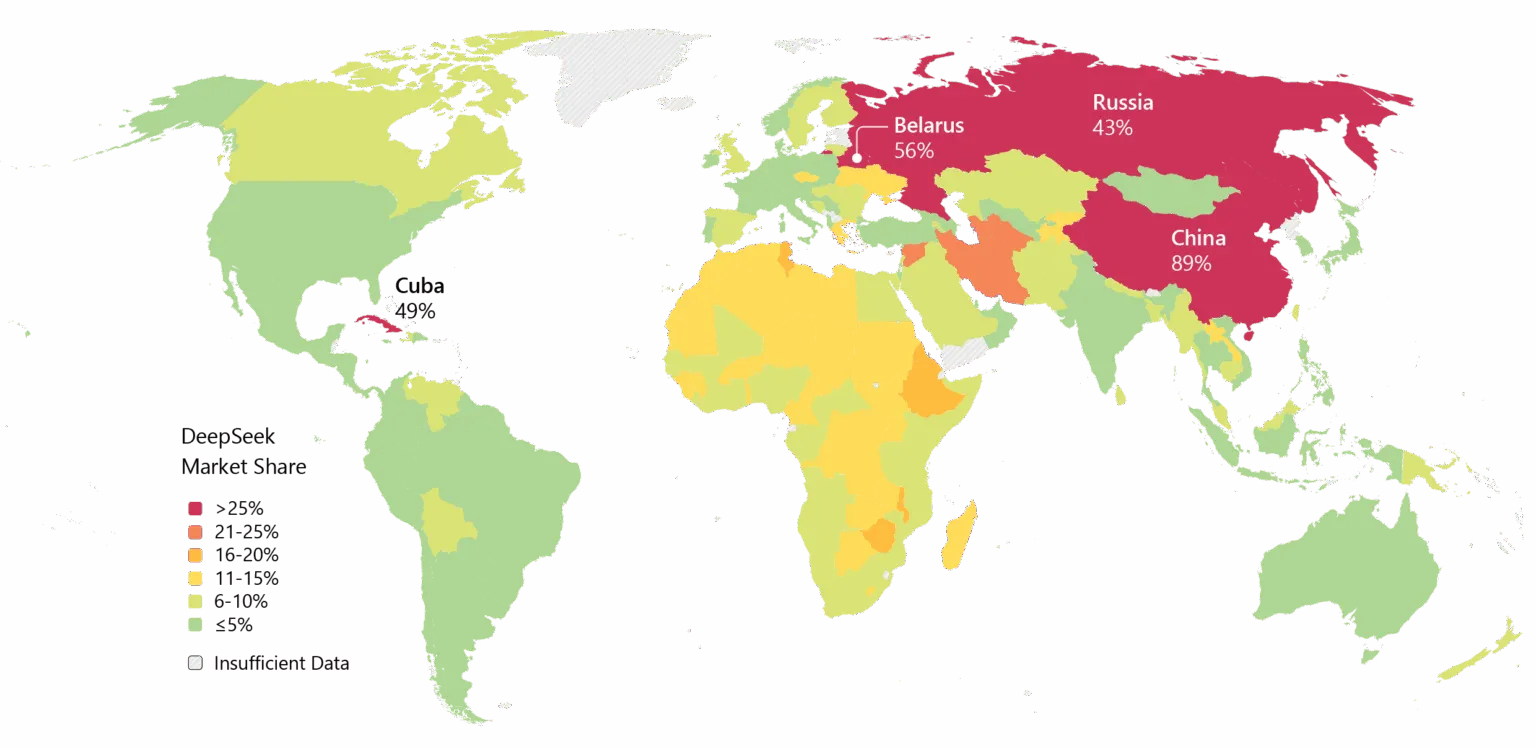
Image : Microsoft
Il y a aussi le timing. Selon Reuters, DeepSeek avait initialement prévu de lancer son modèle R2 en mai 2025, mais a prolongé la période après que le fondateur Liang soit devenu insatisfait de ses performances. Maintenant, avec V4 apparemment prévu pour février et R2 potentiellement en août, l’entreprise avance à un rythme qui suggère de l’urgence—ou de la confiance. Peut-être les deux.